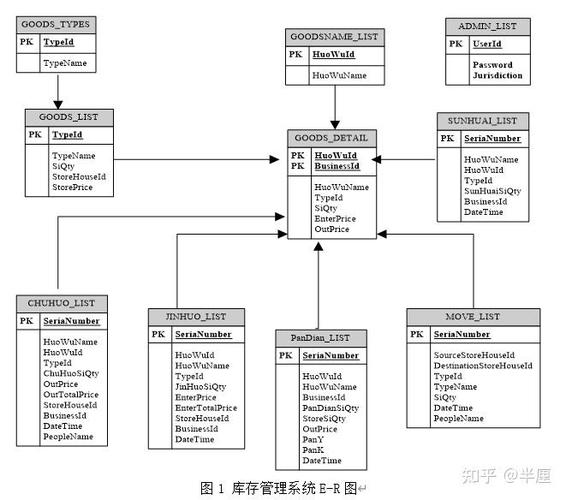
1. 数据收集:首先,需要收集相关数据。这可能包括从多个来源获取数据,如数据库、文件、日志、传感器等。
2. 数据存储:将收集到的数据存储在适当的地方,如数据库、数据仓库或大数据平台。
3. 数据预处理:在查询之前,通常需要对数据进行清洗、转换和集成,以消除错误、不完整或重复的数据。
4. 查询设计:设计查询语句或脚本,以从数据中提取所需的信息。这可能涉及到SQL查询、编程语言(如Python、R)或特定的大数据查询语言(如HiveQL、SparkSQL)。
5. 执行查询:在选定的数据存储或平台上执行查询,以获取结果。
6. 结果分析:对查询结果进行分析,以提取有价值的信息或洞察。
7. 结果呈现:将分析结果以图表、报告或其他形式呈现,以便于理解和沟通。
8. 迭代和优化:根据需要,对查询和数据分析过程进行迭代和优化,以提高效率和准确性。
在查询大数据时,可能还需要考虑数据的安全性和隐私性,确保只有授权的人员才能访问和使用数据。此外,还需要注意数据的质量和可靠性,以确保查询结果的准确性。
大数据查询的全面指南

随着信息技术的飞速发展,大数据已经成为各行各业不可或缺的一部分。如何高效地查询大数据,成为了许多企业和研究机构关注的焦点。本文将为您详细介绍大数据查询的方法和技巧。
一、大数据查询的基本概念
大数据查询是指从海量数据中快速、准确地找到所需信息的过程。大数据查询通常涉及以下几个关键概念:
数据源:数据查询的起点,可以是数据库、文件系统、分布式存储系统等。
数据模型:描述数据结构和组织方式的模型,如关系型数据库、NoSQL数据库、图数据库等。
查询语言:用于编写查询语句的语言,如SQL、NoSQL查询语言、MapReduce等。
查询优化:提高查询效率的技术和方法。
二、大数据查询的方法

根据数据源和查询需求,大数据查询可以采用以下几种方法:
1. 关系型数据库查询
关系型数据库是传统的大数据查询方式,通过SQL语言进行查询。关系型数据库查询的优点是语法简单、易于理解,但处理大规模数据时性能可能受限。
2. NoSQL数据库查询
NoSQL数据库适用于处理非结构化、半结构化数据,如文档、键值对、列族等。NoSQL数据库查询通常使用特定的查询语言,如MongoDB的MongoDB Query Language (MQL)、Cassandra的CQL等。
3. 分布式存储系统查询
分布式存储系统如Hadoop HDFS、Alluxio等,可以存储海量数据。查询分布式存储系统通常使用MapReduce、Spark等计算框架,通过编写相应的查询程序进行数据检索。
4. 图数据库查询
图数据库适用于处理复杂的关系数据,如社交网络、推荐系统等。图数据库查询通常使用图查询语言,如Gremlin、Cypher等。
三、大数据查询的优化技巧

合理设计数据模型:根据查询需求,选择合适的数据模型,如关系型、NoSQL、图数据库等。
索引优化:为常用查询字段建立索引,提高查询速度。
分区优化:将数据分区存储,提高查询并行度。
查询语句优化:优化查询语句,减少数据扫描量。
使用缓存:将常用查询结果缓存,减少重复查询。
四、大数据查询工具与平台
Apache Hive:基于Hadoop的SQL查询工具。
Apache Spark SQL:基于Spark的SQL查询工具。
Apache Impala:基于Hadoop的实时查询引擎。
Google BigQuery:基于Google Cloud Platform的云上大数据查询服务。
Amazon Redshift:基于AWS的云上大数据查询服务。
大数据查询是大数据应用的重要组成部分。掌握大数据查询的方法和技巧,有助于提高数据检索的效率,为企业和研究机构提供有力支持。本文从基本概念、查询方法、优化技巧和工具平台等方面,为您全面介绍了大数据查询的相关知识。