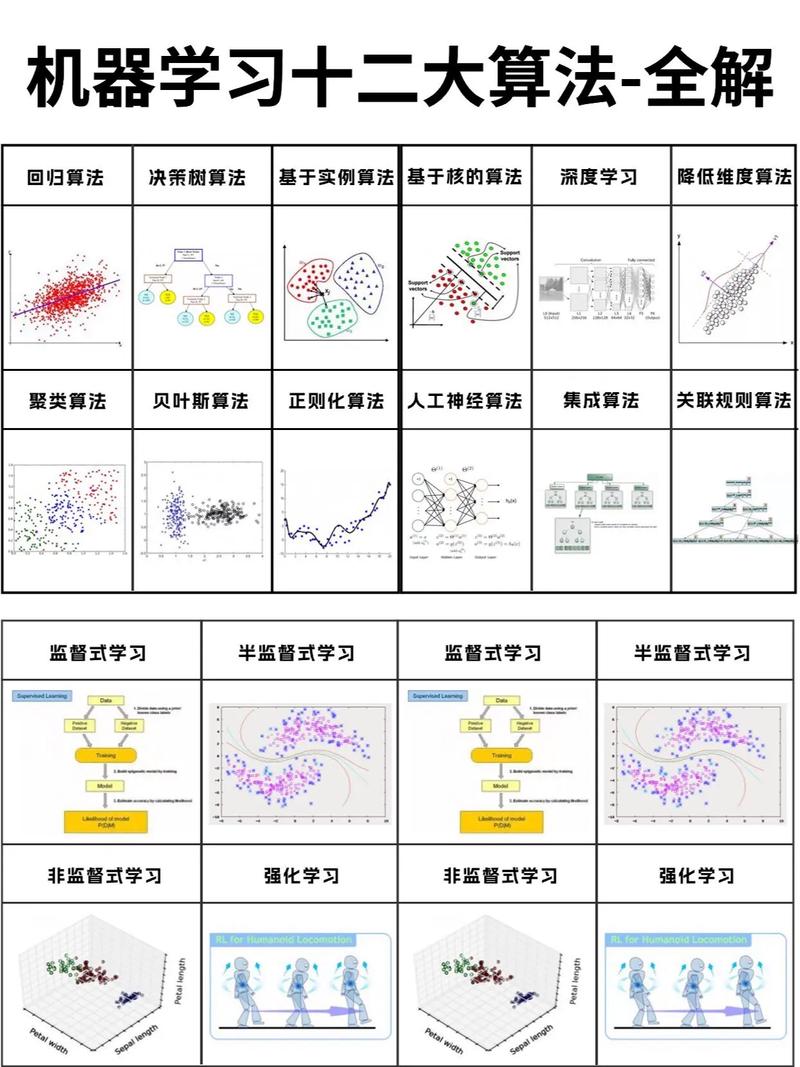
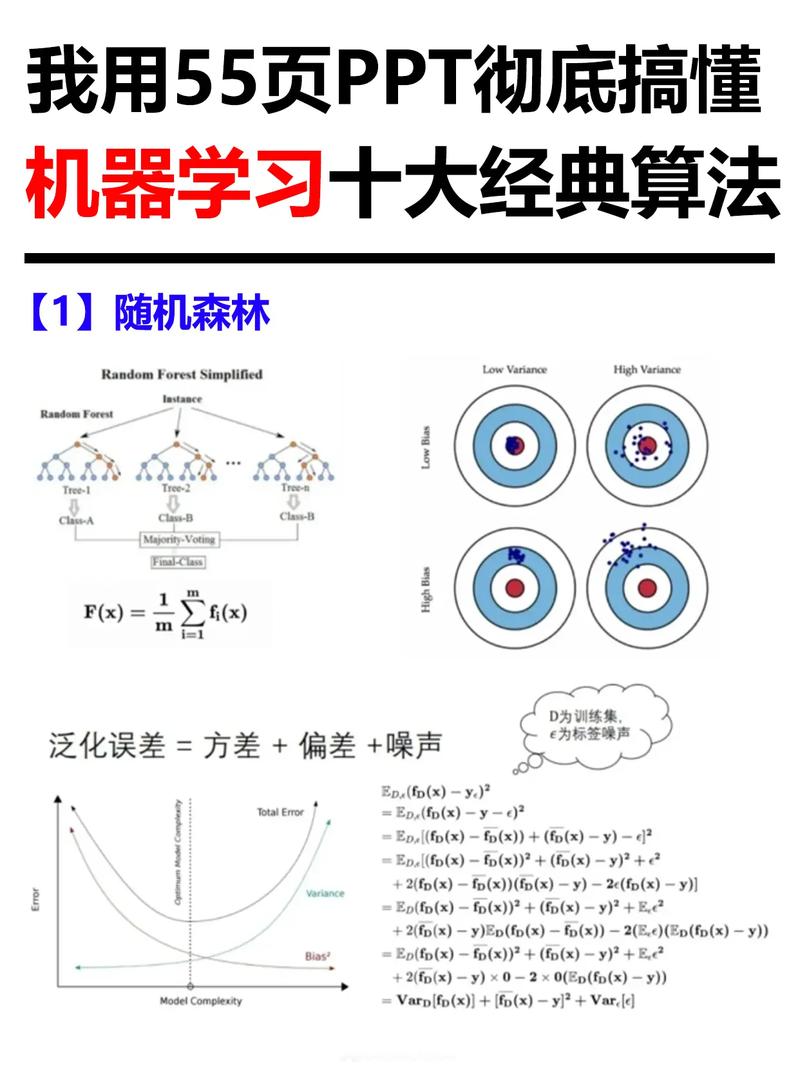
机器学习是一个迭代的过程,它包括以下主要步骤:
1. 定义问题:明确你要解决的问题是什么。这包括确定目标变量(预测或分类的变量)以及你想要达到的性能指标。
2. 数据收集:收集与问题相关的数据。这些数据可以是结构化的(如数据库中的表格)或非结构化的(如文本、图像、音频等)。
3. 数据预处理:对数据进行清洗、转换和归一化。这可能包括去除缺失值、异常值处理、特征工程等。
4. 特征选择:选择与目标变量最相关的特征。这有助于减少模型的复杂性,提高性能。
5. 模型选择:根据问题的性质选择合适的机器学习模型。这可能是一个监督学习模型(如线性回归、支持向量机、决策树等)或无监督学习模型(如聚类、降维等)。
6. 训练模型:使用训练数据来训练选定的模型。在训练过程中,模型会学习如何从输入数据中提取特征并预测目标变量。
7. 模型评估:使用验证集来评估模型的性能。这可以帮助你了解模型在未知数据上的表现,并确定是否需要调整模型或数据。
8. 模型调优:根据评估结果调整模型参数,以提高性能。这可能包括改变模型结构、调整超参数等。
9. 模型验证:使用测试集来验证模型的最终性能。这可以帮助你确定模型在实际应用中的可靠性。
10. 部署模型:将训练好的模型部署到生产环境中,以便在实际应用中使用。
11. 监控和维护:在模型部署后,持续监控其性能,并根据需要进行维护和更新。
12. 迭代改进:根据模型的性能和反馈,不断迭代和改进模型,以提高其准确性和效率。
请注意,这只是一个大致的框架,实际的机器学习项目可能会根据具体问题而有所不同。
机器学习步骤概述

机器学习是一个涉及数据、算法和模型的复杂过程,旨在从数据中提取模式和知识。以下是一篇关于机器学习步骤的文章,旨在帮助读者了解整个流程的各个阶段。
一、问题定义与数据收集

在开始机器学习项目之前,首先需要明确要解决的问题。这包括确定目标、理解业务需求以及收集相关数据。
目标设定:明确要解决的问题,例如分类、回归或聚类。
业务需求分析:了解业务背景,确保机器学习项目能够满足实际需求。
数据收集:从各种来源收集数据,包括公开数据集、企业内部数据等。
二、数据预处理

数据预处理是机器学习流程中的关键步骤,旨在提高数据质量和模型性能。
数据清洗:处理缺失值、异常值和重复数据。
数据转换:将数据转换为适合模型输入的格式,如归一化、标准化等。
特征工程:创建新的特征或选择合适的特征,以提高模型性能。
三、探索性数据分析(EDA)
EDA旨在了解数据的分布、特征之间的关系以及潜在的模式。
数据可视化:使用图表和图形展示数据分布和特征关系。
统计分析:计算描述性统计量,如均值、方差、标准差等。
相关性分析:分析特征之间的相关性,为特征选择提供依据。
四、特征选择
特征选择旨在从原始特征集中选择最有信息量的特征,以提高模型性能和减少过拟合风险。
特征重要性:基于模型评估特征的重要性,如随机森林、梯度提升等。
卡方检验:使用卡方检验评估特征与目标变量之间的相关性。
F-value值评估:根据F-value值评估特征的重要性。
互信息:评估特征与目标变量之间的相互依赖程度。
五、模型选择与训练
根据问题类型和业务需求,选择合适的机器学习模型,并进行训练。
分类模型:如逻辑回归、支持向量机、决策树等。
回归模型:如线性回归、岭回归、LASSO回归等。
聚类模型:如K-means、层次聚类等。
模型训练:使用训练数据对模型进行训练,调整模型参数。
六、模型评估与优化
评估模型性能,并根据评估结果对模型进行优化。
交叉验证:使用交叉验证评估模型在未知数据上的性能。
性能指标:根据问题类型选择合适的性能指标,如准确率、召回率、F1值等。
模型优化:调整模型参数或尝试其他模型,以提高模型性能。
七、模型部署与应用
将训练好的模型部署到实际应用中,解决实际问题。
模型部署:将模型集成到应用程序或服务中。
模型监控:监控模型在应用中的表现,确保模型稳定运行。
模型更新:根据新数据或业务需求对模型进行更新。
八、持续迭代与优化
机器学习是一个持续迭代的过程,需要不断优化模型和算法。
数据更新:定期更新数据,确保模型适应新环境。
算法改进:研究新的算法和模型,提高模型性能。
业务需求调整:根据业务需求调整模型和算法。
通过以上步骤,我们可以构建一个完整的机器学习项目。在实际操作中,每个步骤都可能涉及多个子步骤和细节,但以上概述为读者提供了一个清晰的框架,有助于理解机器学习的基本流程。