
1. 监督学习 a. 简述线性回归的基本原理。 b. 解释支持向量机(SVM)的工作原理,并说明如何处理非线性问题。 c. 描述决策树分类器的基本概念,并解释如何通过剪枝来防止过拟合。 d. 比较K近邻(KNN)和朴素贝叶斯分类器的优缺点。
2. 无监督学习 a. 解释K均值聚类算法的基本原理,并说明如何选择合适的K值。 b. 描述层次聚类算法的基本步骤,并解释其优缺点。 c. 简述主成分分析(PCA)的基本原理,并说明如何应用于降维。 d. 比较自组织映射(SOM)和自编码器在特征学习方面的差异。
3. 强化学习 a. 简述马尔可夫决策过程(MDP)的基本概念。 b. 解释Q学习算法的工作原理,并说明如何处理探索与利用的平衡问题。 c. 描述深度Q网络(DQN)的基本概念,并说明如何解决函数逼近问题。 d. 比较策略梯度方法和Q学习方法在强化学习中的应用。
4. 深度学习 a. 简述卷积神经网络(CNN)的基本结构,并说明其在图像识别任务中的优势。 b. 描述循环神经网络(RNN)的基本概念,并解释其在处理序列数据时的特点。 c. 简述生成对抗网络(GAN)的基本原理,并说明其在生成模型中的应用。 d. 比较全连接神经网络和卷积神经网络在处理图像数据时的差异。
5. 机器学习应用 a. 描述机器学习在推荐系统中的应用,并解释协同过滤和内容过滤的原理。 b. 简述机器学习在自然语言处理(NLP)中的应用,如情感分析、机器翻译等。 c. 描述机器学习在计算机视觉中的应用,如目标检测、图像分割等。 d. 简述机器学习在医疗诊断中的应用,如疾病预测、药物发现等。
请注意,这些试题只是机器学习领域的一些基本概念和应用。实际上,机器学习是一个广泛的领域,涉及到许多复杂的概念和技术。如果你需要更深入的学习,我建议你查阅相关的教材、论文和在线资源。
机器学习试题解析与学习指南
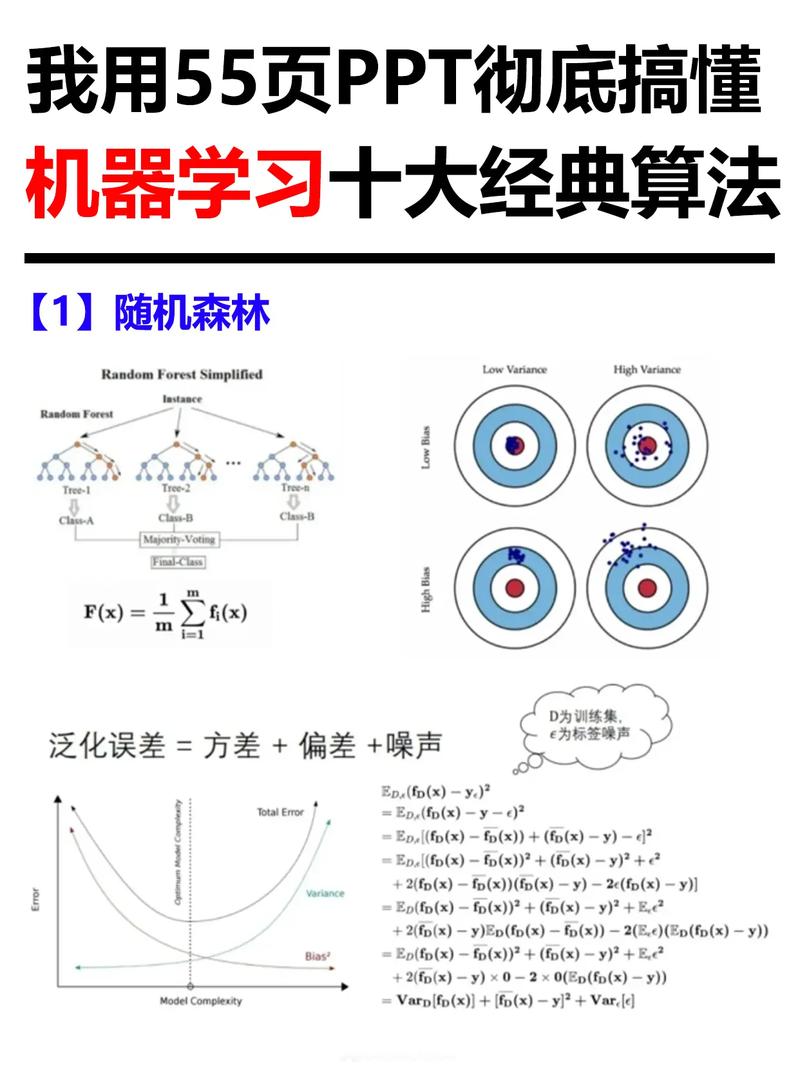
一、选择题

1. 以下哪项不是机器学习的类型?
A. 监督学习
B. 无监督学习
C. 强化学习
D. 神经网络学习
答案:D
解析:神经网络学习是机器学习的一种实现方式,而不是机器学习的一种类型。机器学习的类型主要包括监督学习、无监督学习和强化学习。
二、填空题

2. 在监督学习中,输入数据的特征向量通常表示为______。
答案:特征向量
解析:在监督学习中,每个输入数据都对应一个特征向量,它包含了该数据的多维特征信息。
三、简答题

3. 简述K-means聚类算法的基本步骤。
答案:
(1)初始化:随机选择K个数据点作为初始聚类中心。
(2)分配:将每个数据点分配到最近的聚类中心所在的簇中。
(3)更新:计算每个簇的新聚类中心,即该簇中所有数据点的均值。
(4)重复步骤(2)和(3),直到聚类中心不再发生变化或达到预设的迭代次数。
解析:K-means聚类算法是一种基于距离的聚类方法,通过迭代优化聚类中心,将数据点划分为K个簇。
四、论述题

4. 论述Q-learning算法的基本原理及其在智能体决策中的应用。
答案:
Q-learning是一种基于值函数的强化学习算法,其基本原理如下:
(1)初始化:初始化Q值表,将所有Q值初始化为0。
(2)选择动作:根据当前状态和Q值表,选择一个动作。
(3)更新Q值:根据实际获得的奖励和下一个状态,更新Q值表。
(4)状态转移:根据选择的动作,转移到下一个状态。
(5)重复步骤(2)至(4),直到达到终止状态或达到预设的迭代次数。
解析:Q-learning算法通过学习值函数,使智能体在面临决策时能够选择最优动作,从而实现智能体的自主学习和决策。
五、案例分析

5. 举例说明机器学习在推荐系统中的应用。
答案:
推荐系统是一种常见的机器学习应用,其目的是为用户推荐他们可能感兴趣的商品、电影、音乐等。以下是一个简单的推荐系统案例:
(1)收集用户的历史行为数据,如浏览记录、购买记录等。
(2)使用协同过滤算法,根据用户的历史行为数据,找到与目标用户相似的用户。
(3)根据相似用户的喜好,为目标用户推荐相应的商品。
解析:通过机器学习算法,推荐系统可以有效地为用户提供个性化的推荐,提高用户满意度和系统价值。
本文提供了一系列机器学习试题,并对其中一些典型题目进行了详细解析。通过学习和掌握这些试题,读者可以更好地理解和应用机器学习算法。在实际应用中,不断积累经验和知识,才能在人工智能领域取得更好的成果。








