数据库行锁(Rowlevel Locking)是一种锁定机制,用于控制对数据库表中的特定行的访问。当数据库系统使用行锁时,它可以在多个事务之间提供更细粒度的并发控制。以下是行锁的一些关键概念和特点:
1. 锁定粒度:行锁是数据库锁定机制中粒度最细的一种。它只锁定表中特定的行,而不是整个表或页。
2. 并发控制:行锁允许不同的事务同时访问数据库表的不同行,从而提高并发性能。如果多个事务尝试同时访问同一行,它们可能会发生冲突,导致一个或多个事务被阻塞。
3. 锁定类型: 共享锁(Shared Locks):允许事务读取行,但不允许修改行。 排他锁(Exclusive Locks):允许事务读取和修改行,并阻止其他事务访问该行。
4. 锁定粒度与性能:虽然行锁提供了更高的并发性,但它们也带来了更高的开销。锁定和解锁行需要更多的系统资源,因此,如果使用不当,可能会导致性能下降。
5. 死锁:当两个或多个事务相互等待对方释放它们持有的锁时,就会发生死锁。行锁增加了死锁的可能性,因为它们限制了事务可以访问的行数。
6. 实现:不同的数据库系统可能有不同的行锁实现方式。一些系统使用乐观锁定(Optimistic Locking)或悲观锁定(Pessimistic Locking)策略来管理行锁。
7. 锁定策略:数据库管理员可以配置锁定策略,例如锁定超时、锁定粒度等,以优化性能和并发控制。
8. 应用场景:行锁通常用于高并发场景,如在线交易处理系统,其中多个用户同时访问数据库并执行更新操作。
9. 与表锁的关系:行锁与表锁(Tablelevel Locking)是两种不同的锁定机制。表锁锁定整个表,而行锁只锁定表中的特定行。
10. 注意事项:在使用行锁时,应确保事务的隔离级别和锁定策略与系统的并发需求和性能要求相匹配。
总之,行锁是一种强大的工具,可以提高数据库系统的并发性能,但也需要谨慎使用,以避免死锁和其他性能问题。
深入解析数据库行锁:原理、应用与优化

在数据库管理系统中,行锁是一种重要的并发控制机制,用于确保数据的一致性和完整性。本文将深入探讨数据库行锁的原理、应用场景以及优化策略。
一、行锁的概念与原理
行锁,顾名思义,是对数据库表中的某一行数据进行锁定。在多用户并发访问数据库时,行锁可以防止多个事务同时修改同一行数据,从而避免数据冲突。
行锁的实现原理主要依赖于数据库的索引。当事务对某一行数据进行操作时,数据库会根据该行的索引信息进行锁定。如果该行数据没有索引,那么数据库会使用表锁来保证数据的一致性。
二、行锁的应用场景

行锁在以下场景中具有重要作用:
高并发环境下,多个事务需要同时访问同一行数据。
需要保证数据的一致性和完整性。
避免事务间的冲突,如脏读、不可重复读和幻读。
三、行锁的类型
根据不同的锁定策略,行锁可以分为以下几种类型:
共享锁(Shared Lock):允许多个事务同时读取同一行数据,但禁止修改。
排他锁(Exclusive Lock):禁止其他事务读取或修改同一行数据。
乐观锁:通过版本号或时间戳来检测数据是否被修改,从而避免冲突。
四、行锁的优化策略
合理设计索引:确保行锁能够快速定位到目标行数据。
减少锁的粒度:尽量使用行锁而不是表锁,以提高并发性能。
合理设置事务隔离级别:根据业务需求选择合适的事务隔离级别,如读已提交、可重复读或串行化。
避免长事务:长事务会占用更多的锁资源,降低数据库的并发性能。
五、行锁与死锁
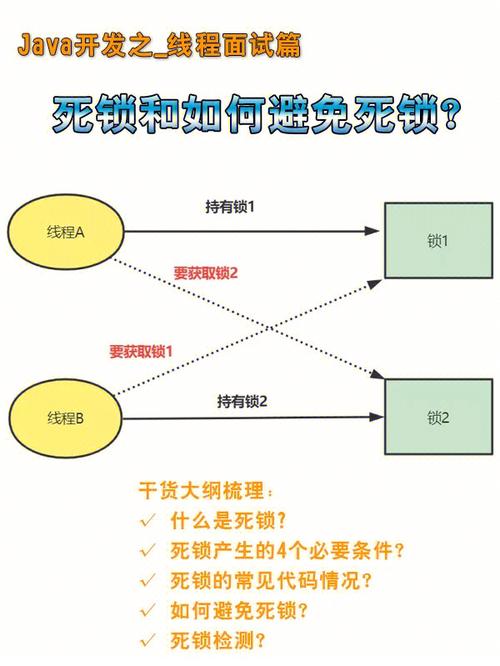
在多事务并发环境下,行锁可能会导致死锁现象。死锁是指两个或多个事务在执行过程中,因争夺资源而造成的一种僵持状态。为了避免死锁,可以采取以下措施:
设置超时时间:当事务等待锁的时间超过设定值时,自动回滚事务。
顺序访问资源:确保所有事务以相同的顺序访问资源,降低死锁发生的概率。
使用锁顺序:在事务中,按照一定的顺序申请锁,避免因锁顺序不一致而导致的死锁。
行锁是数据库并发控制的重要机制,可以有效保证数据的一致性和完整性。了解行锁的原理、应用场景和优化策略,有助于提高数据库的并发性能和稳定性。