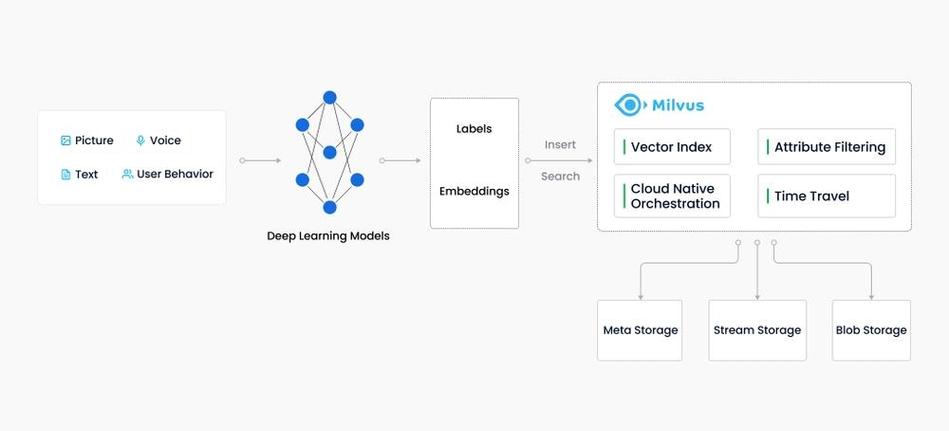
向量数据库是一种专门用于存储、索引和查询高维向量的数据库系统。它被设计用来高效地处理和分析大规模的向量数据,如文本、图像、音频等数据类型。向量数据库的核心功能包括:
1. 向量存储:向量数据库能够存储大量的高维向量数据。这些向量通常是通过机器学习算法从原始数据中提取的特征向量。
2. 索引:为了快速检索向量,向量数据库通常使用专门的索引结构,如局部敏感哈希(LSH)或树状结构(如KD树、球树等),来加速相似度查询。
3. 相似度查询:向量数据库支持多种相似度查询方式,如最近邻搜索(KNN)、余弦相似度等。这些查询帮助用户找到与给定查询向量最相似的数据点。
4. 支持多种距离度量:向量数据库可以处理多种距离度量,如欧氏距离、余弦距离等,以适应不同的应用场景。
5. 可扩展性:为了处理大规模数据,向量数据库通常设计为分布式系统,支持水平扩展。
6. 高效性:向量数据库通过优化数据结构和查询算法,提高查询效率,减少响应时间。
向量数据库:开启智能搜索新时代
随着大数据时代的到来,信息量的爆炸式增长使得传统的搜索引擎在处理海量数据时显得力不从心。为了满足用户对信息检索的更高要求,向量数据库应运而生。本文将深入探讨向量数据库的概念、应用场景以及与传统搜索引擎的区别。
二、什么是向量数据库

向量数据库是一种专门用于存储和检索高维向量数据的数据库。它将文本、图像、音频等非结构化数据转换为向量形式,以便在多维空间中进行相似性搜索和分析。
向量数据库的核心优势在于其高效的相似性搜索能力。通过将数据转换为向量,向量数据库可以在短时间内找到与查询向量最相似的数据,从而实现快速、准确的搜索结果。
三、向量数据库与传统搜索引擎的区别
传统搜索引擎主要基于关键词匹配,而向量数据库则通过向量相似度计算来检索数据。以下是两者之间的主要区别:
搜索方式:
传统搜索引擎:基于关键词匹配,搜索结果依赖于关键词的精确度。
向量数据库:基于向量相似度计算,搜索结果更依赖于数据的语义相关性。
搜索精度:
传统搜索引擎:搜索结果可能包含大量无关信息,用户需要手动筛选。
向量数据库:搜索结果更精准,用户可以快速找到所需信息。
应用场景:
传统搜索引擎:适用于一般性的信息检索,如网页搜索、新闻检索等。
向量数据库:适用于需要语义理解和相似性搜索的场景,如推荐系统、图像识别、语音识别等。
四、向量数据库的应用场景
推荐系统:
向量数据库可以用于存储用户行为数据,通过分析用户行为向量,为用户推荐个性化内容。
图像识别:
向量数据库可以用于存储图像数据,通过分析图像向量,实现图像相似度搜索和分类。
语音识别:
向量数据库可以用于存储语音数据,通过分析语音向量,实现语音相似度搜索和识别。
知识图谱:
向量数据库可以用于存储实体和关系数据,通过分析实体向量,实现实体相似度搜索和推理。
向量数据库作为一种新兴的数据库技术,在处理海量数据、实现语义搜索和相似性搜索方面具有显著优势。随着技术的不断发展,向量数据库将在更多领域发挥重要作用,为用户提供更加智能、高效的搜索体验。
向量数据库、搜索引擎、相似性搜索、推荐系统、图像识别、语音识别、知识图谱