在Java中,有几种流行的爬虫框架可以帮助开发者高效地抓取网页数据。以下是几种常用的Java爬虫框架:
1. Jsoup:Jsoup是一个用于解析HTML文档的Java库。它提供了一个非常方便的API,可以让你轻松地提取和操作HTML元素。Jsoup可以解析HTML文档,使用CSS选择器来查找和提取数据,还可以操作HTML元素。它非常适合于那些需要从网页中提取特定信息的应用程序。
2. HtmlUnit:HtmlUnit是一个“无头”的浏览器,它允许你像用户一样浏览网页,而无需启动实际的浏览器。HtmlUnit可以模拟用户的操作,如点击链接、填写表单等,从而获取动态生成的网页内容。它非常适合于那些需要模拟用户行为的爬虫任务。
3. WebMagic:WebMagic是一个简单易用的Java爬虫框架。它提供了许多常用的爬虫功能,如URL管理、页面下载、页面解析、数据存储等。WebMagic还支持多线程和分布式爬虫,可以让你更高效地抓取大量数据。
4. Heritrix:Heritrix是一个强大的、可扩展的Web爬虫,它由互联网档案馆(Internet Archive)开发。Heritrix可以抓取整个网站或特定的网站部分,并支持多种存储格式。它非常适合于那些需要抓取大量网页数据的任务。
5. Selenium:虽然Selenium主要用于自动化测试,但它也可以用于爬虫。Selenium可以模拟用户的操作,如点击链接、填写表单等,从而获取动态生成的网页内容。它非常适合于那些需要模拟用户行为的爬虫任务。
6. Apache Nutch:Apache Nutch是一个高度可扩展、可配置的Web爬虫。它提供了许多高级功能,如URL过滤、内容提取、链接解析等。Apache Nutch还支持多种存储格式,并可以与其他工具集成。
7. Scrapy:虽然Scrapy是一个Python爬虫框架,但它也可以与Java集成。你可以使用Scrapy来编写爬虫逻辑,然后使用Java来处理爬取的数据。Scrapy提供了许多高级功能,如请求调度、数据清洗、数据存储等。
这些框架各有优缺点,你可以根据自己的需求选择合适的框架。
深入解析Java爬虫框架:技术选型与实战应用

一、Java爬虫框架概述
Java爬虫框架是指基于Java语言开发的爬虫工具,它可以帮助开发者快速构建爬虫程序,实现数据的抓取、解析和存储。常见的Java爬虫框架有Jsoup、HttpClient、Crawler4j、WebMagic等。
二、技术选型
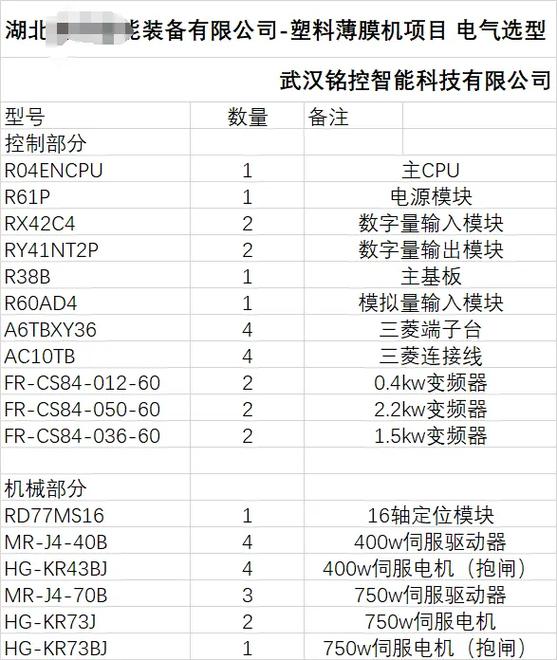
在选择Java爬虫框架时,需要考虑以下因素:
1. 简单易用
对于初学者来说,选择一个简单易用的框架可以降低学习成本,快速上手。Jsoup和WebMagic都是简单易用的框架,适合入门级开发者。
2. 功能丰富
一个功能丰富的框架可以满足各种爬虫需求。Jsoup、HttpClient和WebMagic都提供了丰富的API,支持多种数据解析、存储和爬虫管理功能。
3. 性能稳定
爬虫程序需要长时间运行,性能稳定是选择框架的重要指标。Crawler4j和WebMagic都支持多线程抓取,性能较为稳定。
4. 社区活跃
一个活跃的社区可以提供丰富的学习资源和解决方案。Jsoup、HttpClient和WebMagic都有较为活跃的社区,可以方便开发者解决问题。
三、实战应用

以下以Jsoup和WebMagic为例,介绍Java爬虫框架的实战应用。
1. Jsoup爬虫实战
Jsoup是一个基于DOM的HTML解析器,可以方便地提取网页中的数据。以下是一个简单的Jsoup爬虫示例:
```java
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class JsoupCrawler {
public static void main(String[] args) {
try {
// 获取网页内容
Document document = Jsoup.connect(\