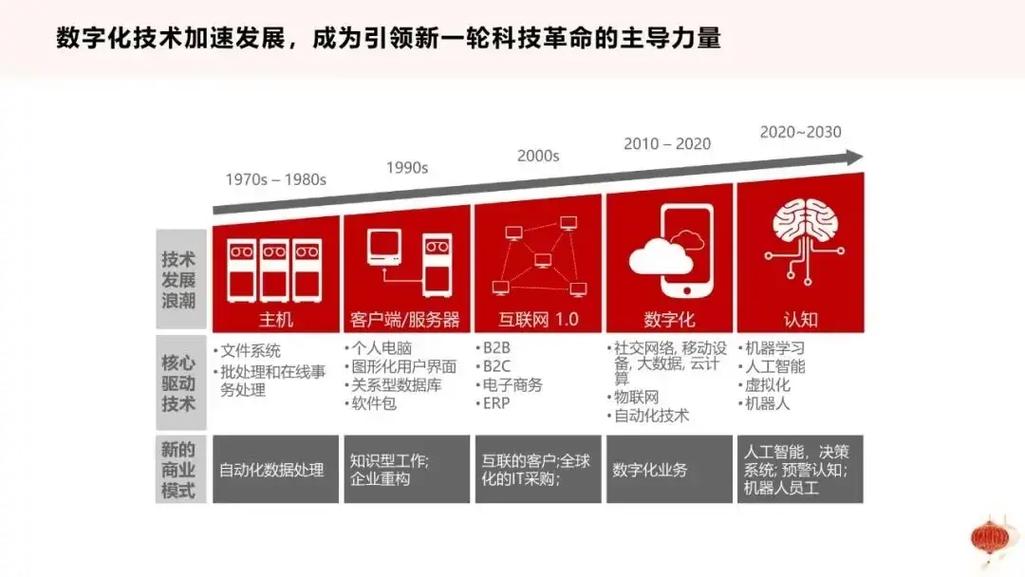
Faiss(Facebook AI Similarity Search)是由Facebook AI Research团队开发的开源库,主要用于快速、高效的向量数据库构建和相似性搜索。以下是Faiss中常用的三种索引方式及其特点:
1. IndexFlatL2: 特点:使用欧氏距离(L2)进行精确检索,适用于较小规模的数据集。 工作原理:采用暴力检索的方式,即计算查询向量与所有数据库向量之间的距离,然后返回相似度最高的前k个向量。 适用
FAISS向量数据库索引:高效相似性搜索的利器
随着大数据时代的到来,向量数据库在各个领域得到了广泛应用。FAISS(Facebook AI Similarity Search)作为一款高效的向量数据库索引工具,在相似性搜索和向量聚类方面表现出色。本文将详细介绍FAISS的原理、特点以及在实际应用中的优势。
一、FAISS简介
FAISS是由Facebook AI Research开发的一款开源库,主要用于高效相似性搜索和密集向量聚类。它支持多种索引结构,如HNSW(Hierarchical Navigable Small World)、IVF(Inverted Indexed Vector File)和PQ(Product Quantization)等,能够满足不同场景下的需求。
二、FAISS的原理
FAISS的核心思想是将高维向量映射到低维空间,并通过索引结构实现快速检索。以下是FAISS的几个关键原理:
1. 向量索引
FAISS使用多种索引类型来存储向量,以便进行快速的检索。主要包括以下两种:
扁平索引(Flat Index):将所有向量存储在一个大数组中,搜索时通过计算查询向量与数据库中每一个向量之间的距离来找到最近邻。
量化索引(Quantized Index):使用向量量化来减少存储需求和提高搜索效率。常用的量化技术包括标量量化(Scalar Quantization, SQ)和乘积量化(Product Quantization, PQ)。
2. 倒排索引(Inverted Index)
对于大规模向量数据库,倒排索引是一种常用的索引结构。它将每个向量映射到一个或多个索引项,从而实现快速检索。
三、FAISS的特点
FAISS具有以下特点:
高效性:FAISS支持多种索引结构,能够满足不同场景下的需求,实现快速检索。
可扩展性:FAISS支持分布式存储,能够处理大规模向量数据库。
灵活性:FAISS支持多种量化技术,可以根据实际需求选择合适的量化方法。
开源:FAISS是开源项目,用户可以自由使用和修改。
四、FAISS的应用场景
FAISS在以下场景中具有广泛的应用:
图像检索:通过将图像特征向量存储在FAISS中,可以快速检索与查询图像最相似的图像。
推荐系统:在推荐系统中,FAISS可以用于检索与用户兴趣最相似的物品。
自然语言处理:在自然语言处理领域,FAISS可以用于检索与查询文本最相似的其他文本。
其他领域:FAISS还可以应用于语音识别、生物信息学等领域。
FAISS是一款高效的向量数据库索引工具,在相似性搜索和向量聚类方面表现出色。它具有高效性、可扩展性、灵活性和开源等特点,适用于各种场景。随着大数据时代的到来,FAISS将在更多领域发挥重要作用。