
1. 监督学习算法: 线性回归:预测连续数值。 逻辑回归:用于二分类问题。 决策树:基于特征值的条件进行决策。 支持向量机(SVM):通过找到一个超平面来最大化不同类别之间的间隔。 随机森林:多个决策树的集合,用于提高预测的准确性和稳定性。 集成方法:如Bagging和Boosting,通过结合多个模型来提高性能。
2. 无监督学习算法: K均值聚类:将数据分为K个簇。 层次聚类:构建一个层次结构来表示数据中的相似性。 主成分分析(PCA):通过降维来减少数据集的维度。 自组织映射(SOM):一种神经网络,用于聚类和可视化高维数据。 高斯混合模型(GMM):一种概率模型,用于聚类和密度估计。
3. 强化学习算法: Q学习:一种无模型的学习方法,用于在马尔可夫决策过程中找到最优策略。 深度Q网络(DQN):结合了深度学习和Q学习,用于解决复杂的环境问题。 政策梯度方法:直接优化策略参数,而不是值函数。 模型预测控制(MPC):一种基于模型的控制方法,用于在动态环境中进行决策。
4. 深度学习算法: 前馈神经网络:一种基本的神经网络结构,用于分类和回归任务。 卷积神经网络(CNN):特别适用于图像识别和自然语言处理。 循环神经网络(RNN):用于处理序列数据,如时间序列和文本。 长短期记忆网络(LSTM):一种特殊的RNN,能够学习长期依赖关系。 生成对抗网络(GAN):由生成器和判别器组成,用于生成新的数据样本。
这些算法只是机器学习领域的一部分,每个算法都有其特定的应用场景和优缺点。选择合适的算法取决于问题的性质、数据的特点和预期的性能指标。
机器学习主要算法概述
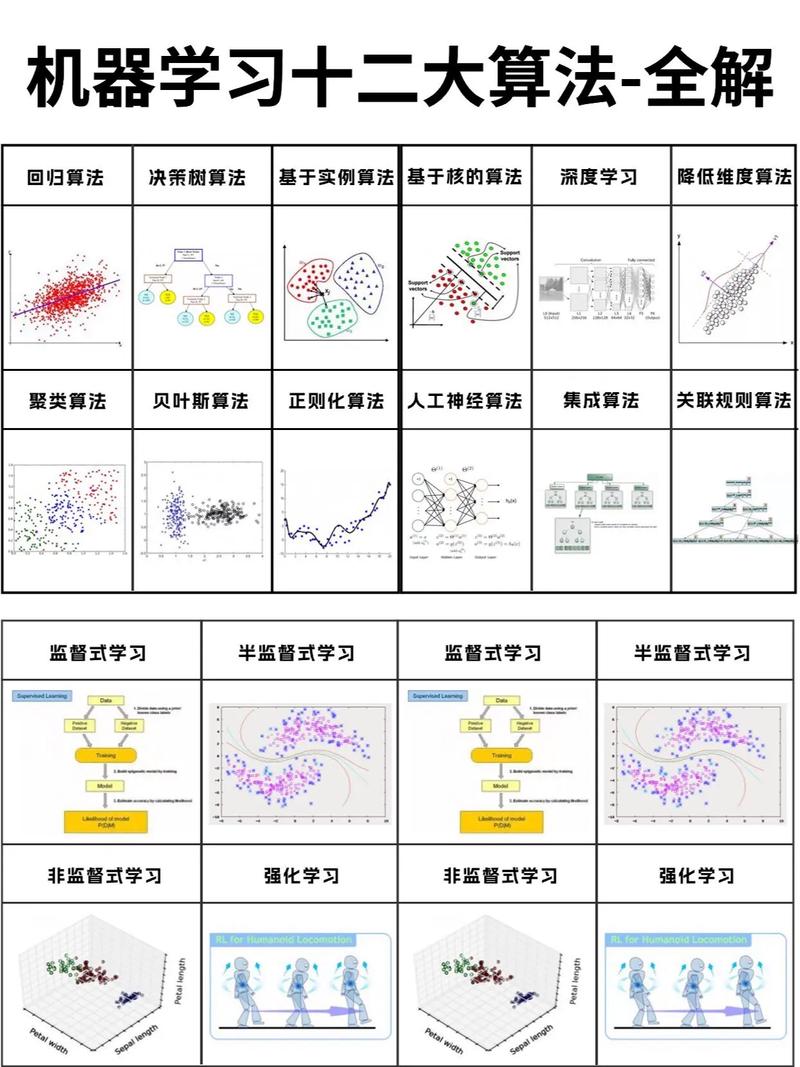
机器学习作为人工智能领域的一个重要分支,其核心在于通过算法让计算机从数据中学习并做出决策。随着技术的不断发展,机器学习算法种类繁多,以下将介绍一些主要的机器学习算法。
监督学习算法

监督学习算法是机器学习中最常见的一类算法,它通过已知的输入和输出数据来训练模型,从而对未知数据进行预测。
1. 线性回归
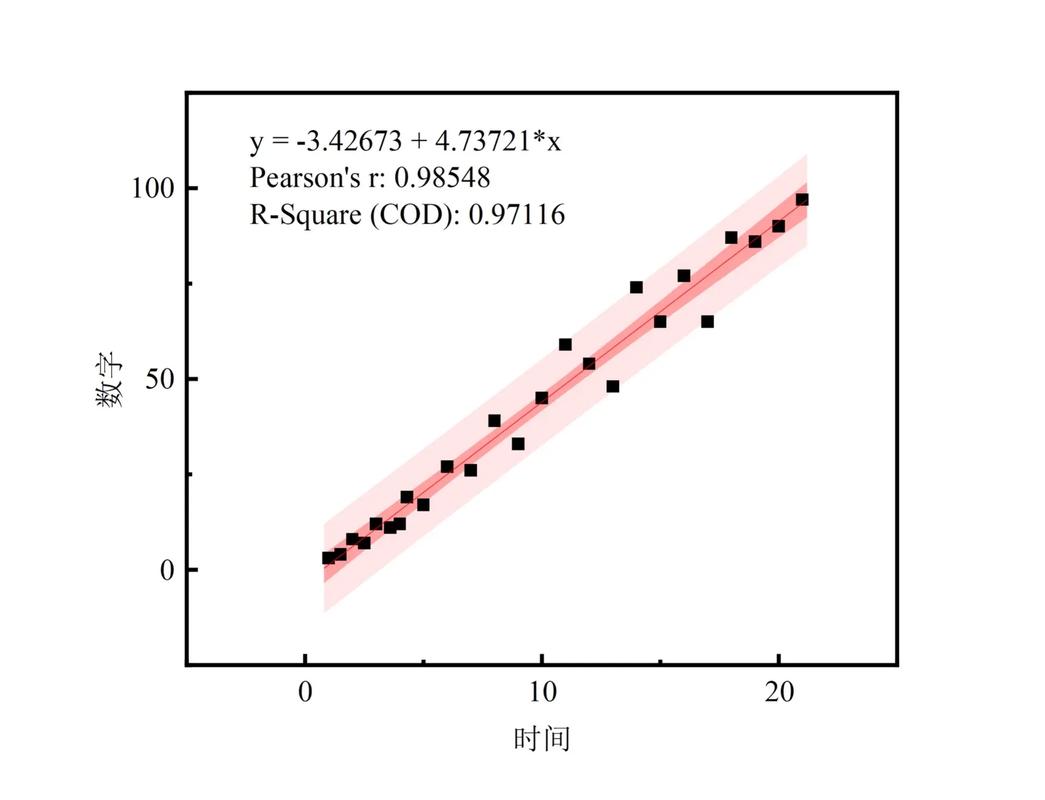
线性回归是一种简单的监督学习算法,用于预测连续值。其基本思想是找到一个线性函数,使得该函数能够最小化预测值与实际值之间的误差。
2. 逻辑回归
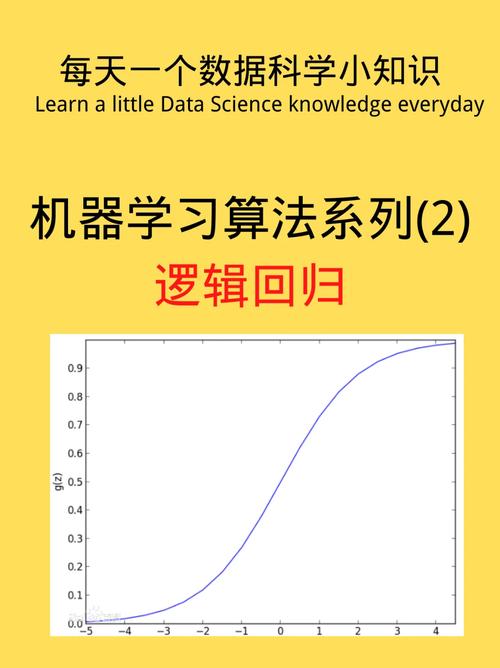
逻辑回归是一种用于分类问题的监督学习算法,它通过将线性回归的输出转换为概率值,从而对样本进行分类。
3. 决策树
决策树是一种基于树结构的分类算法,通过一系列的决策规则将数据集划分为不同的子集,最终得到一个分类结果。
无监督学习算法
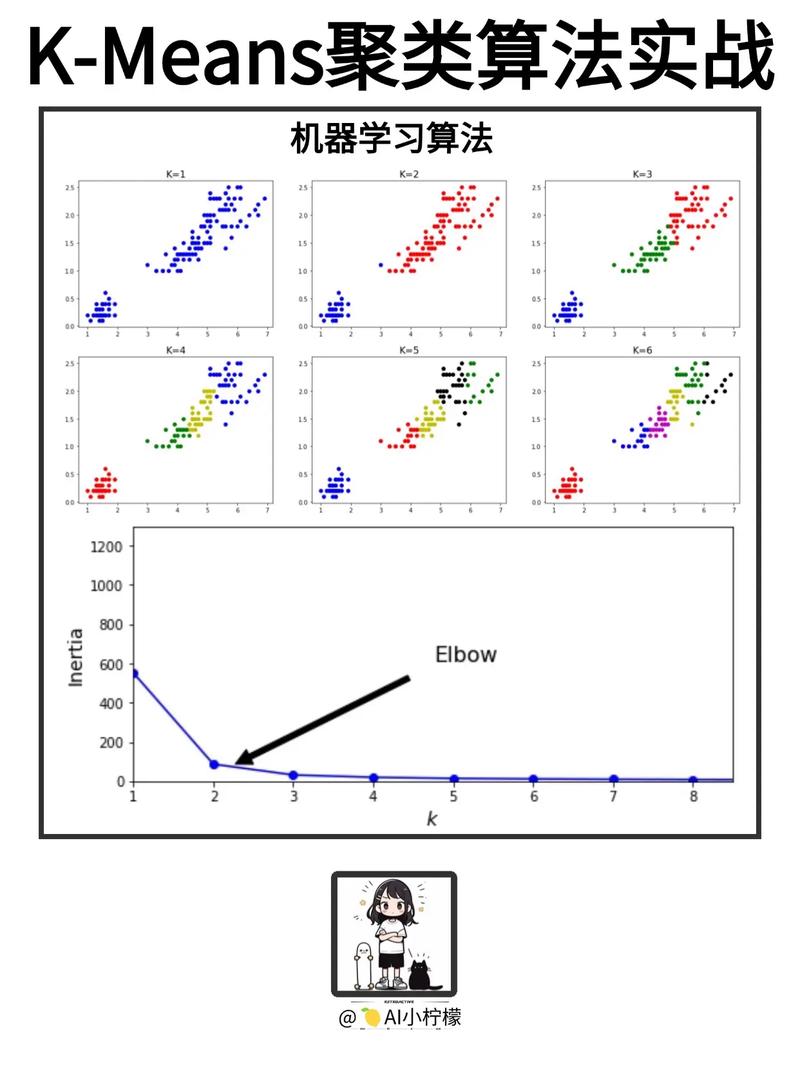
1. K-均值聚类
K-均值聚类是一种基于距离的聚类算法,它将数据集划分为K个簇,使得每个簇内的数据点之间的距离最小,而簇与簇之间的距离最大。
2. 主成分分析(PCA)

主成分分析是一种降维算法,它通过将数据投影到新的低维空间中,从而减少数据维度,同时保留数据的主要信息。
半监督学习算法
半监督学习算法结合了监督学习和无监督学习的特点,它利用部分标记数据和大量未标记数据来训练模型。
1. 自编码器

自编码器是一种无监督学习算法,它通过学习输入数据的低维表示来提取数据特征,从而对未标记数据进行分类。
强化学习算法
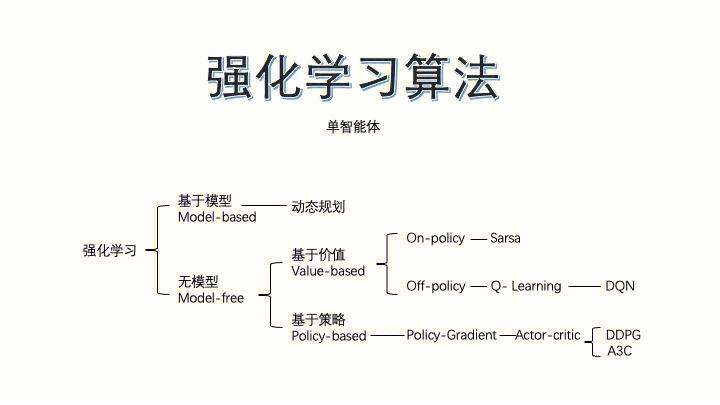
强化学习是一种通过与环境交互来学习最优策略的算法,它通过奖励和惩罚来指导学习过程。
1. Q学习

Q学习是一种基于值函数的强化学习算法,它通过学习状态-动作值函数来选择最优动作。
2. 深度Q网络(DQN)
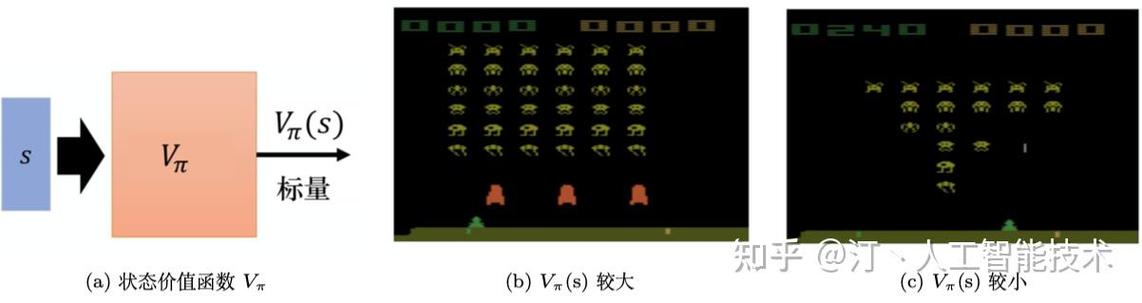
深度Q网络是一种基于深度学习的强化学习算法,它通过神经网络来近似Q函数,从而提高学习效率。
机器学习算法种类繁多,不同的算法适用于不同的场景和数据类型。在实际应用中,我们需要根据具体问题选择合适的算法,并通过不断优化和调整算法参数来提高模型的性能。








