
机器学习算法是机器学习领域中的核心内容,它们通过数据学习来建立模型,并对未知数据进行预测或分类。以下是机器学习算法的一些主要类别及其特点:
1. 监督学习算法: 线性回归:通过线性方程预测连续数值。 逻辑回归:用于二分类问题,预测概率。 决策树:通过一系列规则对数据进行分类。 支持向量机(SVM):在特征空间中寻找最优的超平面进行分类。 随机森林:多个决策树的集合,提高分类准确性。 神经网络:模拟人脑神经元结构,适用于复杂非线性问题。
2. 无监督学习算法: K均值聚类:将数据分为K个簇,簇内相似度最大,簇间相似度最小。 层次聚类:自底向上或自顶向下的方式构建聚类树。 主成分分析(PCA):通过降维技术提取数据的主要特征。 自组织映射(SOM):在低维空间中保持高维数据结构。
3. 半监督学习算法: 标记传播:利用少量已标记数据和大量未标记数据训练模型。 生成对抗网络(GAN):由生成器和判别器组成,生成器生成数据,判别器判断数据真假。
4. 强化学习算法: Q学习:通过学习动作值函数来最大化期望回报。 深度Q网络(DQN):将Q学习与神经网络结合,解决高维空间问题。 政策梯度:通过梯度下降优化策略函数,直接输出动作。
5. 集成学习算法: 随机森林:多个决策树的集合,提高分类准确性。 AdaBoost:通过调整样本权重,逐步提高弱学习器的性能。 Gradient Boosting:逐步优化损失函数,提高模型性能。
6. 特征工程: 特征选择:从原始特征中选择对模型预测有帮助的特征。 特征提取:将原始特征转换为更有意义的特征表示。
7. 模型评估: 准确率、召回率、F1分数:评估分类模型的性能。 均方误差(MSE)、均方根误差(RMSE):评估回归模型的性能。 交叉验证:评估模型泛化能力。
8. 模型优化: 梯度下降:通过计算损失函数的梯度来优化模型参数。 随机梯度下降(SGD):在小批量样本上计算梯度,提高计算效率。 牛顿法、拟牛顿法:通过迭代计算梯度来优化模型参数。
9. 模型正则化: L1正则化(Lasso):通过惩罚模型参数的绝对值来防止过拟合。 L2正则化(Ridge):通过惩罚模型参数的平方和来防止过拟合。 弹性网(Elastic Net):结合L1和L2正则化的优点。
10. 模型调参: 网格搜索:在给定的参数范围内,通过遍历所有可能的参数组合来找到最优参数。 随机搜索:在给定的参数范围内,随机选择参数组合来找到最优参数。 贝叶斯优化:通过构建概率模型来指导参数搜索,提高搜索效率。
以上是机器学习算法的一些主要类别及其特点。在实际应用中,需要根据具体问题选择合适的算法,并进行适当的参数调整和优化,以提高模型的性能。
一、机器学习概述

机器学习是一种使计算机系统能够从数据中学习并做出决策或预测的技术。它主要分为监督学习、无监督学习和半监督学习三大类。
二、监督学习算法
监督学习算法通过已有的输入输出数据对来训练模型,以便对新的数据做出预测。
2.1 线性回归
线性回归是一种简单的监督学习算法,用于预测连续值。它通过找到输入变量和输出变量之间的线性关系来预测目标值。
2.2 逻辑回归
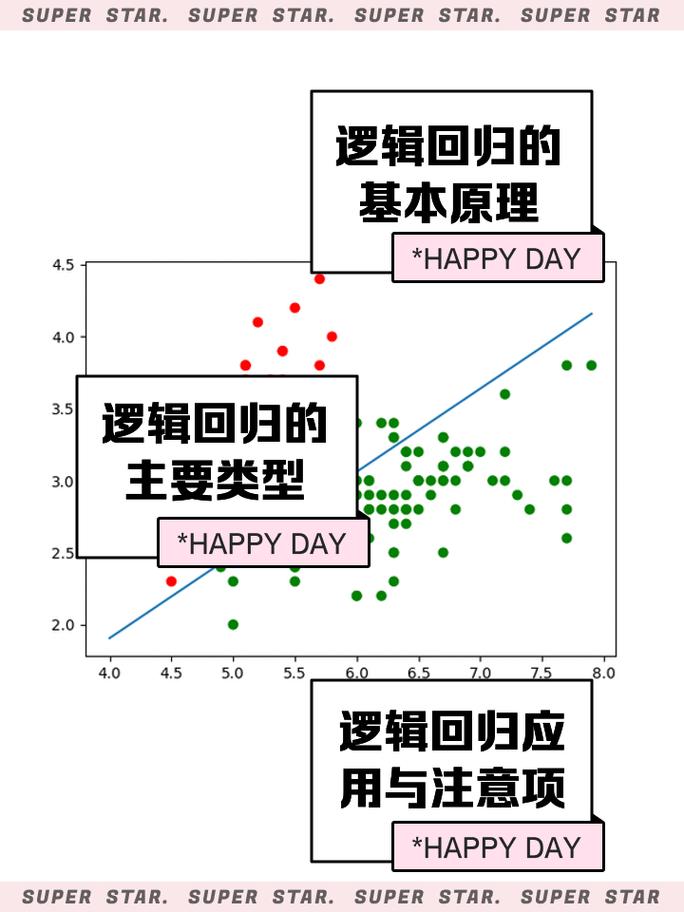
逻辑回归是一种用于预测离散值的监督学习算法,通常用于二分类问题。它通过计算输入变量与输出变量之间的概率来预测目标类别。
2.3 决策树

决策树是一种树形结构的机器学习算法,通过一系列的决策规则来预测目标变量的值。常见的决策树算法包括ID3、C4.5和CART等。
2.4 随机森林
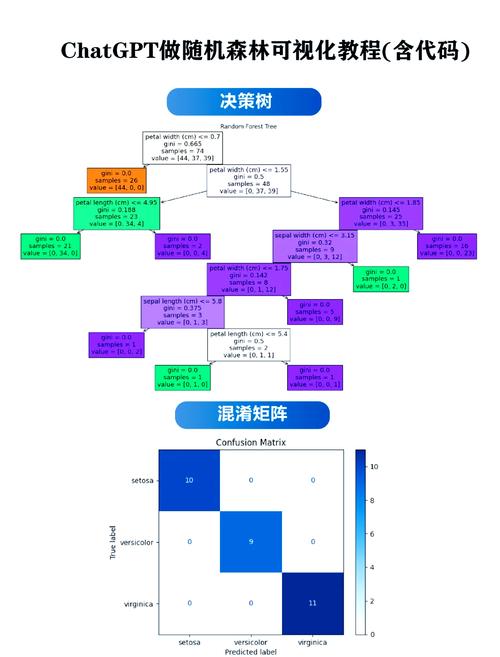
随机森林是一种集成学习方法,通过构建多个决策树并综合它们的预测结果来提高预测精度。它具有较好的泛化能力和鲁棒性。
2.5 支持向量机(SVM)

支持向量机是一种二分类算法,通过找到一个最优的超平面来将数据分为两个类别。它具有较好的泛化能力和可解释性。
三、无监督学习算法
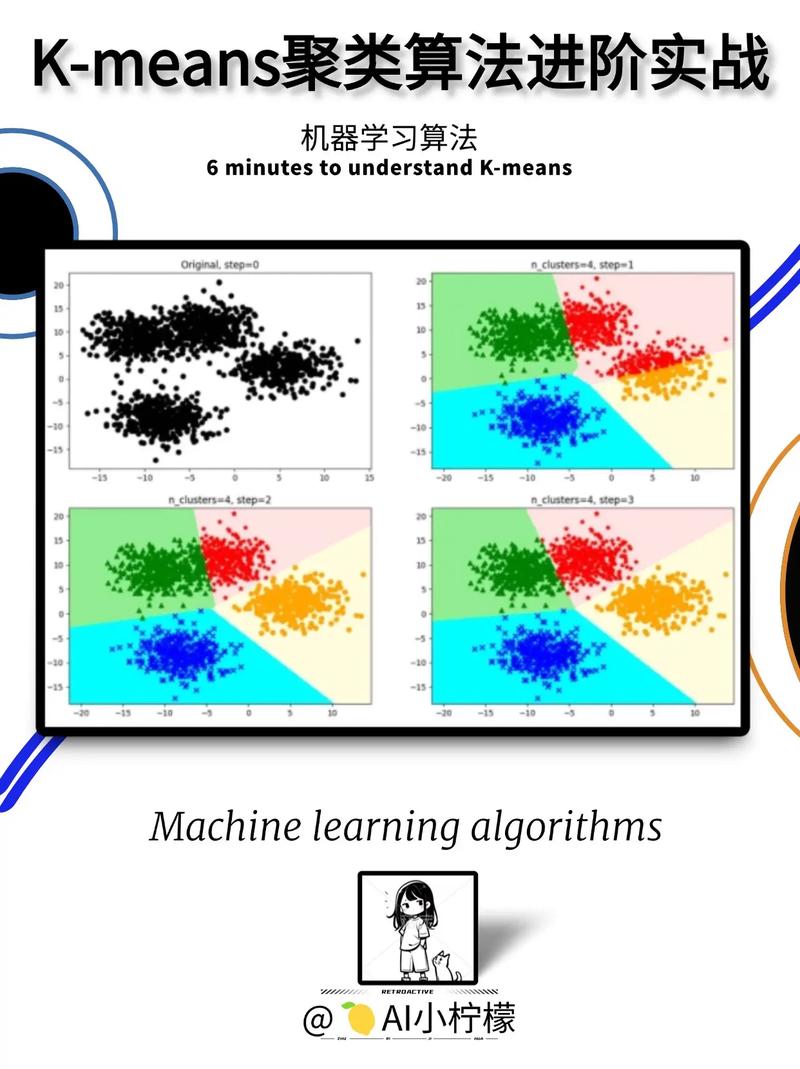
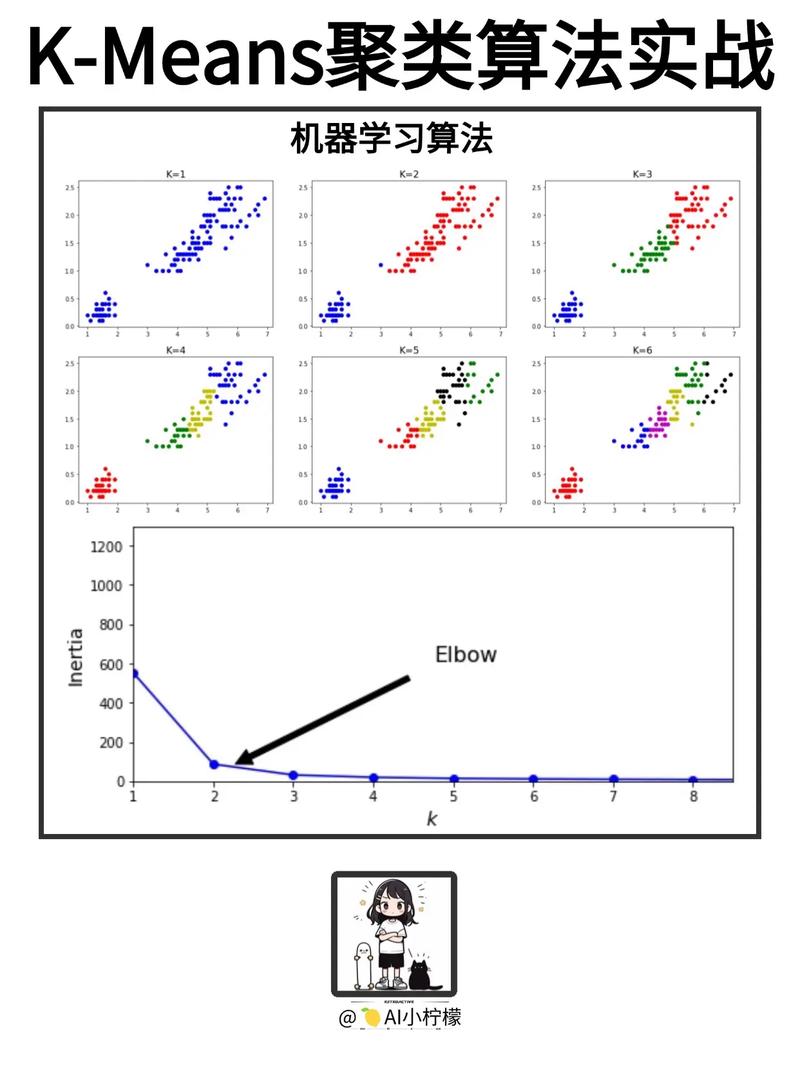
3.1 K-means聚类

K-means聚类是一种基于距离的聚类算法,通过将数据点分配到K个簇中,使得簇内数据点之间的距离最小,簇间数据点之间的距离最大。
3.2 主成分分析(PCA)

主成分分析是一种降维算法,通过将数据投影到低维空间,保留数据的主要特征,从而减少数据维度。
3.3 聚类层次分析

聚类层次分析是一种层次聚类算法,通过将数据点逐步合并成簇,形成一棵聚类树。
四、半监督学习算法

半监督学习算法结合了监督学习和无监督学习的特点,利用少量标记数据和大量未标记数据来训练模型。
4.1 自编码器
自编码器是一种无监督学习算法,通过学习输入数据的低维表示来提取特征。







