
向量数据库结构原理主要是基于向量模型和相似性搜索。向量模型通常用于表示数据点,而相似性搜索则用于找到与查询向量最相似的数据点。以下是向量数据库结构原理的简要概述:
1. 向量模型:向量模型是一种用于表示数据点的方法,其中每个数据点都被表示为一个向量。向量通常由一系列数字组成,这些数字可以是实数、整数或浮点数。向量模型可以用于表示各种类型的数据,包括文本、图像、音频和视频等。
2. 相似性搜索:相似性搜索是一种用于找到与查询向量最相似的数据点的方法。相似性搜索通常使用距离度量,如欧几里得距离、余弦相似度或Jaccard相似度等。相似性搜索的目的是找到与查询向量最相似的数据点,以便可以对其进行进一步的分析或处理。
3. 索引:向量数据库通常使用索引来加速相似性搜索。索引是一种数据结构,它允许快速检索与查询向量最相似的数据点。索引可以使用各种算法构建,如倒排索引、哈希索引或树形索引等。
4. 向量空间模型:向量空间模型是一种用于表示文本数据的方法,其中每个文档都被表示为一个向量。向量空间模型通常使用TFIDF(词频逆文档频率)算法来计算文档的向量表示。向量空间模型可以用于各种文本分析任务,如文本分类、聚类和推荐等。
5. 向量数据库应用:向量数据库可以用于各种应用,如推荐系统、图像搜索、语音识别和自然语言处理等。向量数据库的主要优势在于其高效性,可以快速检索与查询向量最相似的数据点。
总的来说,向量数据库结构原理主要基于向量模型和相似性搜索,通过使用索引和向量空间模型等技术,实现高效的数据检索和分析。
向量数据库结构原理详解
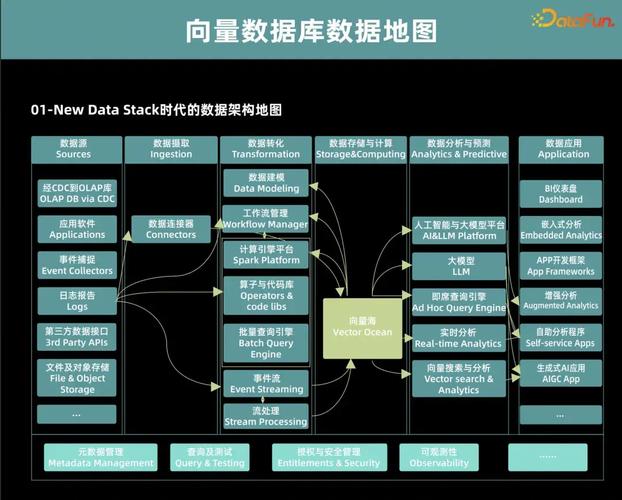
随着大数据和人工智能技术的快速发展,向量数据库作为一种新型的数据库技术,逐渐受到广泛关注。本文将详细介绍向量数据库的结构原理,帮助读者更好地理解这一技术。
一、什么是向量数据库

向量数据库是一种专门用于存储和检索高维向量数据的数据库。与传统的关系型数据库不同,向量数据库以向量作为数据的基本存储单位,通过向量之间的相似度来检索数据。这种数据库特别适用于图像识别、语音识别、自然语言处理等领域。
二、向量数据库的结构

向量数据库的结构主要包括以下几个方面:
1. 向量存储
向量存储是向量数据库的核心部分,它负责存储和管理向量数据。向量存储通常采用以下几种方式:
稀疏存储:只存储非零元素,节省存储空间。
密集存储:存储所有元素,便于计算。
分块存储:将向量数据分成多个块,便于并行处理。
2. 向量索引
向量索引是向量数据库的关键技术,它负责提高向量检索的效率。常见的向量索引技术包括:
倒排索引:将向量数据与对应的索引项进行映射,便于快速检索。
哈希索引:通过哈希函数将向量映射到索引项,提高检索速度。
树索引:利用树结构对向量进行组织,便于快速检索。
3. 搜索算法
搜索算法是向量数据库的核心功能,它负责根据用户查询找到最相似的数据。常见的搜索算法包括:
最近邻搜索:找到与查询向量最相似的向量。
相似度搜索:找到与查询向量相似度最高的向量。
三、向量数据库的工作原理
向量数据库的工作原理可以概括为以下几个步骤:
1. 数据存储
首先,将向量数据存储到向量数据库中。在存储过程中,数据库会对向量进行预处理,如归一化、去噪等。
2. 索引构建
根据向量数据的特点,选择合适的索引技术对向量进行索引。索引构建过程会消耗一定的时间和空间,但可以显著提高检索效率。
3. 查询处理
当用户进行查询时,向量数据库会根据查询内容,利用搜索算法在索引中找到最相似的数据。查询处理过程会根据索引类型和搜索算法的不同而有所差异。
4. 结果返回
向量数据库将查询结果返回给用户。用户可以根据需要,对查询结果进行进一步的处理和分析。
四、向量数据库的优势
向量数据库具有以下优势:
高效:向量数据库通过索引和搜索算法,可以快速检索到最相似的数据。
可扩展:向量数据库可以轻松地处理大规模数据集。
灵活:向量数据库支持多种索引和搜索算法,可以根据实际需求进行选择。
向量数据库作为一种新型的数据库技术,在图像识别、语音识别、自然语言处理等领域具有广泛的应用前景。本文详细介绍了向量数据库的结构原理,希望对读者有所帮助。








