基础知识
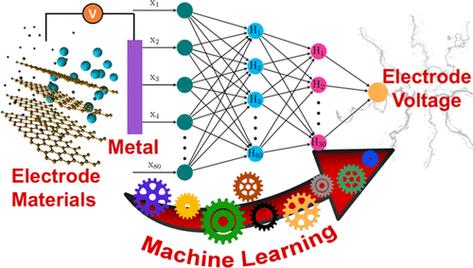
1. 定义机器学习 机器学习是使计算机系统能够从数据中学习并做出决策或预测的科学。
算法理解
1. 线性回归 目标:找到最佳的线性关系来预测连续值。 算法:最小二乘法。
2. 逻辑回归 目标:预测二分类问题。 算法:使用Sigmoid函数将线性模型的结果转换为概率。
3. 决策树 目标:通过树状结构进行分类或回归。 算法:ID3、C4.5、CART等。
4. 支持向量机(SVM) 目标:找到最佳的超平面来分隔不同类别的数据。 算法:核技巧。
实践经验
1. 项目经验 描述你参与过的机器学习项目,包括数据收集、预处理、模型选择、训练、评估和部署。
2. 问题解决 描述你如何解决项目中遇到的问题,例如过拟合、欠拟合、数据不平衡等。
编程能力
1. 编程语言 熟悉Python、R、Java等编程语言,特别是Python在机器学习领域的应用。
2. 数据处理 熟悉Pandas、NumPy等数据处理库。
3. 机器学习库 熟悉Scikitlearn、TensorFlow、PyTorch等机器学习库。
问题解决能力
1. 特征工程 描述你如何选择和构建特征以提高模型性能。
2. 模型评估 描述你如何评估模型的性能,包括准确率、召回率、F1分数、AUCROC等指标。
3. 模型调优 描述你如何调整模型参数以提高性能,包括网格搜索、随机搜索、贝叶斯优化等。
示例问题
1. 什么是过拟合?如何避免过拟合? 过拟合是指模型在训练数据上表现很好,但在新数据上表现不佳。 避免过拟合的方法包括:增加数据量、使用正则化、简化模型、交叉验证等。
2. 什么是交叉验证? 交叉验证是一种评估模型泛化能力的方法,将数据分为k个部分,轮流使用k1部分作为训练集,剩余部分作为验证集。
3. 如何处理不平衡的数据集? 处理不平衡数据集的方法包括:过采样、欠采样、合成样本、使用不同的损失函数等。
准备建议
1. 复习基础知识 确保你对机器学习的基本概念和算法有深入的理解。
2. 实践项目 参与实际项目,将理论知识应用到实践中。
3. 编写代码 练习编写代码,特别是使用机器学习库进行数据处理和模型训练。
4. 阅读论文 阅读最新的机器学习论文,了解最新的研究进展。
5. 模拟面试 进行模拟面试,提高你的面试技巧和自信心。
机器学习面试攻略:全面解析常见问题及应对策略
一、面试前的准备

- 基础知识复习:确保你对机器学习的基本概念、算法和理论有深入的理解。
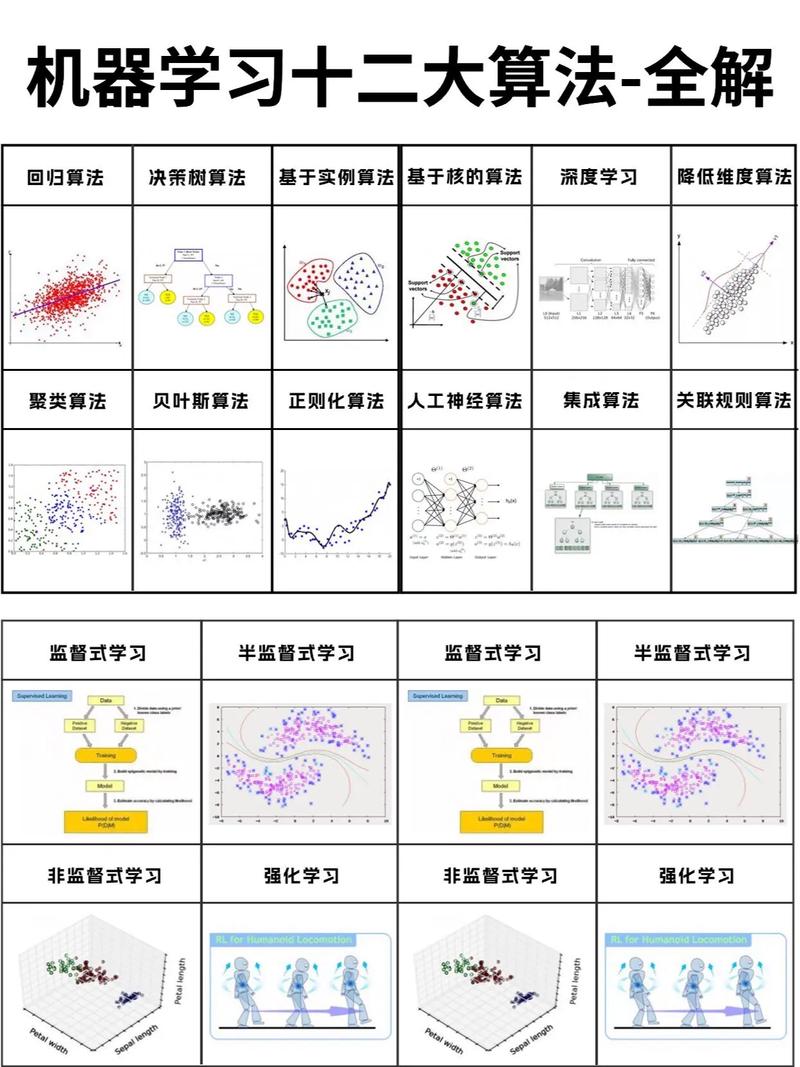
- 项目经验梳理:回顾你的项目经验,准备好能够详细描述你的角色、所使用的技术和取得的成果。

- 编程能力提升:熟悉至少一种编程语言,如Python,并掌握常用的机器学习库,如scikit-learn、TensorFlow或PyTorch。

- 了解行业动态:关注最新的机器学习研究进展和行业应用案例。
二、常见面试问题及解答

2.1 机器学习基础

问题:请解释一下什么是机器学习。
解答:机器学习是一种使计算机系统能够从数据中学习并做出决策或预测的技术。它通过算法分析数据,从中提取模式和知识,从而改进系统性能。

2.2 算法与模型
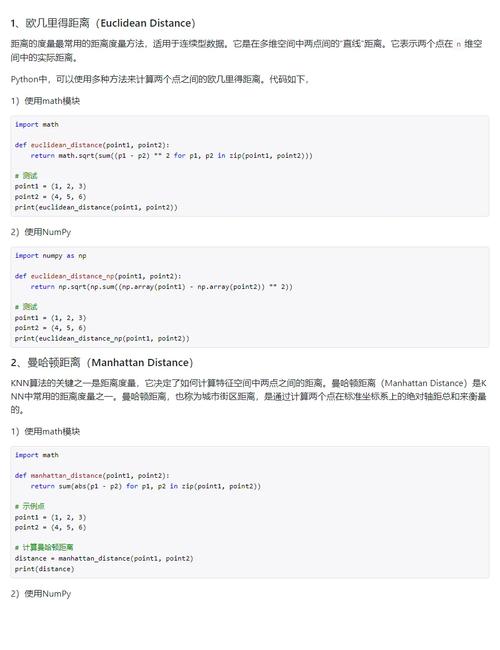
问题:K近邻算法(KNN)是如何工作的?请举例说明其应用场景。

解答:K近邻算法是一种基于实例的学习算法。它通过计算新数据点与训练集中数据点的距离,并将新数据点分配给最近的K个邻居,从而预测新数据点的类别。例如,在招聘场景中,可以预测候选人是否能拿到Offer。

2.3 特征工程与选择
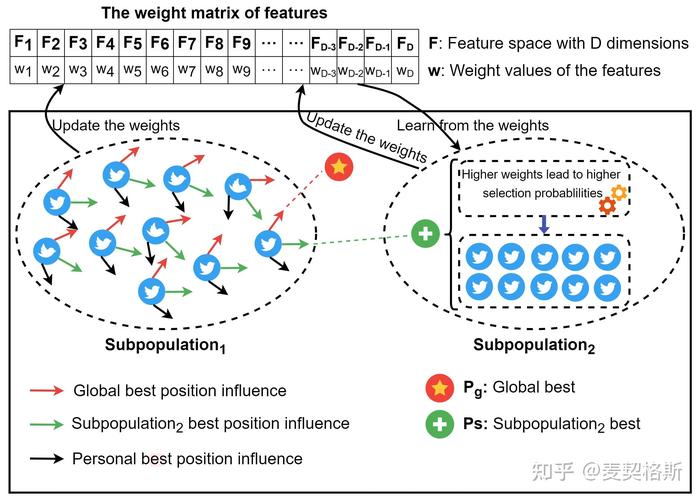
问题:特征选择和特征提取有什么区别?请举例说明。
解答:特征选择是在原始特征集中选择最有用的特征,而特征提取则是通过变换原始特征来生成新的特征。例如,主成分分析(PCA)是一种特征提取方法,它通过线性变换将原始特征转换为新的特征空间。

2.4 模型评估与优化
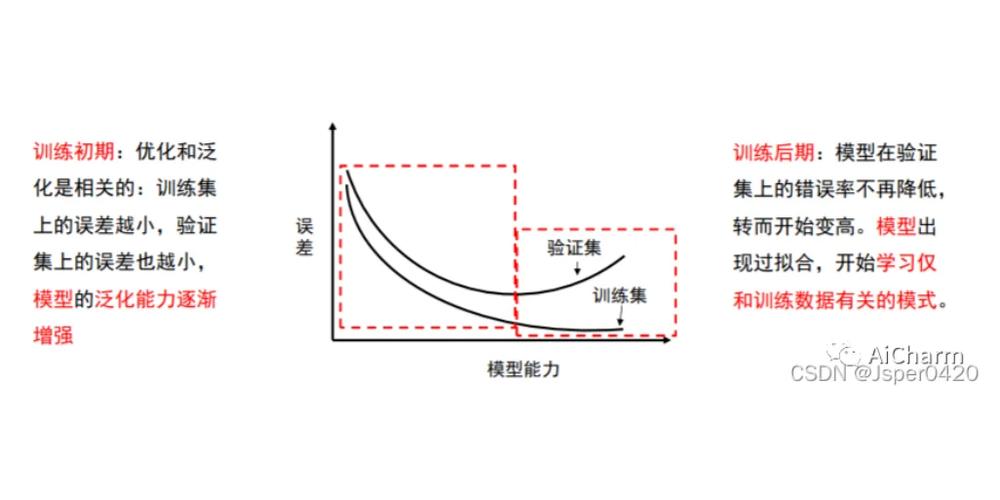
问题:如何解决过拟合问题?请列举几种常用的方法。

解答:过拟合是指模型在训练数据上表现良好,但在测试数据上表现不佳。解决过拟合的方法包括:增加数据量、使用正则化、简化模型、交叉验证等。
三、实际案例分析
- 选择合适的项目:选择一个你熟悉且能够详细描述的项目。

- 突出你的贡献:强调你在项目中扮演的角色和所取得的成果。
- 展示解决问题的能力:描述你在项目中遇到的问题以及你是如何解决的。

四、面试技巧与注意事项
- 保持自信:相信自己的能力,并展现出你的热情和积极性。
- 清晰表达:用简洁明了的语言描述你的想法和解决方案。
- 提问环节:不要害怕提问,这可以展示你对问题的关注和思考。
- 着装得体:选择合适的着装,以展现出你的专业形象。
机器学习面试是一个挑战,但通过充分的准备和良好的应对策略,你可以提高自己的竞争力。记住,保持自信、清晰表达和展示你的实际能力是关键。