大数据数据仓库(Big Data Data Warehouse)是一种用于存储、管理和分析大量数据的系统。它通常由多个组件组成,包括数据源、数据集成、数据存储、数据管理和数据分析。
1. 数据源:大数据数据仓库的数据源可以是多种多样的,包括关系型数据库、非关系型数据库、文件系统、日志文件、社交媒体等。
2. 数据集成:数据集成是将来自不同数据源的数据进行整合和转换,以便在数据仓库中进行存储和分析。这通常涉及到数据清洗、数据映射和数据转换等过程。
3. 数据存储:大数据数据仓库通常使用分布式文件系统(如Hadoop HDFS)或列式存储系统(如Apache Parquet)来存储大量的数据。这些存储系统具有高扩展性和高性能的特点,可以支持大数据量的存储和查询。
4. 数据管理:数据管理包括数据的安全性、数据的质量控制、数据的备份和恢复等。在大数据数据仓库中,数据管理尤为重要,因为数据量巨大,需要确保数据的完整性和可靠性。
5. 数据分析:大数据数据仓库的主要目的是对存储的数据进行分析,以获取有价值的信息和洞察。这通常涉及到使用各种数据分析工具和技术,如SQL查询、数据挖掘、机器学习等。
大数据数据仓库的优点包括:
1. 高扩展性:大数据数据仓库可以支持大量的数据存储和查询,可以随着数据量的增加而进行扩展。
2. 高性能:大数据数据仓库通常使用高性能的存储系统和计算资源,可以快速处理和分析大量的数据。
3. 多样性:大数据数据仓库可以支持多种数据类型和格式,包括结构化数据、半结构化数据和非结构化数据。
4. 易用性:大数据数据仓库通常提供友好的用户界面和工具,使得用户可以轻松地进行数据查询和分析。
大数据数据仓库也存在一些挑战和限制,如数据安全和隐私保护、数据质量和一致性、数据处理的实时性等。因此,在使用大数据数据仓库时,需要充分考虑这些因素,并采取相应的措施来解决问题。
大数据时代的数据仓库:定义与重要性

数据仓库的组成部分
一个完整的数据仓库系统通常由以下几个部分组成:
数据源:数据仓库的数据来源广泛,包括企业内部的各种业务系统,如销售系统、财务系统、人力资源系统等,以及来自外部数据提供商的数据。
数据的抽取、转换和加载(ETL):ETL是数据仓库的核心环节,它负责将数据从各个数据源抽取出来,进行清洗、转换和加载,最终将数据集成到数据仓库中。
数据的存储与管理:数据仓库通常采用关系型数据库或分布式文件系统等技术来存储数据。为了保证数据的一致性和完整性,需要建立数据仓库的管理机制,包括数据的备份、恢复、安全管理等。
OLAP服务器:联机分析处理(OLAP)服务器是数据仓库的核心组件之一,它提供多维数据分析功能,允许用户从不同的角度对数据进行分析和查询。
前端工具:前端工具包括数据可视化、报表生成、数据挖掘等,用于将数据仓库中的数据转化为直观的图表、报表和洞察,方便用户进行决策。
大数据数据仓库的发展趋势
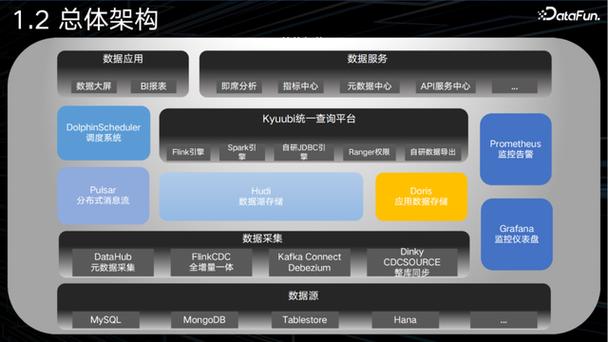
分布式存储和计算:随着数据量的不断增长,分布式存储和计算技术成为数据仓库发展的关键。如Hadoop、Spark等分布式计算框架,能够有效处理大规模数据集。
实时数据处理:传统的数据仓库主要处理离线数据,而实时数据处理技术使得数据仓库能够实时处理和分析数据,为用户提供更及时、更准确的决策支持。
数据湖与数据仓库的结合:数据湖是一种存储大量原始数据的平台,而数据仓库则用于对数据进行处理和分析。将数据湖与数据仓库相结合,可以更好地满足企业对数据存储、处理和分析的需求。
大数据数据仓库的应用场景
金融行业:通过数据仓库,金融机构可以实时监控市场动态,进行风险评估,优化投资策略。
零售行业:数据仓库可以帮助零售企业分析消费者行为,优化库存管理,提高销售额。
医疗行业:数据仓库可以用于医疗数据分析,帮助医生制定治疗方案,提高医疗质量。
政府机构:数据仓库可以用于政府决策支持,提高政府管理效率。
在大数据时代,数据仓库作为企业数据管理和分析的核心工具,其重要性日益凸显。随着大数据技术的不断发展,数据仓库也在不断演进,为各行各业提供更高效、更智能的数据处理和分析能力。企业应积极拥抱大数据数据仓库,以实现数据价值的最大化。