建立机器学习模型通常包括以下几个步骤:
1. 问题定义:明确你要解决的问题类型,比如是分类、回归、聚类还是异常检测等。
2. 数据收集:根据问题定义,收集相关的数据。数据可以是结构化的(如表格数据)或非结构化的(如图像、文本等)。
3. 数据预处理:对数据进行清洗、转换和规范化,使其适合机器学习模型。这可能包括处理缺失值、异常值、归一化、特征工程等。
4. 特征选择:选择对模型性能有重要影响的特征。这可以通过统计测试、模型选择等方法完成。
5. 模型选择:根据问题类型和数据的特性,选择合适的机器学习算法。常见的算法包括线性回归、决策树、支持向量机、神经网络等。
6. 模型训练:使用训练数据来训练模型。这个过程可能需要调整模型的参数,以优化模型的性能。
7. 模型评估:使用测试数据来评估模型的性能。这通常通过计算准确率、召回率、F1分数、均方误差等指标来完成。
8. 模型调优:根据模型评估的结果,调整模型的参数或选择不同的算法,以改进模型的性能。
9. 模型部署:将训练好的模型部署到生产环境中,使其能够处理实际的数据并做出预测。
10. 监控和维护:在生产环境中,定期监控模型的性能,并根据需要调整模型或重新训练模型。
建立机器学习模型是一个迭代的过程,可能需要多次调整和优化,以获得最佳的性能。
深入浅出:建立机器学习模型的全过程
随着大数据时代的到来,机器学习技术在各个领域得到了广泛应用。本文将为您详细解析建立机器学习模型的全过程,帮助您更好地理解和应用这一技术。
一、数据预处理
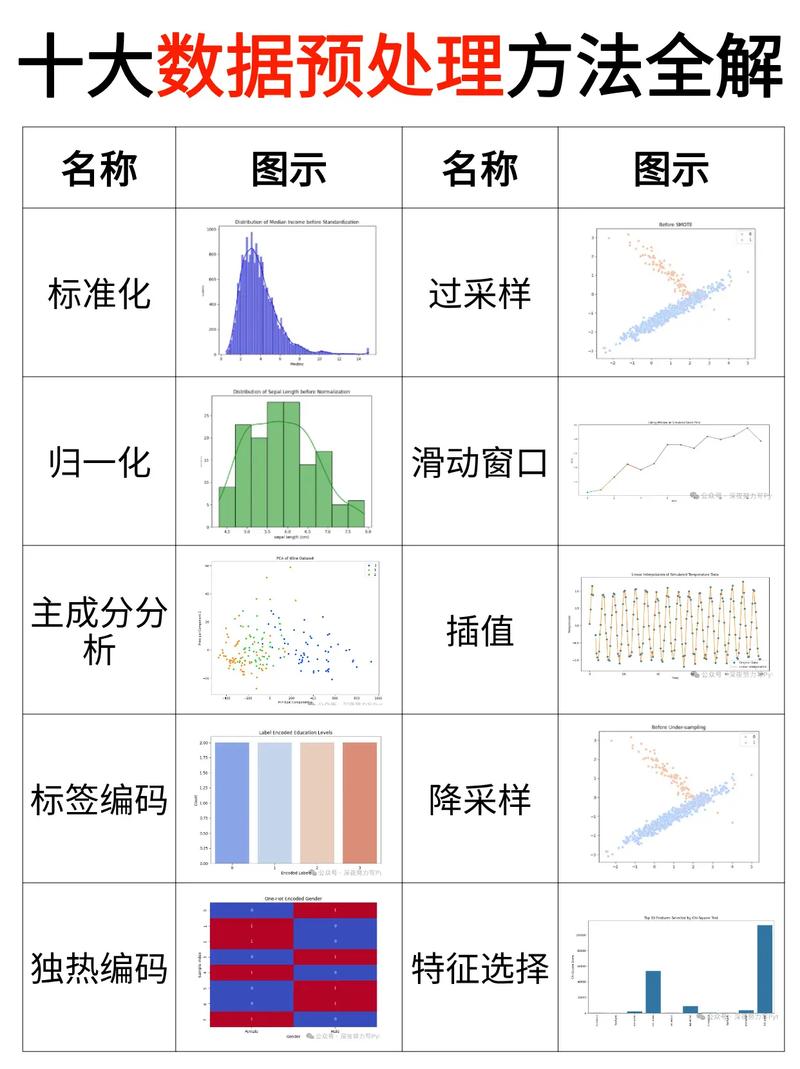
在建立机器学习模型之前,数据预处理是至关重要的步骤。这一步骤主要包括数据清洗、数据转换和数据归一化。
1. 数据清洗:原始数据往往存在缺失值、异常值和噪声,需要进行清洗。例如,删除重复数据、填充缺失值、去除异常值等。
2. 数据转换:将不同类型的数据转换为适合模型处理的形式。例如,将分类数据转换为独热编码(One-Hot Encoding),将连续数据转换为区间值等。
3. 数据归一化:将数据缩放到一个固定的范围,如[0,1]或[-1,1],以便模型更好地学习。
二、特征工程与特征选择

特征工程是机器学习模型建立过程中的关键环节,它涉及从原始数据中提取出对预测目标有用的信息。
1. 特征工程:通过手工或自动方法,从原始数据中提取出对预测目标有用的特征。例如,计算平均值、方差、最大值、最小值等统计特征,或使用主成分分析(PCA)等方法进行降维。
2. 特征选择:从提取出的特征中选择对预测目标最有影响力的特征。常用的特征选择方法包括单变量特征选择、递归特征消除(RFE)和基于模型的特征选择等。
三、模型选择与训练
1. 线性回归:适用于回归问题,通过拟合数据点与目标变量之间的线性关系进行预测。
2. 逻辑回归:适用于二分类问题,通过计算概率值进行预测。
3. 决策树:适用于分类和回归问题,通过树状结构进行预测。
4. 随机森林:基于决策树的集成学习方法,通过构建多个决策树并综合它们的预测结果进行预测。
5. 支持向量机(SVM):适用于分类和回归问题,通过寻找最佳的超平面进行预测。
6. 神经网络:适用于处理复杂数据,通过模拟人脑神经元的工作原理进行预测。
在模型选择后,需要使用训练数据对模型进行训练。训练过程中,模型会不断调整参数,以最小化预测值与真实值之间的差距。
四、模型评估与优化
1. 准确率:预测正确的样本数占总样本数的比例。
2. 精确率:预测正确的正样本数占所有预测为正样本的样本数的比例。
3. 召回率:预测正确的正样本数占所有实际为正样本的样本数的比例。
4. F1分数:精确率和召回率的调和平均值。
在评估模型后,如果发现模型性能不理想,可以尝试以下方法进行优化:
1. 调整模型参数:通过调整模型参数,如学习率、正则化项等,以提高模型性能。
2. 优化特征工程:重新进行特征工程,提取更有用的特征,以提高模型性能。
3. 尝试其他模型:尝试其他机器学习模型,比较它们的性能,选择最优模型。
本文详细介绍了建立机器学习模型的全过程,包括数据预处理、特征工程、模型选择与训练、模型评估与优化等步骤。随着机器学习技术的不断发展,相信未来会有更多高效、智能的模型应用于实际场景,为我们的生活带来更多便利。