Apache Storm是一个由Twitter开源的分布式实时大数据处理框架,被誉为实时版的Hadoop。以下是关于Storm的一些关键概念、原理和应用场n2. 组件: Spout:数据源,负责从外部系统(如消息队列、数据库等)读取数据。 Bolt:数据处理单元,用于处理接收到的数据并输出结果。 Tuple:Storm的基本数据结构,一个由多个字段组成的序列。3. Topology:Storm的计算逻辑结构,由多个组件(Spout和Bolt)组成。4. Nimbus:主节点,负责分配任务和监控工作节点。5. Supervisor:工作节点,负责启动和监控工作线程。
特点1. 简单的编程模型:类似于MapReduce,降低了实时处理的复杂性。2. 语言无关:支持多种编程语言,如Clojure、Java、Ruby和Python。3. 容错性:如果在消息处理过程中出现异常,Storm会重新调度出问题的处理逻辑。4. 可伸缩性:Storm集群可以方便地扩展到数千个节点。
应用场n2. 实时数据监控:用于网站监控、用户行为分析等场n3. 实时ETL流程:从多个数据源抽取数据,进行清洗和转换,然后实时加载到数据仓库或数据库中。4. 在线机器学习:进行实时模型训练和预测。5. 连续计算:处理连续的数据流,如实时计算广告点击率和转化率。6. 分布式RPC:作为一个通用的分布式RPC框架来使用。
通过这些信息,可以看出Storm在实时大数据处理领域具有广泛的应用和强大的处理能力。如果你有具体的需求或问题,可以进一步探索相关的技术文档和实例。
Apache Storm:实时大数据处理的强大工具
Apache Storm 是一个开源的分布式实时计算系统,专为处理大规模数据流而设计。它提供了高吞吐量、容错性和可伸缩性,使得开发者能够轻松构建复杂的数据处理管道。本文将深入探讨 Apache Storm 的核心概念、工作原理以及其在实时大数据处理中的应用。
一、Apache Storm 的核心概念
Apache Storm 的核心概念包括 Topology、Spout、Bolt 和 Tuple。
1. Topology

Topology 是 Storm 中的实时计算任务逻辑结构,可以看作是一个由 Spout 和 Bolt 组成的有向无环图(DAG)。它定义了数据流在系统中的处理流程,包括数据源、数据处理节点以及数据流向。
3. Spout

Spout 是数据流的起点,负责从外部数据源(如 Kafka、MQTT 等)拉取数据并发射到 Topology 中。每个 Spout 需要实现 IRichSpout 接口,定义数据的获取逻辑和故障恢复机制。
4. Bolt

Bolt 是 Storm 的基本处理单元,负责数据的转换和处理。它可以执行过滤、聚合、函数运算、写入数据库等多种操作。Bolt 可以连接形成复杂的处理链,每个 Bolt 可以消费一个或多个 Bolt 或 Spout 发出的数据流。
5. Tuple

Tuple 是 Storm 中的数据单元,它包含了数据流中的数据项。在 Topology 中,Tuple 会沿着 Bolt 之间的连接(Stream)流动,并在每个 Bolt 中进行处理。
二、Apache Storm 的工作原理
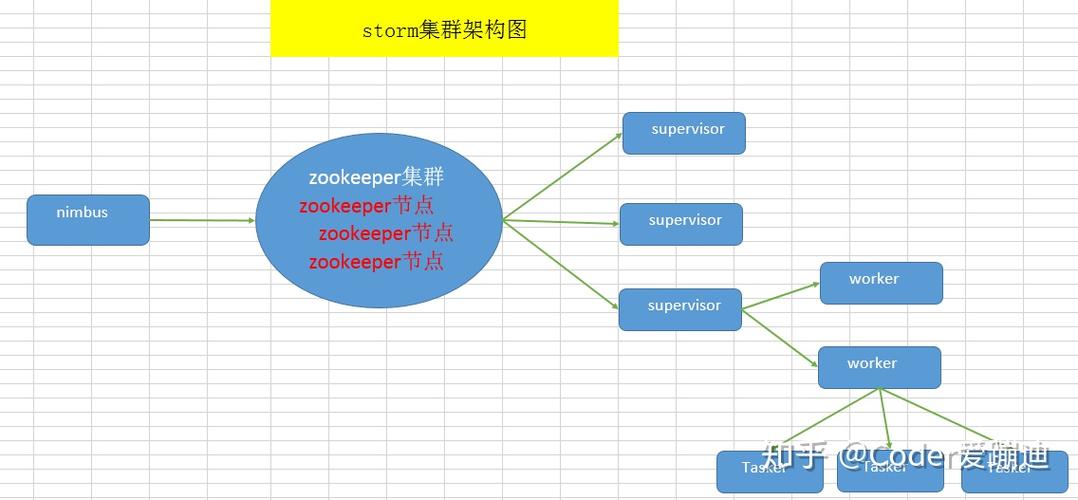
Apache Storm 的工作原理主要涉及以下几个方面:
1. 分布式计算
Apache Storm 通过分布式计算,将数据流处理任务分配到多个节点上并行执行,从而提高处理速度和吞吐量。
2. 容错性

Apache Storm 具有强大的容错性,能够在节点故障的情况下自动恢复。当某个节点发生故障时,Storm 会自动将该节点的任务分配到其他节点上继续执行,确保数据处理任务的连续性。
3. 可伸缩性

Apache Storm 支持水平扩展,可以通过增加节点数量来提高系统的处理能力。这使得 Storm 能够适应不断增长的数据流处理需求。
三、Apache Storm 在实时大数据处理中的应用
1. 实时日志分析
Apache Storm 可以实时处理和分析日志数据,帮助开发者快速定位问题、优化系统性能。
2. 实时推荐系统
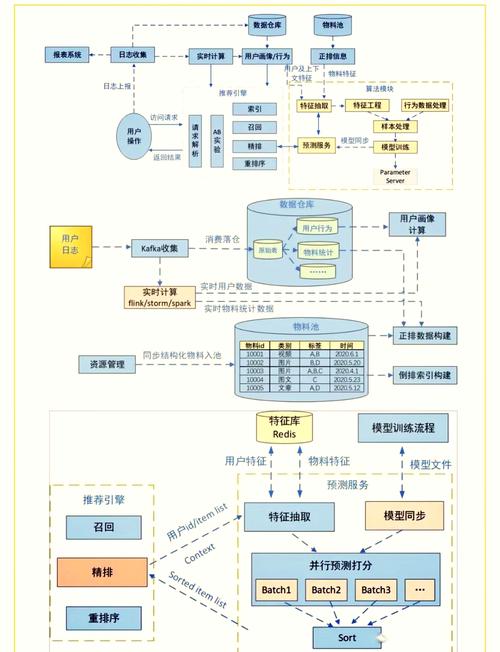
Apache Storm 可以实时处理用户行为数据,为用户提供个性化的推荐服务。
3. 实时监控

Apache Storm 可以实时监控系统性能指标,及时发现异常情况并采取措施。
4. 实时广告投放

Apache Storm 可以实时分析用户行为数据,为广告投放提供精准的数据支持。
Apache Storm 是一个功能强大的实时大数据处理工具,具有高吞吐量、容错性和可伸缩性等特点。通过本文的介绍,相信读者对 Apache Storm 的核心概念、工作原理以及应用场景有了更深入的了解。在实际应用中,Apache Storm 可以帮助开发者轻松构建实时数据处理系统,提高数据处理效率。