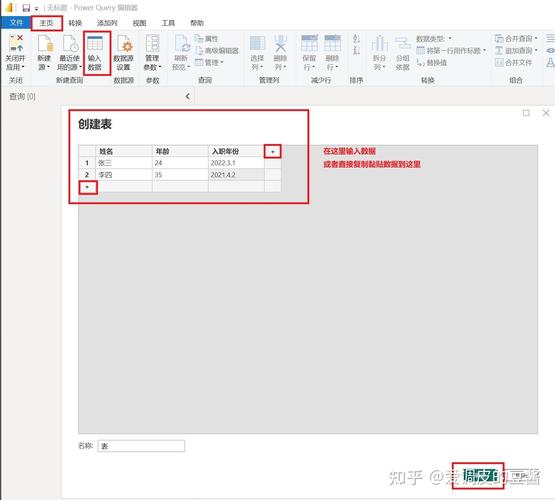
大数据预处理是大数据分析中的关键步骤,其目的是提高数据质量,确保后续分析的有效性和准确性。常见的预处理方法包括:
1. 数据清洗:包括去除或纠正错误、缺失、重复的数据。这可以通过数据验证、替换、删除或填充空值来实现。2. 数据集成:将来自多个源的数据合并到一个统一的数据集中。这可能涉及到数据格式的转换、字段名的统一等。3. 数据转换:将数据从一种格式转换为另一种格式,以便更好地进行分析。这可能包括数据类型的转换、单位转换、日期时间的转换等。4. 数据归一化:将数据缩放到一个特定的范围,以便于比较和分析。常见的归一化方法包括最小最大归一化、Zscore归一化等。5. 数据离散化:将连续的数据值划分为离散的类别。这有助于简化数据,并提高某些算法的性能。6. 数据特征选择:从原始数据中选择出对分析任务最有用的特征。这有助于减少数据维度,提高分析效率。7. 数据抽样:从大数据集中抽取一个具有代表性的子集进行分析。这有助于降低分析成本,同时保持分析结果的准确性。
以上是大数据预处理的一些常见方法,具体的预处理步骤和方法需要根据具体的数据和分析任务来确定。
大数据预处理概述

在大数据时代,数据预处理是数据分析流程中的关键步骤。它涉及对原始数据进行清洗、转换和整合,以确保数据的质量和可用性。有效的预处理可以显著提高后续分析模型的准确性和效率。
1. 缺失值处理

缺失值是数据集中常见的问题。处理缺失值的方法包括:
删除含有缺失值的记录
使用均值、中位数或众数填充缺失值
使用模型预测缺失值
2. 异常值处理

异常值可能会对分析结果产生不良影响。异常值处理方法包括:
删除异常值
对异常值进行修正
使用聚类算法识别异常值
3. 数据重复处理
数据重复会导致分析结果偏差。处理数据重复的方法包括:
删除重复记录
合并重复记录
4. 数据类型转换
数据类型转换是将数据从一种格式转换为另一种格式的过程。常见的数据类型转换包括:
将字符串转换为数值类型
将日期时间字符串转换为日期时间对象
将分类数据转换为数值编码
5. 数据归一化
数据归一化是将数据缩放到一个特定的范围,如[0,1]或[-1,1]。常见的数据归一化方法包括:
最小-最大归一化
Z-score标准化
6. 数据合并
数据合并是将来自不同来源的数据集合并成一个数据集的过程。常见的数据合并方法包括:
内连接
外连接
左连接
右连接
7. 数据去重
数据去重是删除重复数据的过程,以确保数据集的唯一性。
8. 常用数据预处理工具
Pandas:Python中的数据处理库
NumPy:Python中的数值计算库
Spark:基于Scala的大数据处理框架
Hadoop:分布式文件系统
ETL工具:如Talend、Informatica等
9. 数据预处理最佳实践
在预处理之前,明确分析目标
了解数据来源和结构
使用可视化工具分析数据分布
记录预处理步骤和结果
定期检查数据质量
大数据预处理是确保数据质量、提高分析效率的关键步骤。通过了解和掌握数据清洗、转换和整合的方法,可以更好地应对大数据时代的挑战。