
当然可以,机器学习源码是一个广泛的领域,涵盖了许多不同的算法和模型。请问您具体需要哪方面的机器学习源码呢?例如,您可能对深度学习、自然语言处理、计算机视觉或强化学习感兴趣。
如果您能提供更多具体信息,我将能够为您提供更精确的帮助。同时,如果您对机器学习的基本概念和算法感兴趣,我可以为您推荐一些入门资源。
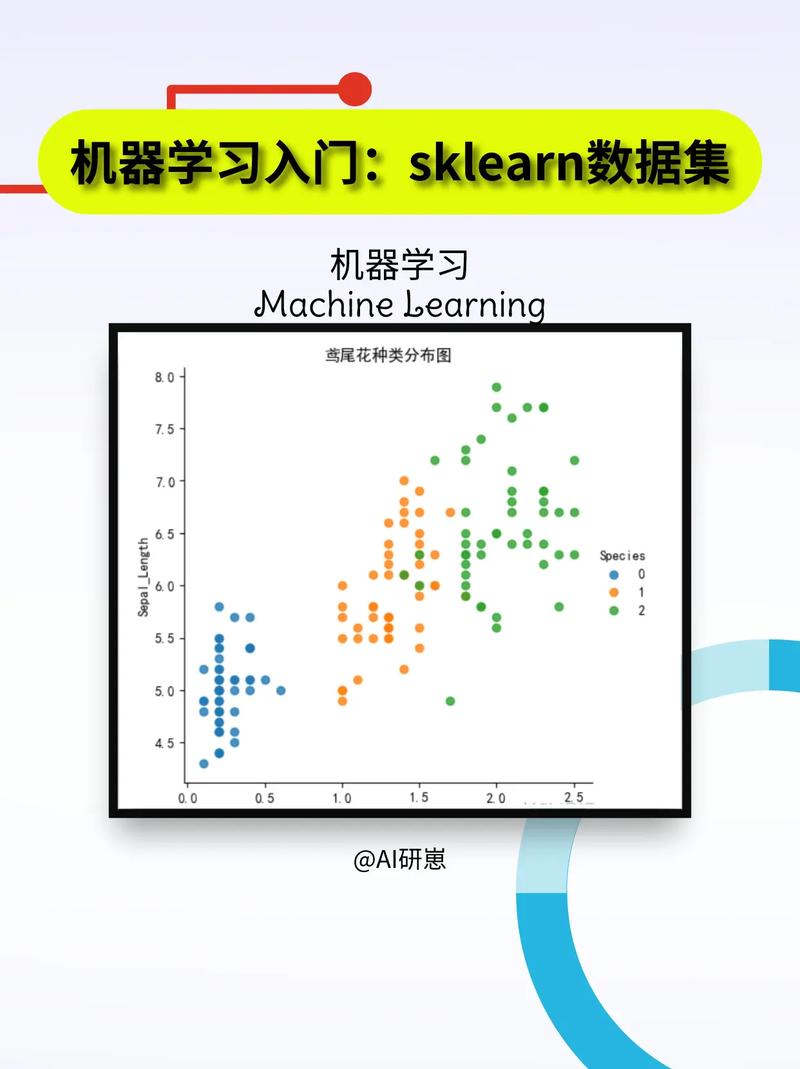
深入解析机器学习源码:从原理到实践
一、机器学习源码概述
机器学习源码通常包括以下几个部分:
数据预处理:对原始数据进行清洗、转换等操作,使其符合模型训练的要求。
模型构建:根据算法原理,构建相应的模型结构。
模型训练:使用训练数据对模型进行优化,提高模型的预测能力。
模型评估:使用测试数据对模型进行评估,检验模型的泛化能力。
模型部署:将训练好的模型部署到实际应用场景中。
二、数据预处理源码解析
数据预处理是机器学习源码中的基础部分,主要包括以下操作:
数据清洗:去除数据中的噪声、异常值等。
数据转换:将数据转换为适合模型训练的格式,如归一化、标准化等。
特征提取:从原始数据中提取有用的特征,提高模型的预测能力。
以下是一个简单的数据预处理源码示例(Python):
```python
import pandas as pd
from sklearn.preprocessing import StandardScaler
读取数据
data = pd.read_csv('data.csv')
数据清洗
data = data.dropna()
数据转换
scaler = StandardScaler()
data_scaled = scaler.fit_transform(data)
特征提取
features = data_scaled[:, :-1]
labels = data_scaled[:, -1]
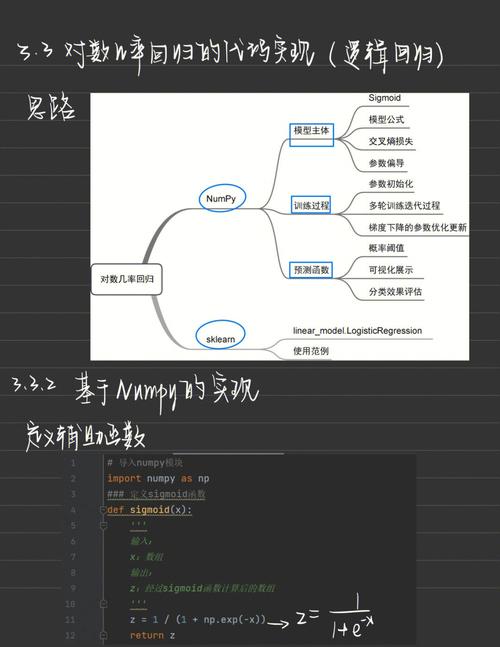
三、模型构建源码解析
模型构建是机器学习源码的核心部分,主要包括以下步骤:
选择合适的算法:根据实际问题选择合适的机器学习算法。
定义模型结构:根据算法原理,定义模型的结构。
初始化参数:为模型参数设置初始值。
以下是一个简单的线性回归模型构建源码示例(Python):
```python
import numpy as np
创建线性回归模型
初始化参数
四、模型训练源码解析
模型训练是机器学习源码中的关键部分,主要包括以下步骤:
选择合适的优化算法:根据算法原理选择合适的优化算法,如梯度下降、随机梯度下降等。
迭代优化:通过迭代优化算法,不断调整模型参数,提高模型的预测能力。
以下是一个简单的梯度下降算法训练源码示例(Python):
```python
def gradient_descent(features, labels, learning_rate, epochs):
weights = np.zeros(features.shape[1])
for epoch in range(epochs):
predictions = np.dot(features, weights)
errors = predictions - labels
weights -= learning_rate np.dot(errors, features)
return weights
训练模型
weights = gradient_descent(features, labels, learning_rate=0.01, epochs=1000)
五、模型评估源码解析
模型评估是机器学习源码中的关键部分,主要包括以下步骤:
选择合适的评估指标:根据实际问题选择合适的评估指标,如准确率、召回率、F1值等。
计算评估指标:使用测试数据计算评估指标,检验模型的泛化能力。
以下是一个简单的准确率计算源码示例(Python):
```python
def accuracy_score(y_true, y_pred):
return np.mean(y_true == y_pred)
计算准确率
print('Accuracy:', accuracy)
六、模型部署源码解析
模型部署是将训练好的模型应用到实际场景中的过程,主要包括以下步骤:
模型导出:将训练好的模型导出为可部署的格式,如ONNX、PMML等。
模型加载:将导出的模型加载到应用场景中。








