大数据运维(Big Data Operations)是指对大数据平台进行维护、监控、优化和保障其稳定运行的一系列工作。它涵盖了大数据平台从部署、运行到维护的整个过程,确保大数据系统能够高效、安全地处理和分析数据。
大数据运维的主要工作内容包括:
1. 系统部署与配置:负责大数据平台的安装、配置和初始化,包括硬件资源、软件环境和数据存储等。
2. 性能监控与优化:实时监控大数据平台的运行状态,包括CPU、内存、磁盘I/O、网络流量等指标,及时发现并解决性能瓶颈。
3. 故障排查与恢复:当大数据平台出现故障时,快速定位问题并进行修复,确保系统的连续性和稳定性。
4. 数据备份与恢复:制定并执行数据备份策略,确保数据的安全性和可恢复性。
5. 安全管理:负责大数据平台的安全防护,包括用户权限管理、数据加密、访问控制等,防止数据泄露和未授权访问。
6. 资源管理与调度:合理分配和管理大数据平台的计算、存储和网络资源,提高资源利用率。
7. 日志分析与审计:收集和分析大数据平台的运行日志,用于问题排查、性能优化和安全审计。
8. 自动化运维:利用自动化工具和脚本,实现大数据平台的自动化部署、监控和运维,提高运维效率。
9. 持续集成与持续部署:与开发团队协作,实现大数据平台的持续集成和持续部署,确保系统的快速迭代和更新。
10. 培训与支持:为大数据平台的用户和开发者提供培训和技术支持,帮助他们更好地使用和运维大数据平台。
大数据运维是一个涉及多个领域的综合性工作,需要具备扎实的技术基础、丰富的运维经验和良好的问题解决能力。随着大数据技术的不断发展,大数据运维的重要性也越来越突出,成为保障大数据平台稳定运行的关键环节。
什么是大数据运维?

大数据运维,即大数据环境下的运维工作,是指在大数据技术架构下,对大数据平台、系统、应用等进行监控、维护、优化和故障处理的一系列工作。随着大数据技术的广泛应用,大数据运维成为了保障大数据系统稳定运行的关键环节。
大数据运维的工作内容
大数据运维的工作内容主要包括以下几个方面:
1. 系统监控:对大数据平台中的各个组件进行实时监控,包括Hadoop、Spark、Flink等,确保系统运行稳定,及时发现并处理异常情况。
2. 资源管理:负责大数据集群的资源分配、调度和优化,确保资源得到合理利用,提高系统性能。

3. 故障处理:当系统出现故障时,大数据运维工程师需要迅速定位问题,采取有效措施进行修复,保障业务连续性。

4. 性能优化:通过分析系统性能数据,找出瓶颈,对系统进行优化,提高数据处理效率。
5. 自动化运维:开发自动化脚本和工具,实现日常运维工作的自动化,提高运维效率。
6. 安全防护:保障大数据平台的安全,包括数据安全、系统安全、网络安全等。

大数据运维的技能要求
大数据运维工程师需要具备以下技能:
1. 熟悉大数据技术栈:掌握Hadoop、Spark、Flink等大数据技术,了解其架构和原理。

2. 熟悉Linux操作系统:具备Linux操作系统的基本操作和故障处理能力。
3. 熟悉网络知识:了解网络协议、网络架构和网络安全知识。
4. 编程能力:掌握Java、Python等编程语言,能够编写自动化脚本和工具。
5. 数据分析能力:具备一定的数据分析能力,能够对系统性能数据进行解读和分析。

6. 沟通协调能力:与开发、测试等团队进行有效沟通,协调解决问题。

大数据运维的发展前景
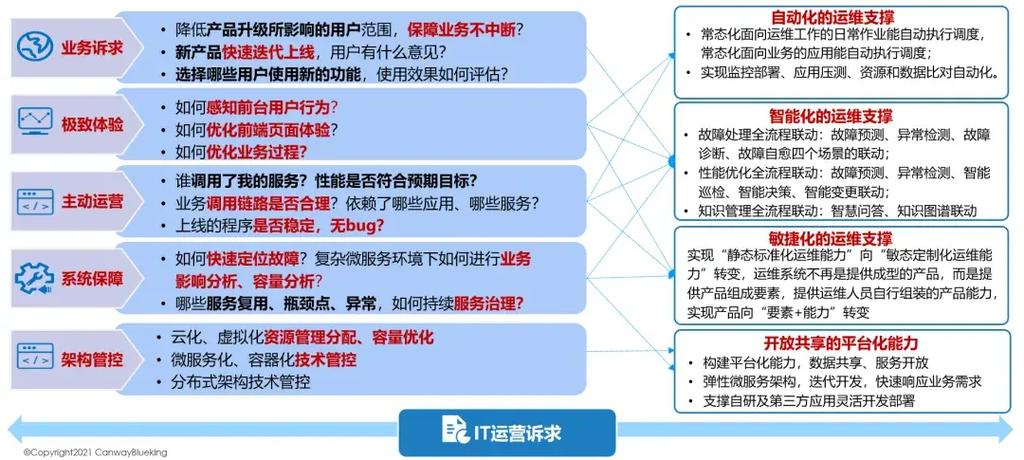
随着大数据技术的不断发展,大数据运维在各个行业中的应用越来越广泛。以下是大数据运维的发展前景:
1. 市场需求旺盛:随着大数据技术的普及,大数据运维人才需求持续增长。
2. 技术更新迭代快:大数据运维领域技术更新迭代快,需要不断学习新技术,提升自身能力。
3. 行业应用广泛:大数据运维在金融、医疗、教育、零售等行业都有广泛应用,发展前景广阔。
4. 薪资待遇优厚:大数据运维工程师的薪资待遇普遍较高,且随着经验的积累,薪资水平有望进一步提升。
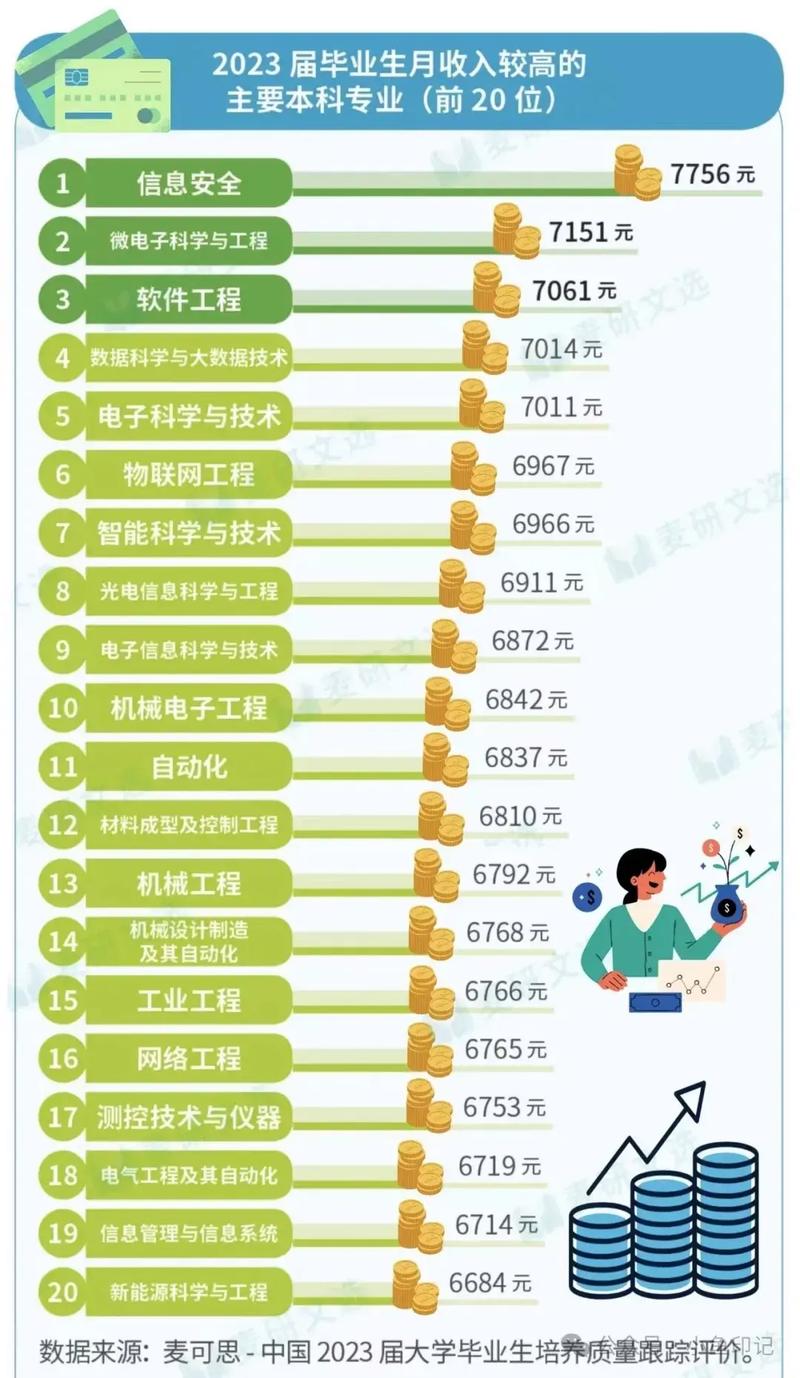
大数据运维作为大数据技术领域的重要组成部分,其工作内容丰富,技能要求较高。随着大数据技术的不断发展,大数据运维工程师在各个行业中的应用越来越广泛,发展前景十分看好。对于有志于从事大数据运维工作的朋友来说,这是一个充满挑战和机遇的职业选择。