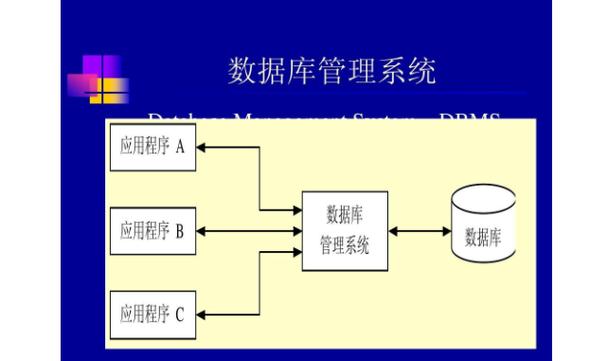
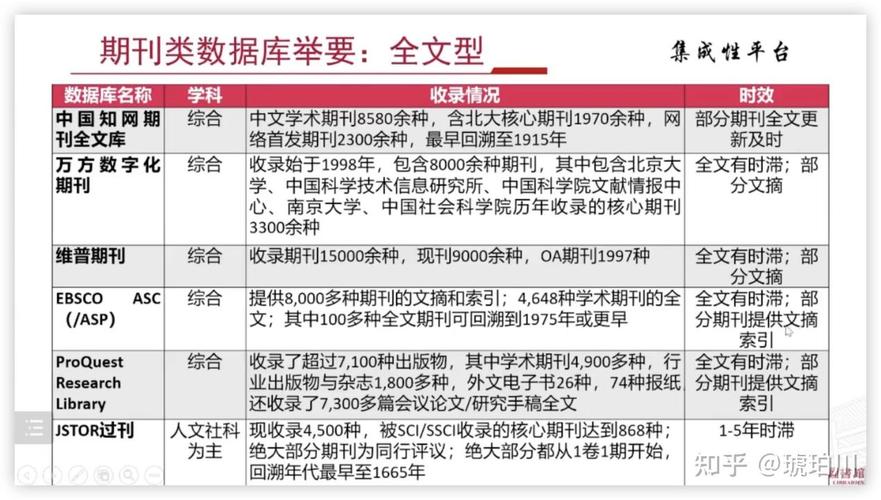
大数据技术是一个涵盖广泛的概念,主要包含以下几个关键领域:
1. 数据采集:从各种来源收集数据,如社交网络、物联网设备、企业数据库等。
2. 数据存储:大数据需要高效、可扩展的存储解决方案,如分布式文件系统(如Hadoop的HDFS)。
3. 数据处理:包括批处理和实时处理技术,如MapReduce、Spark等。
4. 数据管理:涉及数据集成、数据质量、数据治理等方面,确保数据的准确性、一致性和可用性。
5. 数据分析:使用统计方法、机器学习算法和人工智能技术来发现数据中的模式和洞察。
6. 数据可视化:将分析结果以图形化的方式展示,帮助用户更好地理解和解释数据。
7. 数据安全与隐私:保护数据免受未经授权的访问、泄露或滥用,同时遵守相关法律法规。
8. 云计算:利用云计算资源提供弹性、可扩展的大数据处理能力。
9. 物联网(IoT):将大数据与物联网设备结合,实现数据的实时采集、分析和应用。
10. 人工智能与机器学习:利用大数据训练机器学习模型,实现自动化决策和智能应用。
11. 数据挖掘:从大量数据中提取有价值的信息和知识。
12. 数据仓库与数据湖:数据仓库用于存储结构化数据,数据湖则支持存储各种类型的数据。
这些技术共同构成了大数据生态系统,支持从数据采集、存储、处理到分析、可视化、应用的全过程。随着技术的发展,大数据技术也在不断演进和融合,如与云计算、人工智能等领域的结合,为各行各业带来更多创新和机遇。
大数据技术概述
数据存储技术
Hadoop HDFS:Hadoop分布式文件系统(HDFS)是Hadoop生态系统中的核心组件,用于存储大规模数据集。它具有高吞吐量、高可靠性、高可用性等特点。
Amazon S3:Amazon Simple Storage Service(S3)是Amazon Web Services(AWS)提供的一种对象存储服务,适用于存储和检索大量数据。
Google Cloud Storage:Google Cloud Storage是Google Cloud Platform(GCP)提供的一种对象存储服务,适用于存储和检索大量数据。
Alibaba Cloud OSS:阿里云对象存储服务(OSS)是一种高可靠、低成本、可扩展的对象存储服务,适用于存储和检索大量数据。
数据处理与分析技术

Hadoop MapReduce:Hadoop MapReduce是一种编程模型,用于大规模数据集的并行运算。它将计算任务分解为多个小任务,并行执行,最后合并结果。
Spark:Apache Spark是一个开源的分布式计算系统,用于大规模数据处理。它具有速度快、易用性高、通用性强等特点。
Flink:Apache Flink是一个流处理框架,用于实时数据处理。它具有高吞吐量、低延迟、容错性强等特点。
SQL on Hadoop:SQL on Hadoop是一种在Hadoop平台上运行SQL查询的技术,如Apache Hive和Impala。
人工智能与机器学习技术
深度学习:深度学习是一种模拟人脑神经网络结构的学习方法,用于处理复杂的数据模式。
机器学习:机器学习是一种使计算机系统能够从数据中学习并做出决策的技术。
自然语言处理:自然语言处理是一种使计算机能够理解和处理人类语言的技术。
计算机视觉:计算机视觉是一种使计算机能够理解和解释图像和视频的技术。
大数据应用场景
金融行业:大数据技术可以帮助金融机构进行风险评估、欺诈检测、客户关系管理等。
医疗行业:大数据技术可以帮助医疗机构进行疾病预测、患者管理、药物研发等。
零售行业:大数据技术可以帮助零售商进行需求预测、库存管理、精准营销等。
交通行业:大数据技术可以帮助交通管理部门进行交通流量预测、道路规划、事故预警等。
大数据技术是当今社会的重要技术之一,它为各个行业提供了强大的数据支持。随着技术的不断发展,大数据技术将在未来发挥更加重要的作用。