机器学习是人工智能的一个分支,它使计算机系统能够从数据中学习并做出决策,而不需要显式地进行编程。机器学习通过算法来分析数据、识别模式,并据此做出预测或决策。这些算法可以自动优化,以便更好地从经验中学习。机器学习通常被分为监督学习、无监督学习和强化学习三类。
2. 无监督学习:与监督学习不同,无监督学习不依赖于已知的输出结果。它通过寻找数据中的模式和关系来学习。例如,聚类算法可以用来将数据点分组,而关联规则学习可以用来发现数据项之间的关联性。
3. 强化学习:强化学习是一种通过奖励和惩罚来训练智能体的方法。智能体在环境中采取行动,并根据其行动的结果获得奖励或惩罚。通过这种方式,智能体可以学习到在特定环境中采取最佳行动的策略。
机器学习在许多领域都有广泛的应用,包括但不限于自然语言处理、计算机视觉、推荐系统、金融预测、医疗诊断等。随着大数据和计算能力的提升,机器学习在解决复杂问题方面的能力也在不断增强。
机器学习:定义与概述
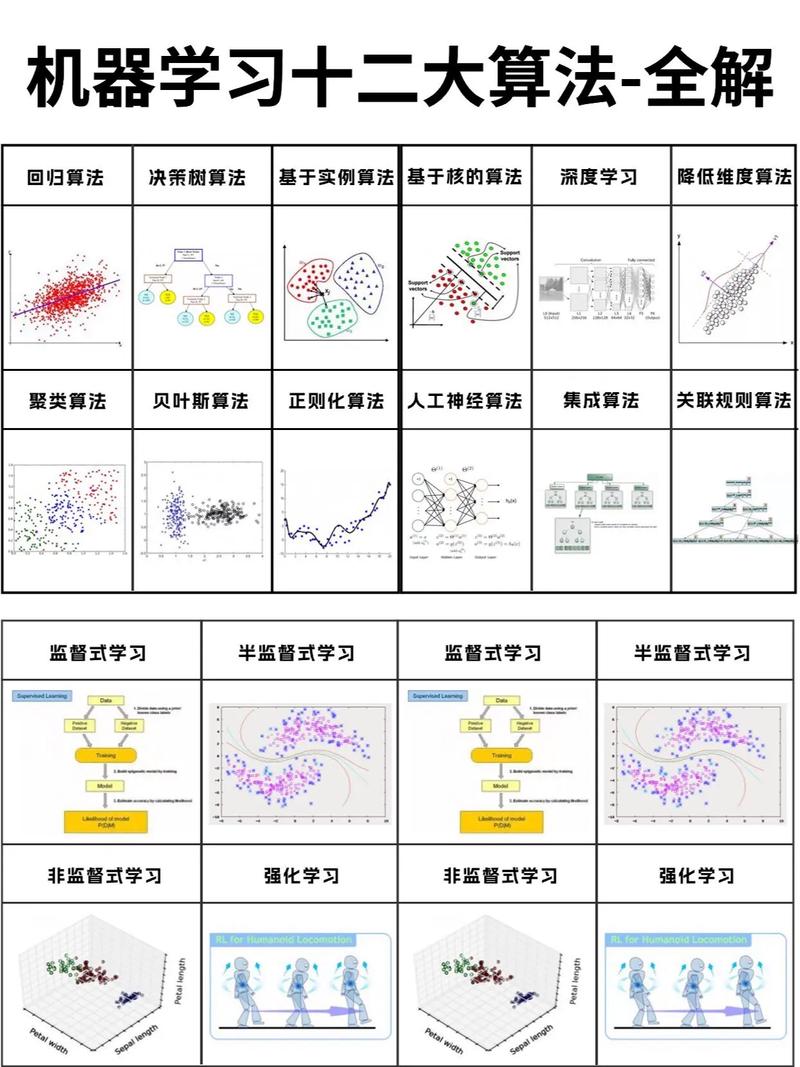
机器学习(Machine Learning,ML)是人工智能(Artificial Intelligence,AI)的一个重要分支,它使计算机系统能够从数据中学习并做出决策或预测,而无需显式编程。机器学习的关键在于算法,这些算法可以从数据中提取模式,并利用这些模式来做出决策。
机器学习的基本概念
机器学习的基本概念包括以下几个要素:
数据:机器学习依赖于大量数据来训练模型。
算法:这些是用于从数据中学习并提取模式的数学公式。
模型:模型是算法处理数据后形成的输出,可以用于预测或分类。
训练:这是将数据输入到算法中,使其能够学习的过程。
测试与验证:这是评估模型性能的过程,确保模型在未知数据上的表现良好。
机器学习的类型
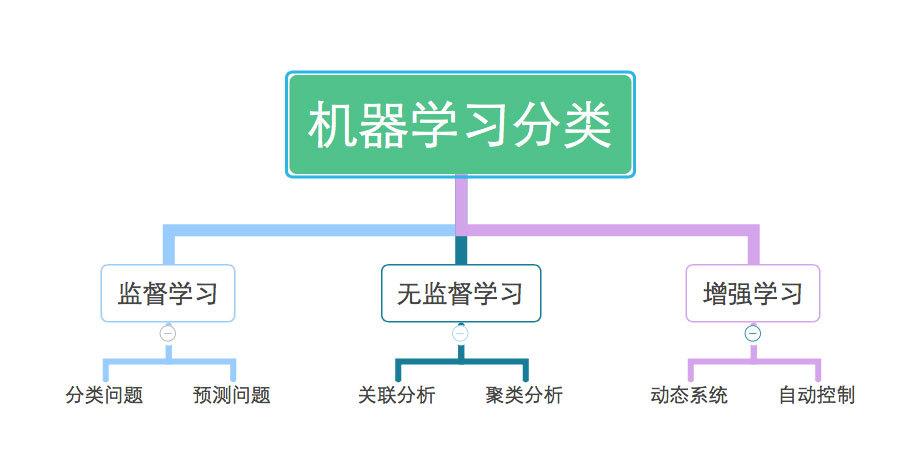
根据学习方式和应用场景,机器学习可以分为以下几种类型:
监督学习(Supervised Learning):在这种学习中,算法从标记的训练数据中学习,以便在测试数据上进行预测。
无监督学习(Unsupervised Learning):在这种学习中,算法处理未标记的数据,寻找数据中的模式或结构。
半监督学习(Semi-supervised Learning):结合了监督学习和无监督学习,使用少量标记数据和大量未标记数据。
强化学习(Reinforcement Learning):在这种学习中,算法通过与环境的交互来学习,并基于奖励和惩罚来优化其行为。
常见的机器学习算法

线性回归(Linear Regression):用于预测连续值。
逻辑回归(Logistic Regression):用于预测二元分类问题。
支持向量机(Support Vector Machine,SVM):用于分类和回归问题。
决策树(Decision Trees):用于分类和回归问题,易于理解和解释。
随机森林(Random Forest):通过构建多个决策树来提高预测准确性。
神经网络(Neural Networks):模仿人脑神经元的工作方式,用于复杂的模式识别。
机器学习的挑战与未来趋势

尽管机器学习取得了显著的进展,但仍面临一些挑战:
数据质量:机器学习依赖于高质量的数据,数据质量问题会影响模型的性能。
可解释性:许多高级机器学习模型,如深度学习,被认为是“黑箱”,其决策过程难以解释。
算法偏见:如果训练数据存在偏见,机器学习模型可能会放大这些偏见。
未来,机器学习的趋势可能包括:
可解释人工智能(XAI):开发更可解释的机器学习模型。
联邦学习(Federated Learning):在保护数据隐私的同时进行模型训练。
跨学科研究:结合心理学、社会学和经济学等领域的研究,以更好地理解人类行为。
结论

机器学习作为人工智能的核心技术之一,正在改变着各行各业。随着技术的不断进步和应用的深入,机器学习将继续推动创新,并为解决复杂问题提供新的解决方案。