我无法直接下载网页内容。如果您需要下载网页内容,我建议您使用浏览器的“保存页面”功能,或者使用其他工具来下载网页。您也可以告诉我您需要下载的网页的具体内容,我可以帮助您提供相关信息。
HTML文件下载教程:轻松掌握网页源代码获取方法
一、什么是HTML文件下载?
HTML文件下载,顾名思义,是指将网页的源代码文件下载到本地进行查看、学习或修改的过程。HTML(HyperText Markup Language,超文本标记语言)是构成网页文档的主要语言,通过HTML文件下载,我们可以深入了解网页的结构和设计,对于前端开发者和网页爱好者来说,这是一个非常有用的技能。
二、HTML文件下载的准备工作
在进行HTML文件下载之前,我们需要做一些准备工作:
选择合适的文本编辑器:如Notepad 、Sublime Text、Visual Studio Code等,这些编辑器都支持HTML文件的编辑。
获取网页地址:在浏览器中打开目标网页,复制其地址栏中的URL。
三、HTML文件下载的具体步骤

以下是HTML文件下载的具体步骤:
打开你要下载源代码的网页。
在浏览器的地址栏中复制网页的地址。
打开文本编辑器,如Notepad ,新建一个文本文件。
将复制的网页地址粘贴到文本编辑器的新建文本中。
将文本保存为HTML文件,并选择保存的位置。文件扩展名应保存为.html。
打开保存的HTML文件,就可以看到网页的源代码了。
四、HTML文件下载的注意事项
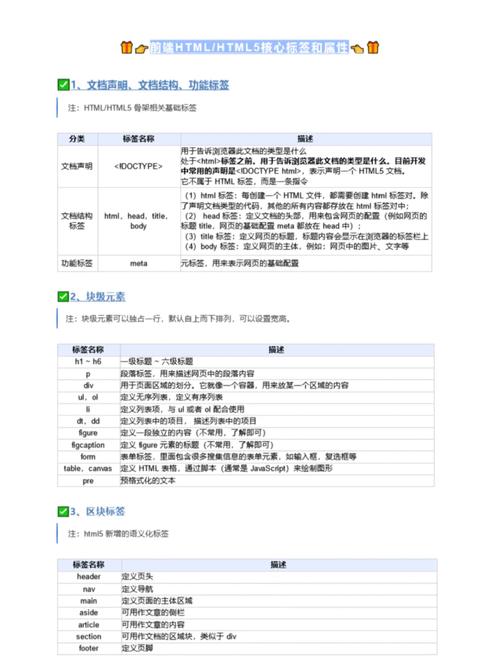
在进行HTML文件下载时,需要注意以下几点:
部分网站可能限制用户获取其网页的源代码,此时可以尝试使用其他方法获取。
获取网页源代码时,要注意版权问题。如果你要使用网页的源代码进行商业用途,需要事先获得网页所有者的授权。
在下载过程中,如果遇到乱码问题,可以尝试更改文件的编码格式,如将UTF-8编码更改为GBK编码。
五、HTML文件下载的替代方法
除了上述的HTML文件下载方法外,还有一些替代方法可以获取网页源代码:
使用在线HTML查看器:如HTML-Kit、HTML Validator等,这些工具可以帮助你在线查看和编辑HTML文件。
使用浏览器插件:如Firebug、Chrome DevTools等,这些插件可以帮助你查看和修改网页的源代码。
使用爬虫工具:如BeautifulSoup、Scrapy等,这些工具可以帮助你从网站中提取HTML文件。
HTML文件下载是前端开发者和网页爱好者必备的技能之一。通过本文的教程,相信你已经掌握了HTML文件下载的方法。在实际操作过程中,多加练习,不断提高自己的技能水平,相信你会成为一名优秀的前端开发者。
本文详细介绍了HTML文件下载的方法和注意事项,希望对大家有所帮助。如果你在下载过程中遇到任何问题,欢迎在评论区留言,我会尽力为你解答。