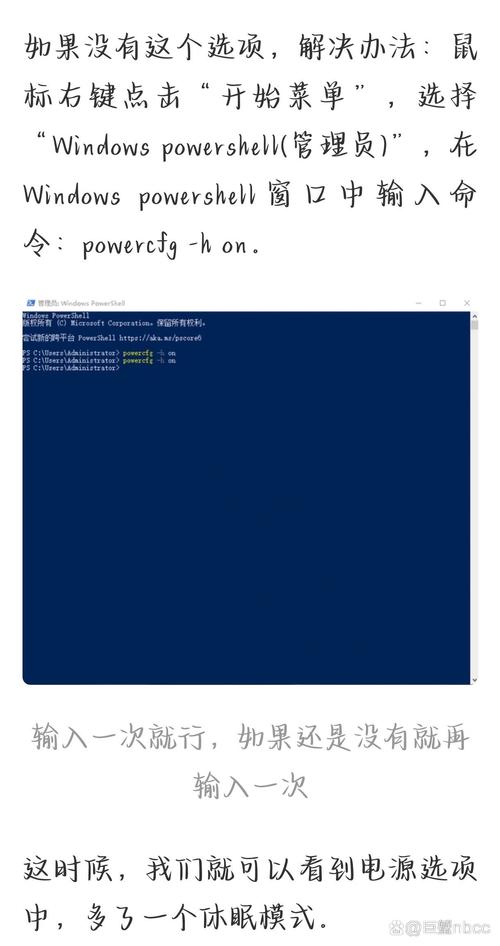
1. Kaldi:Kaldi是一个开源的语音识别工具箱,它包含了一系列用于语音识别的算法和工具。Kaldi支持多种语言,并且被广泛用于研究和开发中。
2. CMU Sphinx:CMU Sphinx是一个开源的语音识别系统,它基于隐马尔可夫模型(HMM)和声学模型。Sphinx在学术界和工业界都有广泛的应用。
3. pocketsphinx :Pocketsphinx是一个轻量级的语音识别库,它是CMU Sphinx的一部分。Pocketsphinx适用于资源受限的环境,如移动设备和嵌入式系统。
4. DeepSpeech:DeepSpeech是一个基于深度学习的语音识别系统,它由Mozilla开发。DeepSpeech使用神经网络来转换音频为文本。
5. Google SpeechtoText API:虽然不是直接在Linux上运行的,但你可以通过Google Cloud Platform使用Google的语音识别服务。Google SpeechtoText API支持多种语言和方言,并且提供高精度的识别结果。
6. Snips:Snips是一个开源的语音识别平台,它专注于隐私和安全性。Snips可以在本地运行,不需要将数据发送到云端。
7. Julius:Julius是一个高性能的语音识别引擎,它支持多种语言和方言。Julius使用HMM和神经网络进行语音识别。
8. TensorFlow:如果你对深度学习感兴趣,可以使用TensorFlow来构建自己的语音识别模型。TensorFlow是一个开源的机器学习库,它支持多种操作系统,包括Linux。
9. PyTorch:PyTorch是另一个流行的机器学习库,它也支持语音识别。PyTorch提供了一个动态的计算图,使得构建和训练语音识别模型变得更加容易。
10. espeak:虽然不是语音识别工具,但espeak是一个文本到语音的转换器,它可以将文本转换为语音。espeak支持多种语言和方言。
选择哪种工具取决于你的具体需求和场景。如果你是研究人员,可能更倾向于使用Kaldi或CMU Sphinx;如果你需要快速部署一个语音识别系统,可能会选择Pocketsphinx或DeepSpeech。如果你对深度学习感兴趣,可以考虑使用TensorFlow或PyTorch。
Linux系统下的语音识别技术与应用
二、Linux语音识别技术概述

Linux语音识别技术主要包括以下几个部分:
语音采集:通过麦克风等设备采集语音信号。
语音预处理:对采集到的语音信号进行降噪、分帧、特征提取等处理。
语音识别:将预处理后的语音信号与训练好的模型进行匹配,识别出对应的文字或命令。
语音合成:将识别出的文字或命令转换为语音输出。
三、Linux语音识别技术实现

Linux语音识别技术的实现主要依赖于以下几种工具和库:
libasound:提供音频设备访问的API。
libesd:提供音频设备访问的API。
libpulse:提供音频设备访问的API。
libsrtp:提供实时传输协议(RTP)的加密和完整性保护。
libvoip:提供VoIP通信的API。
四、Linux语音识别应用案例

智能家居:通过语音识别技术,用户可以实现对家电的远程控制,如开关灯、调节空调温度等。
服务机器人:语音识别技术可以帮助机器人理解用户的指令,实现导航、清洁、搬运等任务。
语音助手:如Google Assistant、Amazon Alexa等,用户可以通过语音与助手进行交互,获取信息、执行任务等。
语音翻译:通过语音识别技术,可以实现实时语音翻译,方便不同语言的用户进行沟通。
五、Linux语音识别技术发展趋势
模型轻量化:为了适应移动设备和嵌入式设备,语音识别模型将朝着轻量化的方向发展。
实时性提升:随着算法的优化和硬件性能的提升,语音识别的实时性将得到进一步提高。
多语言支持:随着全球化的推进,语音识别技术将支持更多语言,满足不同地区用户的需求。
个性化定制:根据用户的需求,语音识别技术将提供更加个性化的服务。