1. Kettle 特点:图形化用户界面,支持多种数据源,包括关系数据库、文件、API等。 优势:丰富的转换步骤和功能,支持大规模数据处理和并行处理,与Hadoop等大数据平台集成。 劣势:学习曲线较陡峭,文档支持有限,不支持CDC实时数据采集功能。
2. AirByte 特点:开源的数据集成平台,支持多种数据源和目标系统。 优势:易于使用,支持实时数据同步,强大的社区支持。 劣势:相对较新,功能可能不如一些成熟工具全面。
3. Talend Open Studio 特点:提供全面的数据集成解决方案,包括数据抽取、转换、加载、数据质量、数据管理等功能。 优势:直观的图形化界面,丰富的连接器支持,强大的社区支持和文档资源。 劣势:对于复杂的数据转换需求,可能需要一定的学习成本。
4. Apache NiFi 特点:基于Web的开源系统,用于自动化数据流和内容的传输、处理和系统间集成。 优势:强大的数据路由、转换和系统中介功能,支持多种数据源和目标,易于扩展和定制。 劣势:配置较为复杂,需要一定的学习成本。
5. Apache Sqoop 特点:用于Hadoop与关系数据库之间的数据同步。 优势:支持全量和增量数据抽取,提供高效的数据传输性能。 劣势:主要用于大数据场n6. Apache Flume 特点:分布式、可靠、高可用的日志收集、聚合和传输系统。 优势:支持从多种数据源收集数据,并将其传输到指定的目标系统。 劣势:主要用于日志数据处理,对于其他类型的数据集成需求可能不是最佳选择。
7. Apache Nifi 特点:提供可视化的数据流处理界面,支持从各种数据源抽取数据,并进行转换和加载。 优势:支持实时数据流处理,广泛用于物联网和大数据处理。 劣势:配置较为复杂,需要一定的学习成本。
8. Apache Kafka Connect 特点:用于在Kafka和其他系统之间传输数据。 优势:支持实时数据流处理,易于与Kafka生态系统中的其他组件集成。 劣势:主要用于流处理场n9. Apache Camel 特点:基于规则的路由和中介引擎,提供丰富的数据集成模式。 优势:支持多种传输协议和数据格式,可与其他Apache项目无缝集成。 劣势:对于复杂的路由和转换逻辑,可能需要一定的学习成本。
10. Apache Hop 特点:灵活且易于扩展的ETL工具,专注于数据集成和数据流管理。 优势:简化复杂的数据集成过程,支持多种数据源和数据格式。 劣势:相对较新,功能可能不如一些成熟工具全面。
这些工具各有其特点和优势,企业在选择时应根据具体需求、性能要求、成本效益、社区支持和扩展性等因素进行综合考虑。
深入解析开源ETL工具——Kettle的强大功能与应用
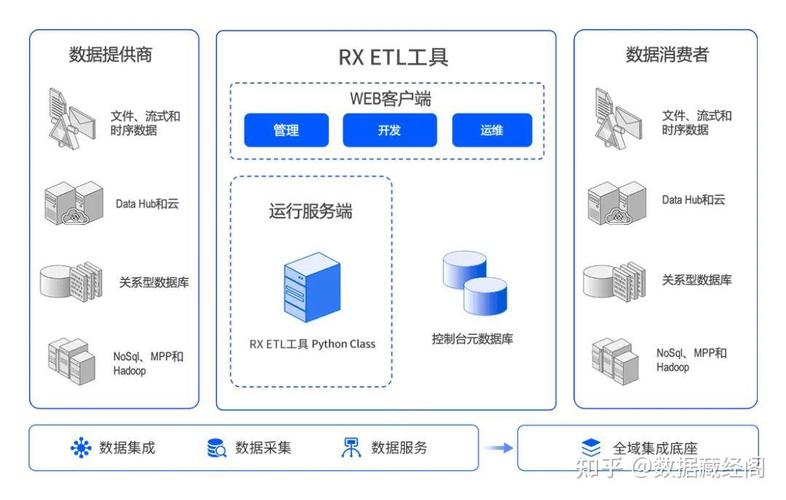
随着大数据时代的到来,数据仓库和数据集成在企业的信息化建设中扮演着越来越重要的角色。ETL(Extract, Transform, Load)作为数据仓库的核心技术之一,负责数据的抽取、转换和加载,是数据集成过程中的关键环节。本文将深入解析开源ETL工具Kettle的强大功能与应用,帮助读者更好地了解和使用这一优秀的工具。
Kettle,全称Pentaho Data Integration,是一款基于Java的开源ETL工具。它由Pentaho公司主导开发,拥有强大的数据处理能力和丰富的功能。Kettle提供了图形化界面,用户可以通过拖拽和配置的方式构建ETL流程,无需编写复杂的代码,降低了使用门槛。
1. 数据抽取:Kettle支持从各种数据源中抽取数据,包括关系型数据库、非关系型数据库、文件系统等。用户可以根据需求选择合适的抽取方式,如全量抽取、增量抽取等。
2. 数据转换:Kettle提供了丰富的转换组件,如数据清洗、数据映射、数据聚合等。用户可以通过配置转换规则,实现数据的清洗、转换和格式化。
3. 数据加载:Kettle支持将转换后的数据加载到目标数据库、数据仓库或文件系统中。用户可以根据需求选择合适的加载方式,如全量加载、增量加载等。
4. 工作流设计:Kettle支持通过图形化界面设计ETL工作流,用户可以轻松地组合各种转换和加载步骤,实现复杂的数据处理流程。
5. 调度与监控:Kettle提供了任务调度和监控功能,用户可以设置定时任务,对ETL流程进行监控和管理。
1. 开源免费:Kettle是一款开源软件,用户可以免费下载和使用,降低了企业的成本。
2. 跨平台:Kettle基于Java编写,支持Windows、Linux、Mac等多种操作系统,具有良好的跨平台性。
3. 易用性:Kettle提供了图形化界面,用户可以通过拖拽和配置的方式构建ETL流程,降低了使用门槛。
4. 丰富的组件库:Kettle拥有丰富的组件库,可以满足各种数据处理需求。
5. 社区支持:Kettle拥有庞大的用户社区,用户可以在这里获取技术支持、交流经验。
1. 数据仓库建设:Kettle可以用于构建数据仓库,实现数据的抽取、转换和加载,为数据分析和决策提供支持。
2. 数据迁移:Kettle可以用于数据迁移,将数据从旧系统迁移到新系统,保证数据的一致性和完整性。
3. 数据同步:Kettle可以用于数据同步,实现不同系统之间的数据实时同步,保证数据的实时性。
4. 数据清洗:Kettle可以用于数据清洗,去除数据中的错误和异常,提高数据质量。
5. 数据集成:Kettle可以用于数据集成,将来自不同数据源的数据进行整合,为业务分析提供数据支持。
随着大数据和云计算技术的发展,Kettle在未来将会有以下发展趋势:
1. 云原生:Kettle将支持云原生架构,实现ETL流程在云环境中的高效运行。
2. 大数据处理:Kettle将支持大数据处理,满足企业对海量数据的处理需求。
3. 人工智能:Kettle将结合人工智能技术,实现智能化的数据处理和分析。
4. 开放生态:Kettle将与其他开源项目进行整合,构建更加完善的生态体系。
开源ETL工具Kettle凭借其强大的功能、易用性和跨平台性,在数据集成领域得到了广泛应用。随着技术的不断发展,Kettle将继续保持其领先地位,为企业和个人提供更加优质的数据处理解决方案。