
机器学习算法八股是指将机器学习算法的原理和应用以固定的格式进行阐述,这种格式通常包括算法的背景、原理、应用场景、优缺点等方面。这种八股式的阐述方式可以帮助人们快速了解机器学习算法的基本情况,但在实际应用中,需要根据具体问题选择合适的算法,并进行相应的调整和优化。
1. 决策树:决策树是一种常用的分类和回归算法,通过构建一棵树形结构来对数据进行分类或回归预测。决策树的优点是易于理解和实现,但容易过拟合,需要进行剪枝等处理。
2. 支持向量机(SVM):SVM是一种用于二分类问题的算法,通过寻找一个超平面来将不同类别的数据分开。SVM的优点是能够处理高维数据,对噪声和异常值不敏感,但需要选择合适的核函数和参数。
3. 随机森林:随机森林是一种集成学习算法,通过构建多棵决策树并进行投票来提高分类或回归的准确性。随机森林的优点是能够处理高维数据,对噪声和异常值不敏感,但计算复杂度较高。
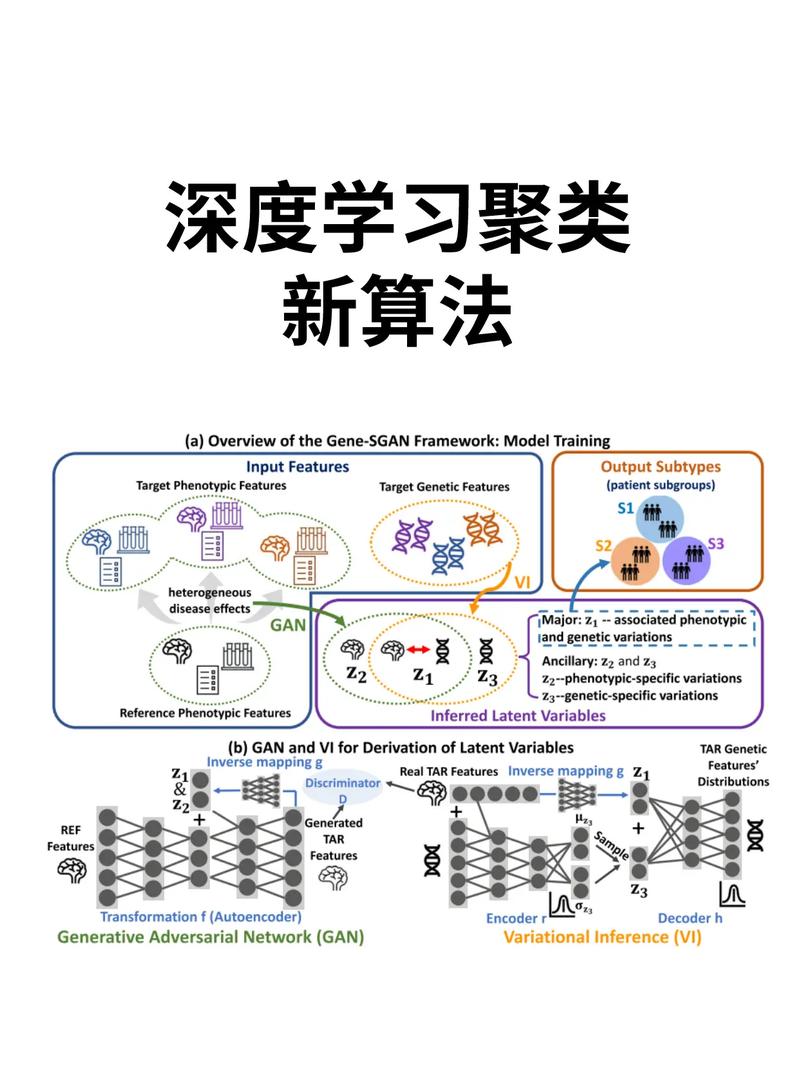
4. 聚类算法:聚类算法是一种无监督学习算法,通过将数据分为若干个类别来发现数据中的潜在结构。常见的聚类算法有Kmeans、层次聚类等。聚类算法的优点是可以发现数据中的潜在结构,但需要选择合适的聚类数目和算法参数。
5. 神经网络:神经网络是一种模拟人脑神经元结构的算法,通过多层神经元之间的连接来对数据进行分类或回归预测。神经网络的优点是能够处理复杂的非线性关系,但需要大量的数据和计算资源进行训练。
以上只是一些常见的机器学习算法八股,实际上机器学习算法的种类非常丰富,需要根据具体问题选择合适的算法,并进行相应的调整和优化。
机器学习算法八股:面试必备知识点解析

在机器学习领域,面试官常常会针对一些常见的算法进行提问,这些被称为“八股”的知识点。掌握这些知识点对于求职者来说至关重要。本文将为您解析机器学习算法八股,帮助您在面试中脱颖而出。
一、监督学习算法
监督学习算法是机器学习中最基础的一类算法,主要包括以下几种:
1. 线性回归
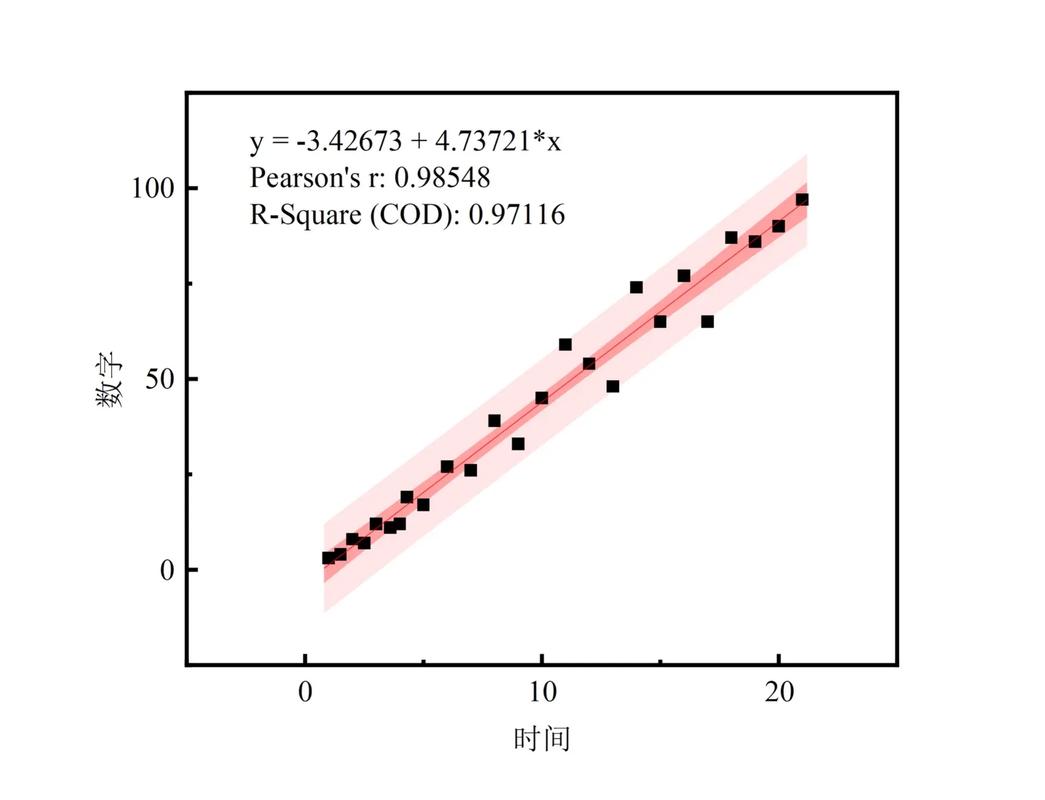
线性回归是一种简单的预测模型,通过拟合数据点与目标值之间的线性关系来进行预测。其核心思想是最小化预测值与实际值之间的误差平方和。
2. 逻辑回归
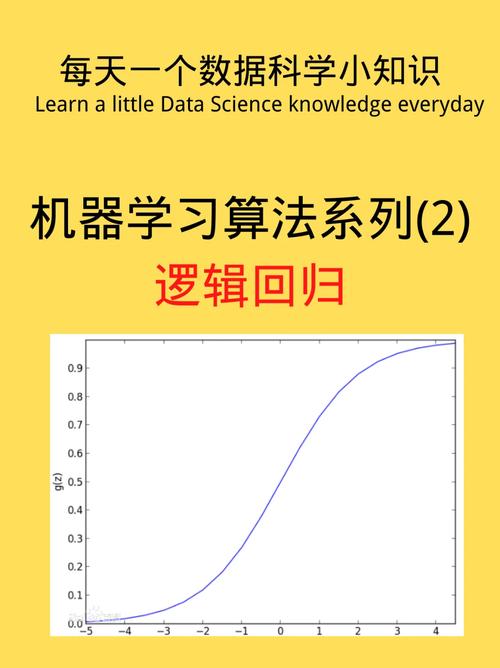
逻辑回归是一种二分类模型,通过求解逻辑函数来预测样本属于正类或负类的概率。它常用于处理分类问题,如垃圾邮件检测、情感分析等。
3. 决策树
决策树是一种基于树结构的分类算法,通过递归地将数据集划分为若干个子集,并选择最优的特征进行分割,最终形成一棵树。决策树具有直观易懂、易于解释的特点。
4. 支持向量机(SVM)

支持向量机是一种二分类模型,通过寻找最优的超平面将数据集划分为两个类别。SVM具有较好的泛化能力,在图像识别、文本分类等领域有广泛应用。
5. K最近邻(KNN)
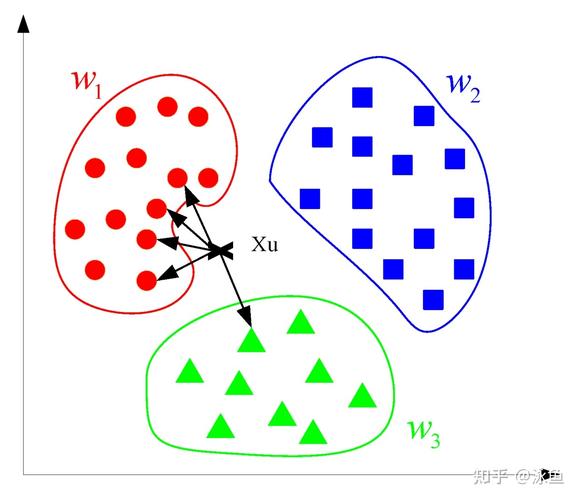
K最近邻算法是一种基于距离的简单分类算法,通过计算待分类样本与训练集中每个样本的距离,选取距离最近的K个样本,并根据这K个样本的类别进行预测。
二、无监督学习算法

无监督学习算法主要用于处理非标记数据,主要包括以下几种:
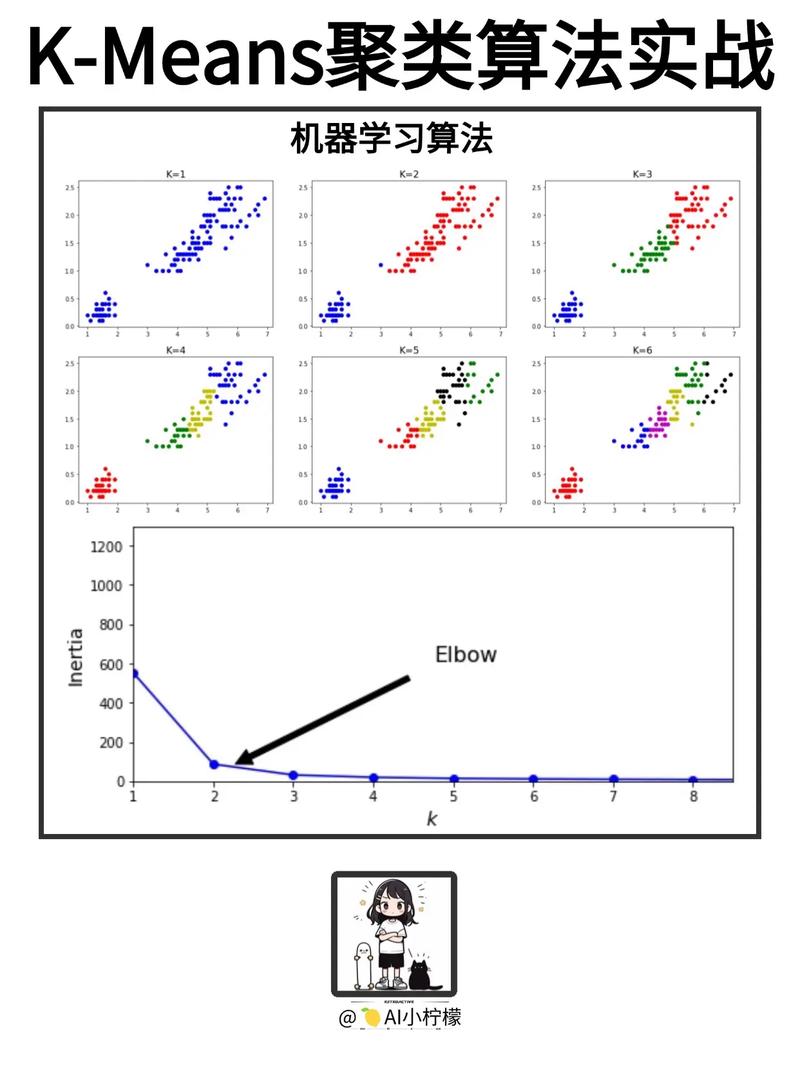
1. K-means聚类

K-means聚类是一种基于距离的聚类算法,通过迭代优化聚类中心,将数据集划分为K个簇,使得每个簇内的样本距离聚类中心较小,而不同簇之间的样本距离较大。
2. 主成分分析(PCA)
主成分分析是一种降维算法,通过将原始数据投影到低维空间,保留数据的主要信息,从而降低计算复杂度。
3. 聚类层次法
聚类层次法是一种基于层次结构的聚类算法,通过合并距离最近的两个簇,逐步形成一棵树,最终得到聚类结果。
4. 聚类EM算法

聚类EM算法是一种基于概率模型的聚类算法,通过迭代优化模型参数,将数据集划分为多个簇,使得每个簇内的样本概率较大,而不同簇之间的样本概率较小。
三、强化学习算法

强化学习是一种通过与环境交互来学习最优策略的算法,主要包括以下几种:
1. Q学习
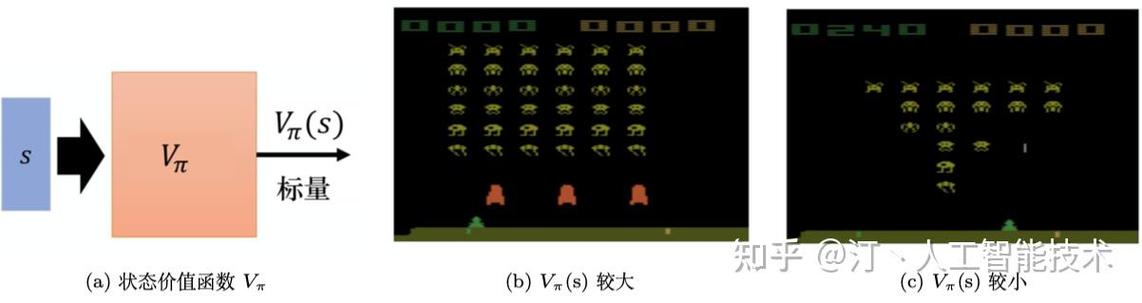
Q学习是一种基于值函数的强化学习算法,通过学习状态-动作值函数,选择最优的动作来最大化长期奖励。
2. 策略梯度法
策略梯度法是一种基于策略的强化学习算法,通过直接优化策略函数,选择最优的动作来最大化长期奖励。
3. 深度Q网络(DQN)
深度Q网络是一种结合了深度学习和Q学习的强化学习算法,通过神经网络来近似Q函数,从而实现更复杂的策略学习。
掌握机器学习算法八股对于求职者来说至关重要。本文为您解析了监督学习、无监督学习和强化学习中的常见算法,希望对您的面试有所帮助。








