
机器学习数据分析项目通常包括以下几个步骤:
1. 问题定义:明确项目目标,确定需要解决的问题。这包括理解业务需求、明确项目范围和预期成果。
2. 数据收集:根据问题定义,收集相关数据。数据可以来自多种来源,如数据库、API、文件等。
3. 数据预处理:对收集到的数据进行清洗、转换和归一化。这包括处理缺失值、异常值、重复数据等。
4. 特征工程:从原始数据中提取或创建新的特征,以增强模型的学习能力。
5. 模型选择:根据问题类型(如分类、回归、聚类等)选择合适的机器学习模型。
6. 模型训练:使用训练数据集对模型进行训练,调整模型参数以优化性能。
7. 模型评估:使用验证数据集或测试数据集评估模型的性能,包括准确率、召回率、F1分数等指标。
8. 模型部署:将训练好的模型部署到生产环境中,以便在实际应用中使用。
9. 监控和维护:对部署的模型进行监控,确保其性能稳定。根据需要进行模型更新或重新训练。
在整个项目过程中,需要使用各种工具和技术,如Python、R、SQL、数据可视化工具、机器学习库(如scikitlearn、TensorFlow、PyTorch)等。此外,还需要考虑数据隐私、安全性和合规性等问题。
机器学习数据分析项目实战:从数据预处理到模型评估
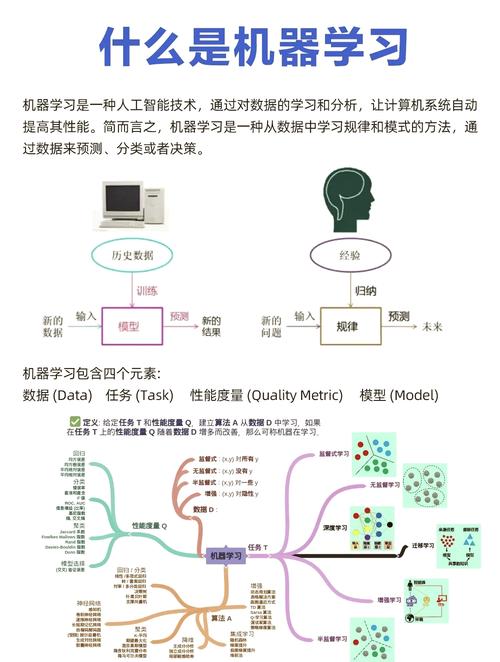
随着大数据时代的到来,机器学习在数据分析中的应用越来越广泛。本文将详细介绍一个机器学习数据分析项目的实战过程,包括数据预处理、特征工程、模型选择、训练与评估等关键步骤。
一、项目背景与目标
项目背景:某电商平台希望通过分析用户购买行为数据,预测用户是否会购买某款商品,从而实现精准营销。
项目目标:构建一个机器学习模型,能够准确预测用户购买行为,提高营销效果。
二、数据预处理
数据预处理是机器学习项目中的关键步骤,它包括数据清洗、数据转换和数据集成等。
1. 数据清洗
在数据清洗阶段,我们需要处理缺失值、异常值和重复值等问题。
(1)缺失值处理:对于缺失值,我们可以采用填充、删除或插值等方法进行处理。
(2)异常值处理:通过可视化或统计方法识别异常值,并对其进行处理。
(3)重复值处理:删除重复数据,避免模型过拟合。
2. 数据转换
数据转换包括数值型数据转换和类别型数据转换。
(1)数值型数据转换:对数值型数据进行标准化、归一化或离散化处理。
3. 数据集成
将预处理后的数据集进行整合,为后续建模做准备。
三、特征工程

特征工程是提高模型性能的关键环节,它包括特征选择、特征提取和特征组合等。
1. 特征选择
通过统计方法、模型选择或递归特征消除等方法,选择对模型预测有重要影响的特征。
2. 特征提取
从原始数据中提取新的特征,提高模型的预测能力。
3. 特征组合
将多个特征组合成新的特征,以增强模型的预测能力。
四、模型选择与训练

根据项目需求和数据特点,选择合适的机器学习模型,并进行训练。
1. 模型选择
根据项目背景和目标,选择合适的机器学习模型,如逻辑回归、决策树、支持向量机、随机森林等。
2. 模型训练
使用预处理后的数据集对模型进行训练,调整模型参数,提高模型性能。
五、模型评估与优化
对训练好的模型进行评估,并根据评估结果进行优化。
1. 模型评估
使用交叉验证、混淆矩阵、ROC曲线等方法对模型进行评估。
2. 模型优化
根据评估结果,调整模型参数或尝试其他模型,以提高模型性能。
本文详细介绍了机器学习数据分析项目的实战过程,从数据预处理到模型评估,每个步骤都进行了详细阐述。通过实际操作,我们可以更好地理解机器学习在数据分析中的应用,为后续项目提供参考。








