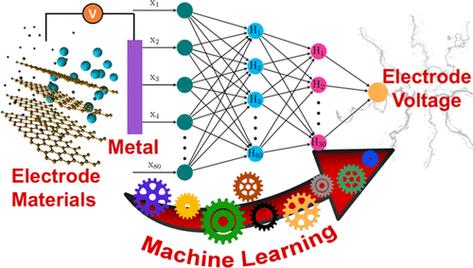
数据挖掘和机器学习是两个紧密相关但又有区别的概念。它们在人工智能领域都扮演着重要的角色,但侧重点和应用场景有所不同。
数据挖掘(Data Mining)是一种从大量数据中提取有用信息的过程。它通常涉及对数据进行预处理、探索、建模和解释。数据挖掘的目标是发现数据中的模式和关系,这些模式和关系可以用于预测、决策支持、知识发现等。数据挖掘通常使用统计方法、机器学习算法和其他数据分析技术来识别数据中的模式和趋势。
机器学习(Machine Learning)是一种使计算机能够自动学习并执行特定任务的技术。它涉及到使用算法和统计模型来使计算机能够从数据中学习,并基于这些学习到的知识做出决策或预测。机器学习通常被用于分类、回归、聚类、推荐系统等任务。
区别:
1. 目标:数据挖掘的目标是发现数据中的模式和关系,而机器学习的目标是使计算机能够自动学习并执行特定任务。2. 方法:数据挖掘通常使用统计方法、机器学习算法和其他数据分析技术,而机器学习主要使用算法和统计模型。3. 应用:数据挖掘通常用于预测、决策支持、知识发现等,而机器学习通常用于分类、回归、聚类、推荐系统等任务。
尽管数据挖掘和机器学习在目标、方法和应用上有所不同,但它们在实际应用中经常结合使用。例如,数据挖掘可以用于从数据中提取有用的特征,而机器学习可以用于基于这些特征进行预测或分类。
数据挖掘与机器学习的区别:深入解析两者的异同

在当今数据驱动的世界中,数据挖掘和机器学习是两个经常被提及且紧密相关的术语。尽管它们的目标相似,但在实现方式和应用场景上存在显著差异。本文将深入探讨数据挖掘与机器学习的区别,帮助读者更好地理解这两个领域。
定义

数据挖掘(Data Mining)是指从大量数据中提取有价值信息的过程。它涉及数据的预处理、分析、解释和模式识别,旨在发现数据中的隐藏模式、关联性和规则。数据挖掘的目标是帮助决策者从数据中获取洞察力,支持决策制定和业务优化。
目标

数据挖掘的主要目标是发现数据中的潜在模式,这些模式可以用于预测、分类、聚类、关联分析等。通过数据挖掘,企业可以更好地了解客户需求、市场趋势和业务风险。
常用方法

数据挖掘常用的方法包括关联规则挖掘、聚类分析、分类、预测分析、异常检测等。这些方法通常需要大量的数据预处理和特征工程。
定义
机器学习(Machine Learning)是计算机科学和统计学的交叉学科,旨在使计算机系统能够从数据中学习并做出决策或预测,而无需显式编程。机器学习算法通过分析数据,自动从数据中学习模式和规律,并利用这些模式进行预测或决策。
目标
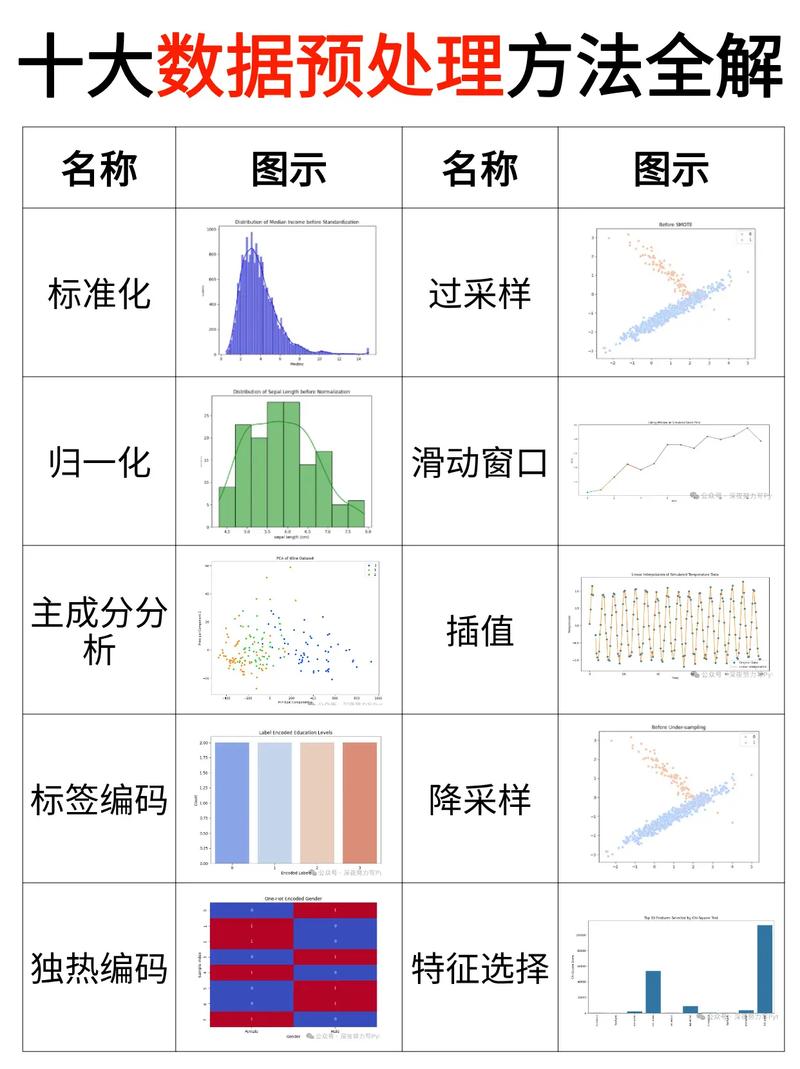
机器学习的主要目标是开发能够从数据中学习并自动做出决策或预测的算法。这些算法可以应用于各种领域,如自然语言处理、图像识别、推荐系统等。
常用方法

机器学习常用的方法包括监督学习、无监督学习、半监督学习和强化学习。这些方法通常需要大量的数据训练和模型调优。
数据挖掘与机器学习的区别
数据来源
数据挖掘通常从大量结构化或半结构化数据中提取信息,如数据库、日志文件等。而机器学习可以从各种数据源中学习,包括文本、图像、音频和视频等。
数据预处理
数据挖掘通常需要大量的数据预处理工作,如数据清洗、特征工程等。而机器学习算法在处理数据时,可能需要更少的预处理工作。
目标
数据挖掘的目标是发现数据中的潜在模式,而机器学习的目标是开发能够从数据中学习并自动做出决策或预测的算法。
应用场景
数据挖掘通常用于商业智能、市场分析、客户关系管理等场景。而机器学习算法可以应用于更广泛的领域,如自然语言处理、图像识别、推荐系统等。
数据挖掘和机器学习是两个紧密相关的领域,它们在目标和应用场景上存在差异。数据挖掘侧重于从数据中提取有价值的信息,而机器学习则侧重于开发能够从数据中学习并自动做出决策或预测的算法。了解这两个领域的区别有助于我们更好地利用数据和技术,推动业务发展和创新。