选择向量数据库时,需要考虑以下几个关键因素:
1. 数据模型:向量数据库需要支持向量数据模型,包括向量的存储、检索和计算。
2. 查询性能:向量数据库需要具备高效的查询性能,能够快速检索出与查询向量相似度最高的向量。
3. 可扩展性:向量数据库需要具备良好的可扩展性,能够支持大规模数据的存储和检索。
4. 稳定性和可靠性:向量数据库需要具备高稳定性和可靠性,能够保证数据的安全性和完整性。
5. 易用性:向量数据库需要具备易用性,能够方便地进行数据的存储、检索和管理。
6. 成本:向量数据库的成本也是需要考虑的因素之一,包括软件成本、硬件成本和维护成本等。
7. 社区和支持:向量数据库的社区和支持也是需要考虑的因素之一,能够提供技术支持和解决方案。
8. 兼容性:向量数据库需要与现有的技术栈和生态系统兼容,能够方便地进行集成和使用。
9. 特殊功能:根据具体的应用场景,可能还需要考虑向量数据库的特殊功能,如向量聚类、向量可视化等。
10. 安全性:向量数据库需要具备安全性,能够保护数据的安全性和隐私性。
综合考虑以上因素,可以选择合适的向量数据库。目前市场上比较流行的向量数据库包括:
1. Faiss:由Facebook AI Research开发的向量数据库,具有高效查询性能和良好的可扩展性。
2. Annoy:由Spotify开发的向量数据库,具有高效的查询性能和易用性。
3. ScaNN:由Google开发的向量数据库,具有高效的查询性能和良好的可扩展性。
4. Milvus:由Zilliz开发的向量数据库,具有高效查询性能、良好的可扩展性和易用性。
5. Vespa:由Yahoo开发的向量数据库,具有高效查询性能、良好的可扩展性和易用性。
6. Elasticsearch:虽然Elasticsearch主要用于文本搜索,但它也支持向量搜索,并且具有广泛的社区和支持。
7. Redis:虽然Redis主要用于键值存储,但它也支持向量存储和检索,并且具有高效查询性能和易用性。
8. PGStrom:基于PostgreSQL的向量数据库,具有高效查询性能和良好的可扩展性。
9. Pinot:由LinkedIn开发的向量数据库,具有高效查询性能和良好的可扩展性。
10. DSSM:由Google开发的深度语义搜索模型,可以用于构建向量数据库。
选择向量数据库时,需要根据具体的应用场景和需求进行评估和选择。
向量数据库选型指南:助力高效数据检索与处理
随着大数据和人工智能技术的快速发展,向量数据库在处理大规模数据检索和相似性搜索方面发挥着越来越重要的作用。本文将为您详细介绍向量数据库的选型指南,帮助您找到最适合您业务需求的数据库。
一、了解向量数据库的基本概念
向量数据库是一种专门用于存储和检索高维向量数据的数据库。它通过将数据项(如文本、图像、音频等)转换为向量形式,以便于进行相似性搜索和快速检索。向量数据库广泛应用于推荐系统、自然语言处理、图像识别等领域。
二、向量数据库的选型标准
在选型向量数据库时,以下标准可以帮助您做出明智的决策:
1. 性能要求
查询速度:数据库处理查询的速度,通常以毫秒为单位。
响应时间:数据库返回查询结果所需的时间。
吞吐量:数据库在单位时间内处理查询的数量。
2. 扩展性

水平扩展:数据库是否支持通过增加节点来提高性能。
垂直扩展:数据库是否支持通过增加硬件资源来提高性能。
3. 索引策略

最近邻搜索(Nearest Neighbor Search,NNS):找到与查询向量最相似的向量。
聚类:将相似向量分组在一起,以便于快速检索。
多维索引:将向量数据存储在多维空间中,以便于进行高效检索。
4. 生态与兼容性
支持多种编程语言和框架。
提供丰富的API和SDK。
与其他数据库和工具的兼容性。
三、主流向量数据库对比
1. Faiss
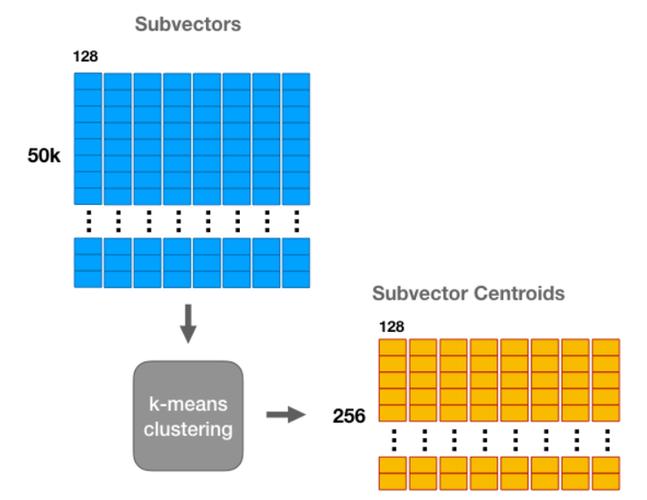
Faiss是由Facebook AI Research开发的高效相似性搜索库。它具有以下特点:
支持多种索引策略。
易于使用和集成。
适用于大规模数据集。
2. Milvus
Milvus是一个开源的向量数据库,专为处理大规模向量数据而设计。它具有以下特点:
高性能的向量搜索能力。
支持多种索引类型。
易于使用和集成。
3. Elasticsearch

Elasticsearch是一个强大的全文搜索引擎,也支持向量搜索。它具有以下特点:
支持多种数据类型。
易于使用和扩展。
适用于复杂查询。
4. Chroma

Chroma是一个轻量级的向量数据库,适用于自然语言处理原型构建。它具有以下特点:
易于使用和集成。