监督学习的关键步骤包括:
1. 数据收集:收集包含输入变量和输出变量的训练数据集。2. 数据预处理:对数据进行清洗、转换和归一化,以便模型能够更好地学习。3. 模型选择:选择一个合适的机器学习模型,例如线性回归、支持向量机、决策树或神经网络。4. 模型训练:使用训练数据集训练模型,调整模型参数以最小化预测误差。5. 模型评估:使用测试数据集评估模型的性能,确保模型在未见过的数据上表现良好。6. 模型优化:根据评估结果调整模型参数或选择更合适的模型,以提高性能。
监督学习在许多领域都有广泛的应用,例如:
图像识别:训练模型识别图像中的对象、场景或活动。 自然语言处理:训练模型进行文本分类、情感分析或机器翻译。 医疗诊断:训练模型根据患者的症状和体征预测疾病。 金融预测:训练模型预测股票价格、信用风险或欺诈行为。
监督学习的关键挑战包括:
数据不平衡:训练数据集中某些类别的样本数量可能远少于其他类别,导致模型对少数类别的预测性能较差。 过拟合:模型在训练数据上表现良好,但在未见过的数据上表现较差,因为模型过度适应了训练数据的噪声。 数据隐私:训练数据可能包含敏感信息,需要在保护隐私的前提下进行学习和预测。
为了解决这些挑战,研究人员提出了许多技术和方法,例如:
数据增强:通过旋转、缩放或裁剪等方式增加训练数据的多样性。 正则化:通过限制模型参数的大小或添加惩罚项来减少过拟合。 隐私保护:使用差分隐私或联邦学习等技术保护训练数据的隐私。
监督学习是机器学习中最基本和最常用的学习方式之一,它在许多实际应用中发挥着重要作用。随着技术的不断进步,监督学习将继续发展,为各个领域带来更多创新和机遇。
什么是监督学习

监督学习的应用场景
分类问题:例如,垃圾邮件检测、情感分析、图像识别等。
回归问题:例如,房价预测、股票价格预测、用户评分预测等。
监督学习的基本流程

监督学习的基本流程通常包括以下几个步骤:
数据预处理:对数据进行清洗、归一化、特征选择等操作,以提高模型的性能。
模型选择:根据问题的类型(分类或回归)选择合适的模型。
模型评估:使用测试数据对训练好的模型进行评估,以检验模型的泛化能力。
模型优化:根据评估结果对模型进行调整,以提高模型的性能。
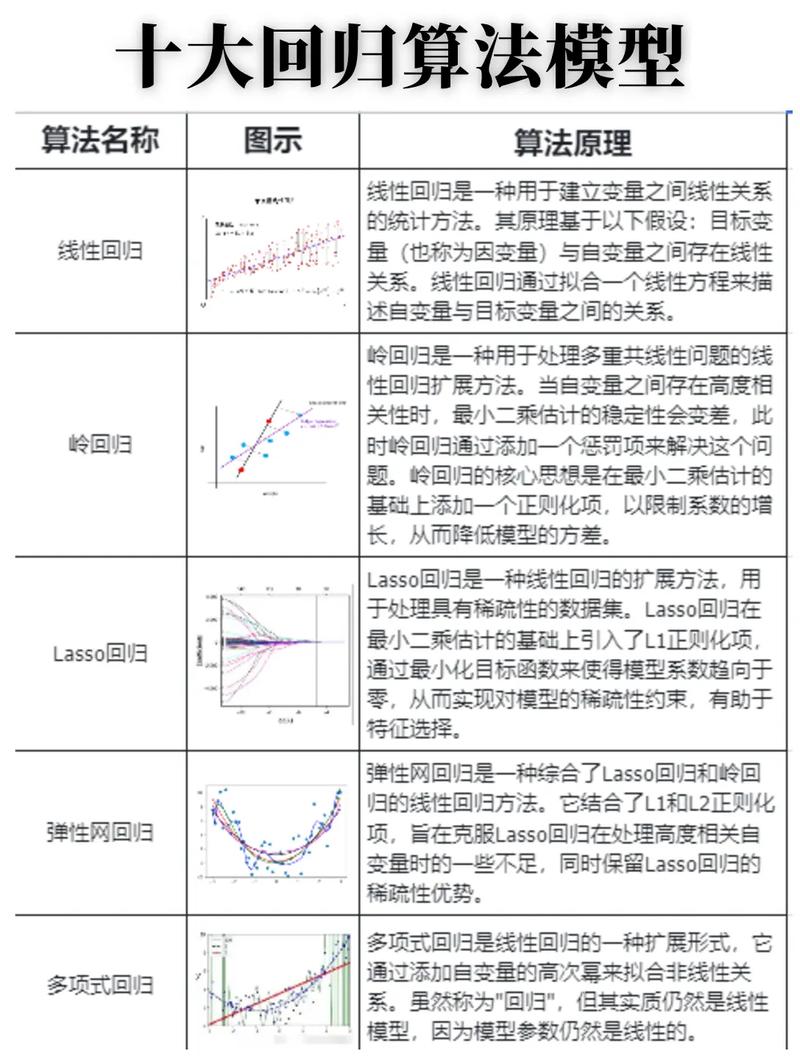
常见的监督学习算法
线性回归(Linear Regression):用于回归问题,通过线性关系预测连续值。
逻辑回归(Logistic Regression):用于分类问题,通过逻辑函数预测概率。
支持向量机(Support Vector Machine,SVM):用于分类和回归问题,通过寻找最优的超平面来划分数据。
决策树(Decision Tree):用于分类和回归问题,通过树形结构对数据进行划分。
随机森林(Random Forest):通过集成多个决策树来提高模型的性能。
梯度提升树(Gradient Boosting Trees,GBDT):通过迭代优化来提高模型的性能。
监督学习的挑战

尽管监督学习在许多领域取得了显著的成果,但仍然存在一些挑战:
数据标注成本高:在监督学习中,需要大量标注数据来训练模型,而数据标注通常需要人工完成,成本较高。
数据不平衡:在某些应用场景中,训练数据集中正负样本的比例可能不平衡,这会影响模型的性能。
过拟合:当模型在训练数据上表现良好,但在测试数据上表现不佳时,可能发生了过拟合现象。
监督学习 机器学习 分类 回归 算法 数据预处理 模型评估 挑战