
机器学习是人工智能的一个分支,它使计算机系统能够从数据中学习并改进其性能,而无需明确编程。简单来说,机器学习就是让计算机通过学习数据来获取知识和技能,从而做出更准确的预测或决策。
机器学习的过程通常包括以下几个步骤:
1. 数据收集:首先,需要收集大量的相关数据。这些数据可以是结构化的(如表格数据),也可以是非结构化的(如图像、文本等)。
2. 数据预处理:在训练模型之前,需要对数据进行清洗、转换和归一化等预处理操作,以便模型能够更好地理解和处理数据。
3. 特征工程:特征工程是从原始数据中提取出对模型有用的特征。这个过程可能包括选择特征、创建新的特征或转换现有特征等。
4. 模型选择:根据问题的性质和数据的特点,选择合适的机器学习算法。常见的机器学习算法包括监督学习、无监督学习和强化学习等。
5. 模型训练:使用训练数据来训练模型,让模型学习数据的规律和模式。训练过程中,模型会不断调整其内部参数,以最小化预测误差。
6. 模型评估:使用验证数据来评估模型的性能,以确保模型在未知数据上也能做出准确的预测。常用的评估指标包括准确率、召回率、F1分数等。
7. 模型部署:将训练好的模型部署到实际应用中,以便在实际场景中使用模型进行预测或决策。
8. 模型监控和维护:在模型部署后,需要定期监控模型的性能,并根据实际情况对模型进行更新和维护,以确保模型始终能够提供准确的预测或决策。
机器学习在许多领域都有广泛的应用,如自然语言处理、计算机视觉、语音识别、推荐系统、金融预测等。随着大数据和计算能力的不断提升,机器学习在未来的应用前景将更加广阔。
什么是机器学习?
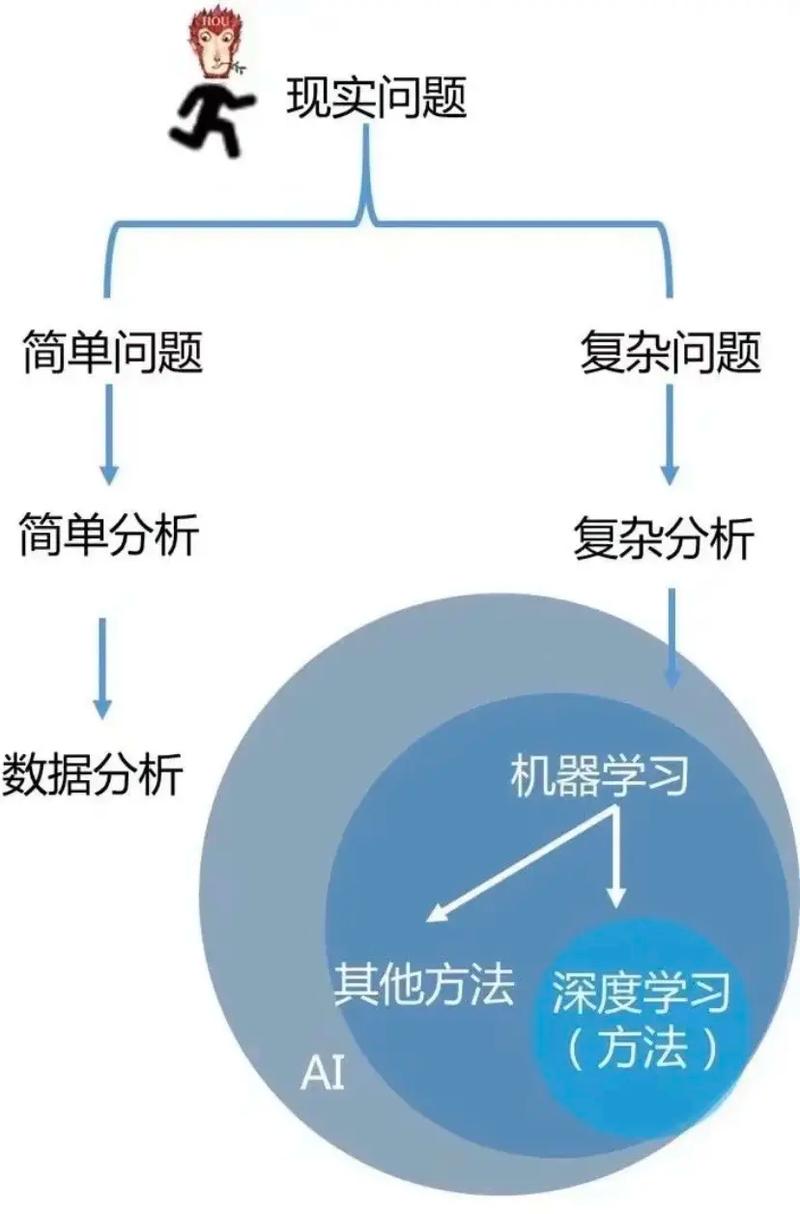
机器学习(Machine Learning,简称ML)是人工智能(Artificial Intelligence,简称AI)的一个子领域,它使计算机系统能够从数据中学习并做出决策或预测,而不是通过明确的编程指令。机器学习的关键在于算法能够从数据中提取模式和知识,从而提高性能和做出更准确的决策。
机器学习的基本概念

机器学习的基本概念包括以下几个要素:
数据(Data):机器学习依赖于大量数据来训练模型。
算法(Algorithms):这些是用于从数据中学习模式的数学公式。
训练(Training):这是将数据输入到算法中,使模型能够学习的过程。
测试(Testing):使用新的数据集来评估模型的性能。
机器学习的类型
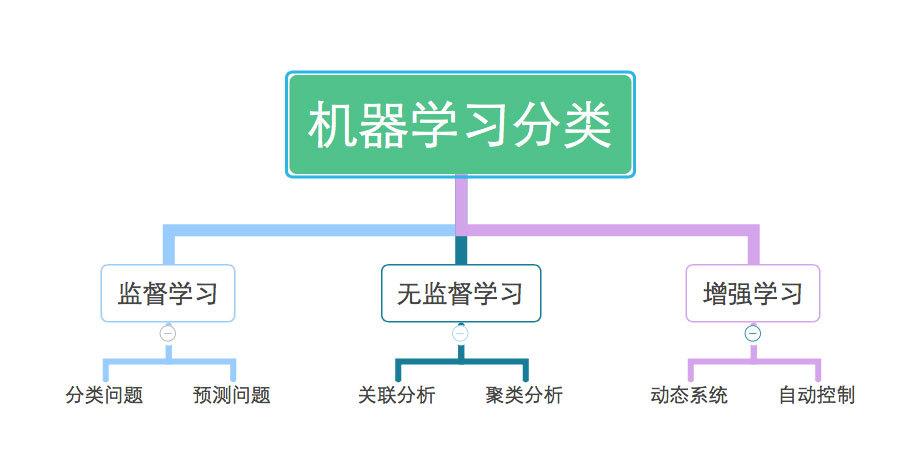
根据学习的方式,机器学习可以分为以下几种类型:
监督学习(Supervised Learning):在这种学习中,算法从标记的训练数据中学习,以便能够对新的、未标记的数据进行预测。
无监督学习(Unsupervised Learning):在这种学习中,算法处理未标记的数据,试图找到数据中的结构或模式。
半监督学习(Semi-supervised Learning):结合了监督学习和无监督学习,使用少量标记数据和大量未标记数据。
强化学习(Reinforcement Learning):在这种学习中,算法通过与环境的交互来学习,并基于奖励和惩罚来优化其行为。
机器学习的应用

图像识别:如人脸识别、物体检测等。
自然语言处理(NLP):如机器翻译、情感分析等。
推荐系统:如电影推荐、商品推荐等。
医疗诊断:如疾病预测、药物发现等。
金融分析:如信用评分、市场预测等。
机器学习的挑战

尽管机器学习取得了显著的进展,但仍然存在一些挑战:
数据质量:机器学习依赖于高质量的数据,数据质量问题会影响模型的性能。
可解释性:许多机器学习模型,尤其是深度学习模型,被认为是“黑箱”,其决策过程难以解释。
过拟合:模型在训练数据上表现良好,但在新数据上表现不佳,这是因为模型过于复杂,无法泛化。
隐私问题:机器学习模型需要处理大量个人数据,这引发了隐私保护的问题。
机器学习的未来

更强大的算法:开发更有效的算法,以处理更复杂的数据和问题。
可解释性增强:提高机器学习模型的可解释性,使其决策过程更加透明。
跨学科合作:机器学习与其他领域的结合,如生物学、物理学等,以解决更广泛的问题。
伦理和法规:制定更严格的伦理和法规,以确保机器学习的负责任使用。
机器学习是一个快速发展的领域,它正在改变我们生活的方方面面。通过从数据中学习,机器学习算法能够帮助计算机做出更智能的决策。尽管存在挑战,但机器学习的未来充满希望,它将继续推动技术创新和社会进步。







