
机器学习中的聚类算法是一种无监督学习技术,旨在将数据点分组或聚类,使得同一组内的数据点彼此相似,而不同组之间的数据点则尽可能不同。聚类算法在许多领域都有应用,如市场细分、图像处理、社交网络分析等。
以下是几种常见的聚类算法:
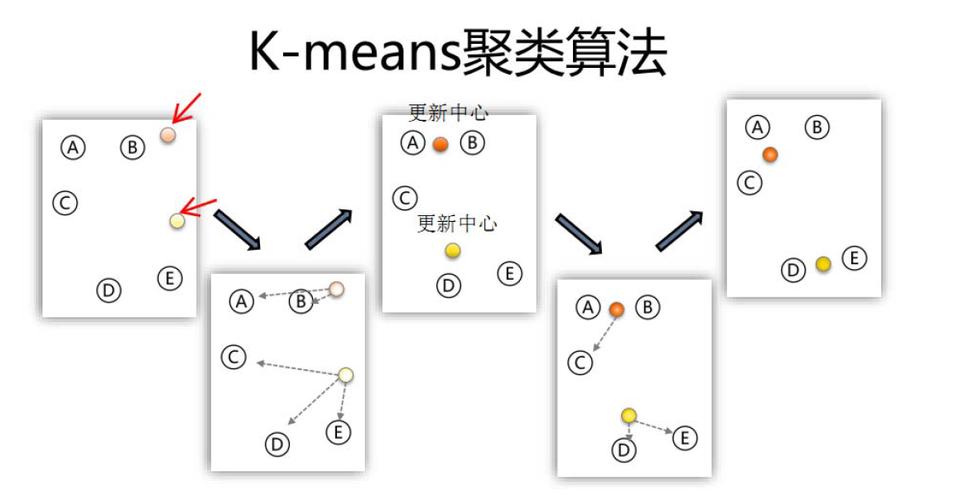
1. K均值聚类(Kmeans clustering):这是最简单、最常用的聚类算法之一。它将数据点分配到K个簇中,其中K是用户指定的。算法通过迭代的方式,将每个数据点分配给最近的簇中心(均值),然后更新簇中心。这个过程重复进行,直到簇中心不再显著改变。
2. 层次聚类(Hierarchical clustering):这种算法通过创建一个树状结构(称为层次树)来对数据进行聚类。层次聚类可以是自底向上的(凝聚式)或自顶向下的(分裂式)。在凝聚式层次聚类中,开始时每个数据点是一个簇,然后根据相似度逐渐合并相邻的簇,直到所有数据点都合并为一个簇。在分裂式层次聚类中,开始时所有数据点都在一个簇中,然后根据相似度逐渐分裂成更小的簇。
3. 密度聚类(Densitybased clustering):这种算法基于数据点的密度来聚类。它将数据点分组为高密度区域,这些区域被低密度区域(称为噪声)包围。DBSCAN(DensityBased Spatial Clustering of Applications with Noise)是一种常用的密度聚类算法,它能够识别出任意形状的簇,并能够处理噪声数据。
5. 谱聚类(Spectral clustering):这种算法利用数据的谱图理论来聚类。它首先构建一个基于数据点相似度的图,然后计算图的拉普拉斯矩阵的特征值和特征向量。根据特征向量将数据点分组。谱聚类能够处理非球形簇和噪声数据。
6. K中心点聚类(Kmedoids clustering):这种算法类似于K均值聚类,但它使用中位数(称为中心点)而不是均值来表示簇。这使得K中心点聚类对异常值和噪声数据更具鲁棒性。
7. DBSCAN(DensityBased Spatial Clustering of Applications with Noise):这种算法是一种基于密度的聚类算法,它能够发现任意形状的簇,并能够处理噪声数据。DBSCAN通过定义两个参数(eps和min_samples)来控制簇的密度。eps表示邻域半径,min_samples表示邻域内的最小数据点数。
8. OPTICS(Ordering Points To Identify the Clustering Structure):这种算法是一种基于密度的聚类算法,它能够发现任意形状的簇,并能够处理噪声数据。OPTICS通过定义一个参数(eps)来控制簇的密度。它能够生成一个聚类顺序,使得相似的簇彼此靠近。
9. BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies):这种算法是一种基于层次聚类的算法,它能够处理大数据集。BIRCH首先将数据点组织成一个树状结构(称为CF树),然后使用层次聚类算法对CF树进行聚类。
10. ISODATA(Iterative SelfOrganizing Data Analysis Technique):这种算法是一种基于迭代的方法,它能够处理大数据集。ISODATA通过迭代的方式更新簇中心和簇的半径,然后将数据点分配给最近的簇。它能够处理噪声数据和异常值。
这些聚类算法各有优缺点,适用于不同的数据集和聚类任务。选择合适的聚类算法取决于数据的特点和聚类的目标。在实际应用中,可能需要尝试多种算法,并比较它们的性能,以找到最佳的聚类解决方案。
深入解析机器学习中的聚类算法
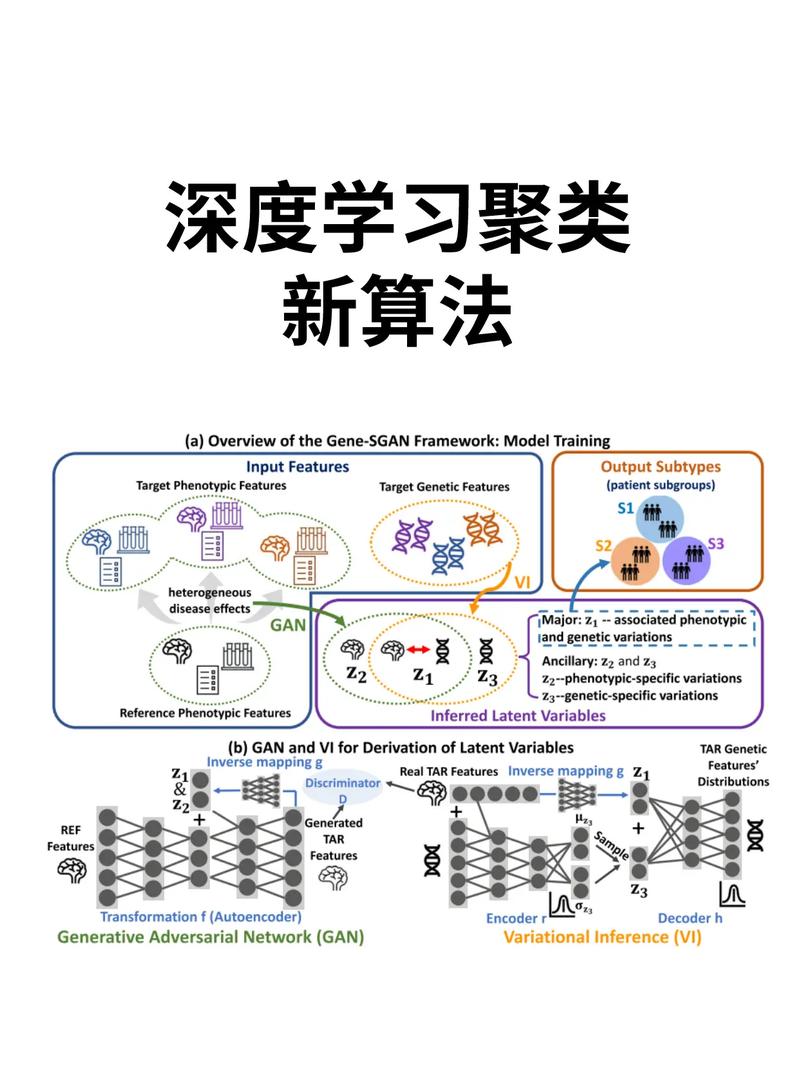
聚类算法是机器学习领域中的一种无监督学习方法,它通过将数据集中的数据点划分为若干个不同的簇,使得同一簇内的数据点具有较高的相似性,而不同簇之间的数据点具有较高的差异性。本文将深入解析机器学习中的聚类算法,包括其基本原理、常用算法以及应用场景。
一、聚类算法的基本原理
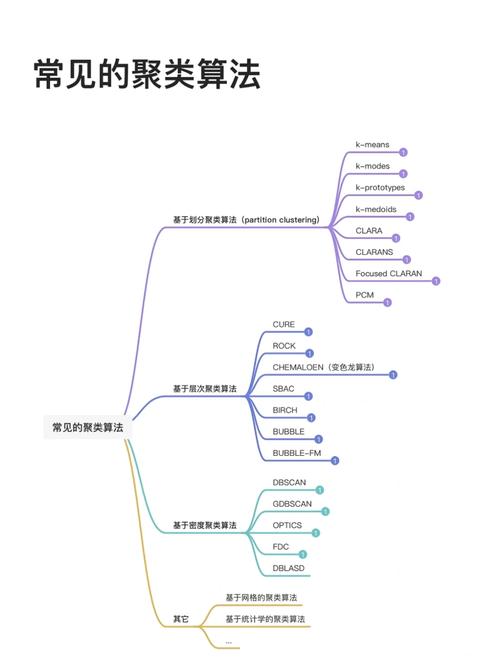
聚类算法的核心思想是将相似的数据点归为一类,而将不相似的数据点分开。具体来说,聚类算法通过以下步骤实现:
选择聚类算法:根据数据特点和需求选择合适的聚类算法。
初始化聚类中心:随机选择或使用特定方法选择初始聚类中心。
分配数据点:将每个数据点分配到距离其最近的聚类中心所在的簇中。
更新聚类中心:计算每个簇的质心,作为新的聚类中心。
迭代:重复步骤3和步骤4,直到聚类中心不再改变或达到预定的迭代次数。
二、常用聚类算法
在机器学习中,常用的聚类算法主要包括以下几种:
1. K-均值聚类算法
K-均值聚类算法是一种基于划分的聚类算法,其基本思想是将数据集划分为K个簇,使得每个簇内的数据点距离其质心的距离之和最小。K-均值聚类算法的优点是简单、易于实现,但缺点是对初始聚类中心的选择敏感,且难以处理非凸形簇。
2. 密度聚类算法
密度聚类算法是一种基于数据点密度的聚类方法,其核心理念是发现数据空间中具有相似密度的区域,并将这些区域划分为不同的簇。密度聚类算法的代表算法有DBSCAN(Density-Based Spatial Clustering of Applications with Noise)和OPTICS(Ordering Points To Identify the Clustering Structure)。
3. 层次聚类算法
层次聚类算法是一种基于层次结构的聚类方法,其基本思想是将数据集逐步合并成簇,直到满足停止条件。层次聚类算法的优点是能够处理任意形状的簇,但缺点是聚类结果依赖于距离度量。
三、聚类算法的应用场景
聚类算法在许多领域都有广泛的应用,以下列举一些常见的应用场景:
市场细分:通过聚类分析,将客户划分为不同的市场细分,以便企业制定更精准的营销策略。
图像分割:将图像中的像素点划分为不同的区域,以便进行图像处理和分析。
生物信息学:通过聚类分析,揭示基因之间的相互作用关系,为疾病诊断和治疗提供依据。
异常检测:通过聚类分析,识别数据集中的异常值或噪声,提高数据质量。
聚类算法是机器学习领域中一种重要的无监督学习方法,通过将数据集中的数据点划分为不同的簇,有助于我们更好地理解数据的分布和特征。本文介绍了聚类算法的基本原理、常用算法以及应用场景,希望对读者有所帮助。








