
向量数据库是一种专门用于存储、索引和查询高维向量的数据库系统。它设计用于处理和分析大量的向量数据,如机器学习模型中的特征向量或文本数据的嵌入表示。向量数据库通常支持以下功能:
1. 存储:能够高效地存储大量的高维向量数据。2. 索引:利用特定的索引结构(如KD树、球树、局部敏感哈希(LSH)等)来加速向量之间的相似性搜索。3. 查询:支持基于距离的查询,如最近邻搜索(Nearest Neighbor Search,NN搜索),以及更复杂的查询,如在特定距离范围内的向量搜索。4. 高维数据支持:能够处理高维空间中的数据,这是传统关系型数据库难以高效处理的。
向量数据库在机器学习、推荐系统、图像和视频分析、自然语言处理等领域有着广泛的应用。例如,在推荐系统中,向量数据库可以用来存储用户和项目的特征向量,并通过相似性搜索来找到与用户最匹配的项目。在图像和视频分析中,向量数据库可以用来存储图像或视频的嵌入表示,并通过搜索找到与给定图像或视频最相似的实例。
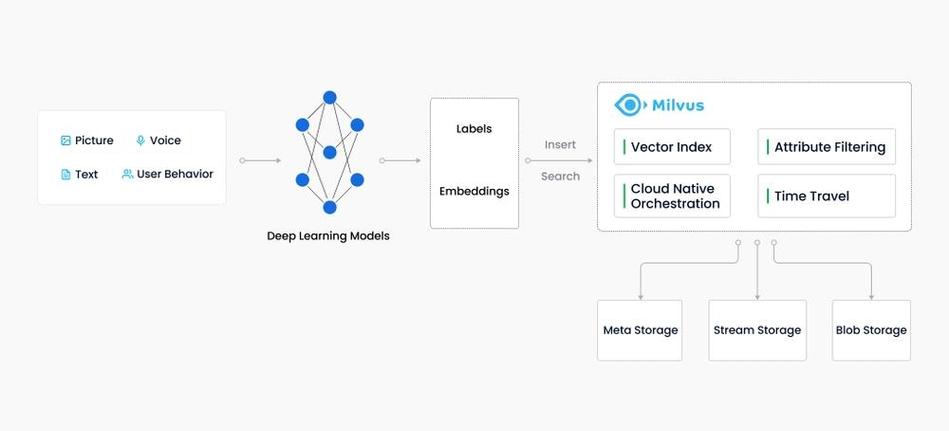
常见的向量数据库包括Faiss、Elasticsearch(通过其向量字段类型和机器学习功能)、Milvus等。这些系统提供了不同的索引方法和查询接口,以满足不同的应用需求。
向量数据库:揭秘高效数据检索的未来
什么是向量数据库?
向量数据库是一种专门用于存储和检索高维向量数据的数据库系统。在数据科学和机器学习领域,向量数据无处不在,如文本、图像、音频等。向量数据库通过高效地处理这些高维数据,为用户提供快速、准确的检索结果。
向量数据库的特点
向量数据库具有以下特点:
高维数据存储:向量数据库能够存储和处理高维向量数据,如文本、图像、音频等。
高效检索:向量数据库采用高效的索引和搜索算法,能够快速检索相似向量。
支持多种索引类型:向量数据库支持多种索引类型,如IVF、HNSW、Annoy等,以满足不同应用场景的需求。
易于集成:向量数据库通常与主流的机器学习框架和编程语言兼容,便于开发者集成到现有系统中。
向量数据库的应用场景
图像检索:通过向量数据库,可以快速检索与给定图像最相似的图像。
文本相似度计算:向量数据库可以用于计算文本之间的相似度,从而实现文本聚类、推荐系统等功能。
推荐系统:向量数据库可以用于存储用户和物品的向量表示,从而实现基于内容的推荐。
自然语言处理:向量数据库可以用于存储和检索文本数据,从而支持文本分类、情感分析等任务。
常见的向量数据库
Milvus:由Zilliz团队开发的开源向量数据库,支持多种索引类型和高效的向量检索。
Qdrant:一个开源的向量搜索引擎,提供高性能的向量存储和检索功能。
Chroma:由Zilliz团队开发的向量数据库,支持多种索引类型和高效的向量检索。
FAISS:由Facebook AI Research开发的高性能向量相似度搜索库,支持多种索引类型和距离度量方法。
向量数据库的优势
与传统的数据库相比,向量数据库具有以下优势:
高效检索:向量数据库采用高效的索引和搜索算法,能够快速检索相似向量。
高维数据支持:向量数据库能够存储和处理高维向量数据,如文本、图像、音频等。
易于集成:向量数据库通常与主流的机器学习框架和编程语言兼容,便于开发者集成到现有系统中。
向量数据库作为一种高效的数据检索工具,在数据科学和机器学习领域发挥着越来越重要的作用。随着技术的不断发展,向量数据库将在更多领域得到应用,为用户提供更加便捷、高效的数据检索服务。








