
1. 监督学习:监督学习是一种机器学习方法,它使用标记的训练数据来训练模型,以便模型能够对未标记的数据进行预测。监督学习可以分为两类:分类和回归。2. 非监督学习:非监督学习是一种机器学习方法,它使用未标记的数据来训练模型,以便模型能够发现数据中的模式和结构。非监督学习可以分为两类:聚类和降维。3. 半监督学习:半监督学习是一种机器学习方法,它使用标记和未标记的数据来训练模型,以便模型能够从标记数据中学习,同时从未标记数据中获取更多的信息。4. 强化学习:强化学习是一种机器学习方法,它通过与环境交互来学习最优策略。强化学习通常用于解决决策问题,如游戏、机器人控制等。5. 决策树:决策树是一种用于分类和回归的机器学习算法。它通过一系列的决策规则来对数据进行分类或回归。6. 随机森林:随机森林是一种集成学习算法,它通过构建多个决策树并取它们的平均值来提高模型的准确性和泛化能力。7. 支持向量机(SVM):支持向量机是一种用于分类和回归的机器学习算法。它通过寻找一个超平面来最大化不同类别之间的间隔,从而实现分类或回归。8. 神经网络:神经网络是一种模拟人脑神经元结构的机器学习算法。它由多个层组成,每层包含多个神经元,通过前向传播和反向传播算法来训练模型。9. 深度学习:深度学习是一种基于神经网络的机器学习方法,它使用多层神经网络来学习数据中的复杂模式和结构。深度学习在图像识别、自然语言处理等领域取得了显著的成果。
这些只是机器学习技法中的一部分,还有许多其他的算法和技术可以用于解决不同的问题。选择合适的技法取决于问题的类型、数据的特性和模型的性能要求。
机器学习技法概述
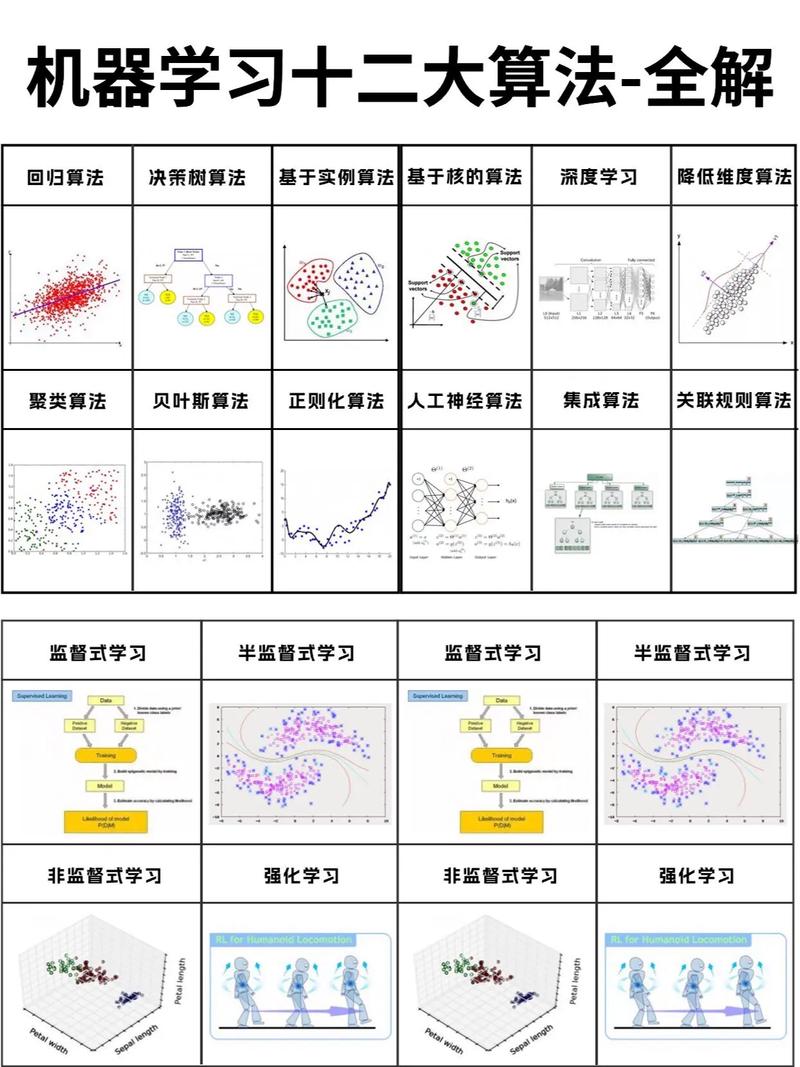
随着大数据时代的到来,机器学习技术在各个领域得到了广泛应用。机器学习技法是机器学习领域的一个重要分支,它涵盖了从数据预处理到模型评估的整个过程。本文将详细介绍机器学习技法的基本概念、常用方法和应用场景。
数据预处理
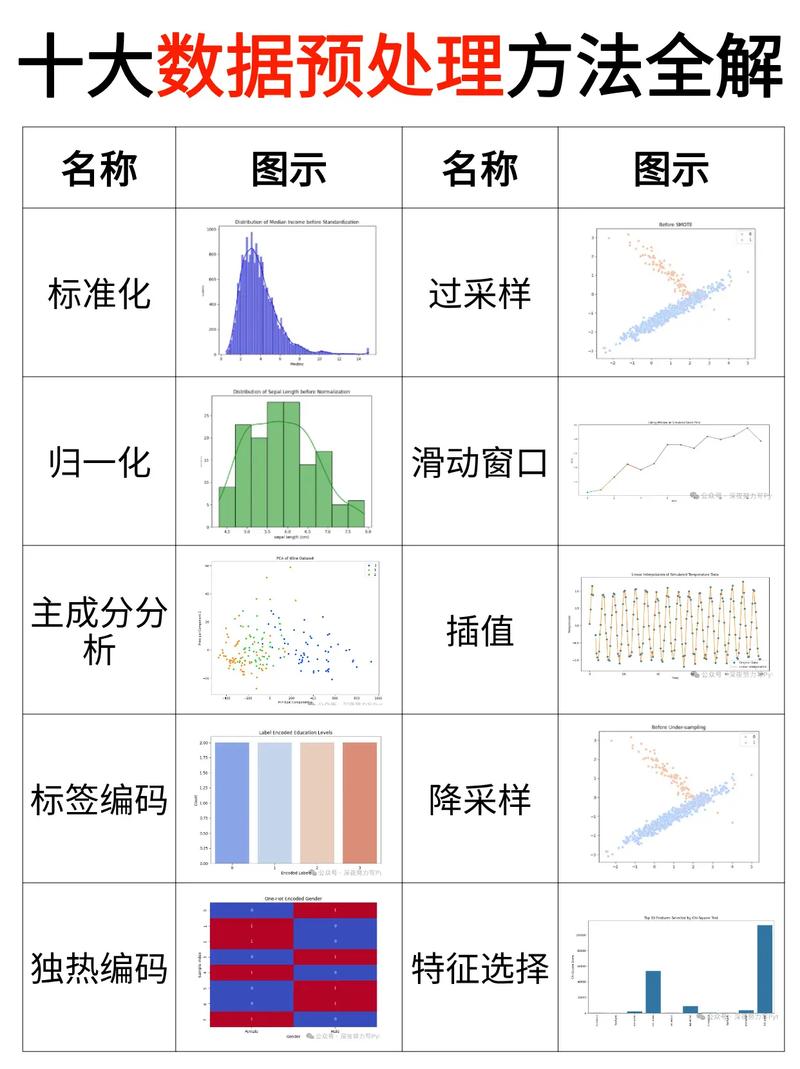
数据预处理是机器学习过程中的第一步,其目的是提高数据质量,为后续的模型训练提供良好的数据基础。数据预处理主要包括以下步骤:
数据清洗:去除重复数据、处理缺失值、纠正错误数据等。
数据转换:将不同类型的数据转换为同一类型,如将类别型数据转换为数值型数据。
特征工程:通过特征选择、特征提取等方法,从原始数据中提取出对模型训练有帮助的特征。
特征选择与提取
特征选择和提取是机器学习技法中的关键环节,它们直接影响着模型的性能。以下是几种常用的特征选择和提取方法:
特征选择:通过评估特征的重要性,选择对模型训练有帮助的特征。
特征提取:通过将原始数据转换为新的特征,提高模型的性能。
主成分分析(PCA):通过降维,将原始数据转换为新的特征空间。
特征嵌入:将原始数据转换为低维空间,同时保留原始数据的结构。
模型训练

模型训练是机器学习技法中的核心环节,其目的是通过学习数据中的规律,构建出能够对未知数据进行预测的模型。以下是几种常用的模型训练方法:
监督学习:通过已知的输入和输出数据,学习出输入和输出之间的关系。
无监督学习:通过分析数据中的规律,发现数据中的隐藏结构。
半监督学习:结合监督学习和无监督学习,利用少量标注数据和大量未标注数据。
强化学习:通过与环境交互,学习出最优策略。
模型评估
模型评估是机器学习技法中的关键环节,其目的是评估模型的性能,为后续的模型优化提供依据。以下是几种常用的模型评估方法:
准确率:模型预测正确的样本数与总样本数的比值。
召回率:模型预测正确的正样本数与实际正样本数的比值。
F1值:准确率和召回率的调和平均值。
ROC曲线:通过绘制不同阈值下的真阳性率与假阳性率曲线,评估模型的性能。
常见机器学习算法

在机器学习技法中,有许多经典的算法,以下列举几种常见的算法:
线性回归:通过学习输入和输出之间的关系,预测连续值。
逻辑回归:通过学习输入和输出之间的关系,预测离散值。
支持向量机(SVM):通过寻找最优的超平面,将不同类别的数据分开。
决策树:通过递归地划分数据,构建出决策树模型。
随机森林:通过集成多个决策树,提高模型的性能。
机器学习技法是机器学习领域的一个重要分支,它涵盖了从数据预处理到模型评估的整个过程。掌握机器学习技法,有助于我们更好地理解和应用机器学习技术。本文对机器学习技法的基本概念、常用方法和应用场景进行了简要介绍,希望对读者有所帮助。








