
机器学习分类算法有很多种,其中一些常用的包括:
1. 决策树:决策树是一种基于树形结构的分类算法,它通过一系列的决策规则来对数据进行分类。决策树算法简单易懂,易于实现,并且可以处理具有缺失值的数据。
2. 支持向量机(SVM):支持向量机是一种基于统计学习理论的分类算法,它通过找到一个超平面来将不同类别的数据分开。SVM算法具有很好的泛化能力,可以处理高维数据。
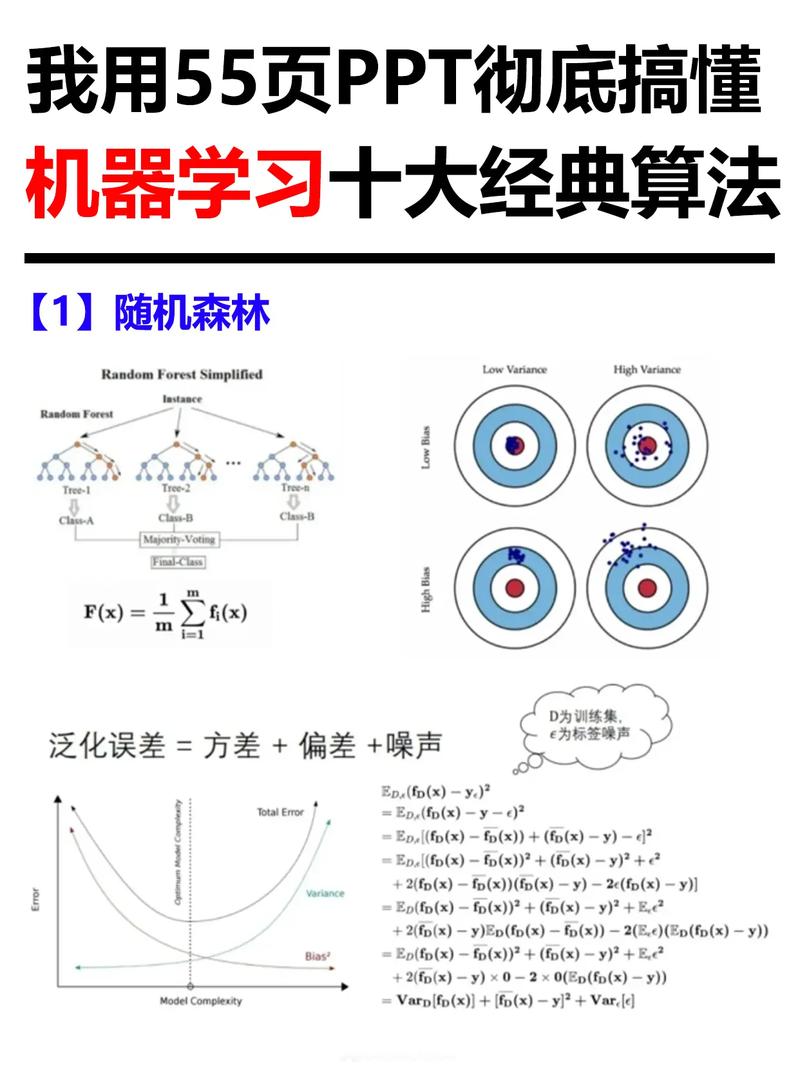
3. 随机森林:随机森林是一种基于决策树的集成学习算法,它通过构建多个决策树并对其进行投票来对数据进行分类。随机森林算法具有很好的鲁棒性和泛化能力,可以处理具有噪声的数据。
4. 朴素贝叶斯:朴素贝叶斯是一种基于贝叶斯定理的分类算法,它假设数据中的特征是相互独立的。朴素贝叶斯算法简单高效,可以处理大规模数据。
5. 神经网络:神经网络是一种基于人脑神经元结构的分类算法,它通过模拟人脑神经元之间的连接来对数据进行分类。神经网络算法具有强大的学习能力和泛化能力,可以处理复杂的非线性关系。
机器学习分类在许多领域都有广泛的应用,如语音识别、图像识别、自然语言处理、推荐系统等。通过使用机器学习分类算法,我们可以从大量数据中提取有用的信息,从而为人们提供更好的服务和支持。
机器学习分类:技术概述与实际应用
随着大数据时代的到来,机器学习技术在各个领域得到了广泛应用。其中,分类作为机器学习的基本任务之一,对于预测和决策具有重要意义。本文将介绍机器学习分类的基本概念、常用算法以及实际应用。
一、机器学习分类概述
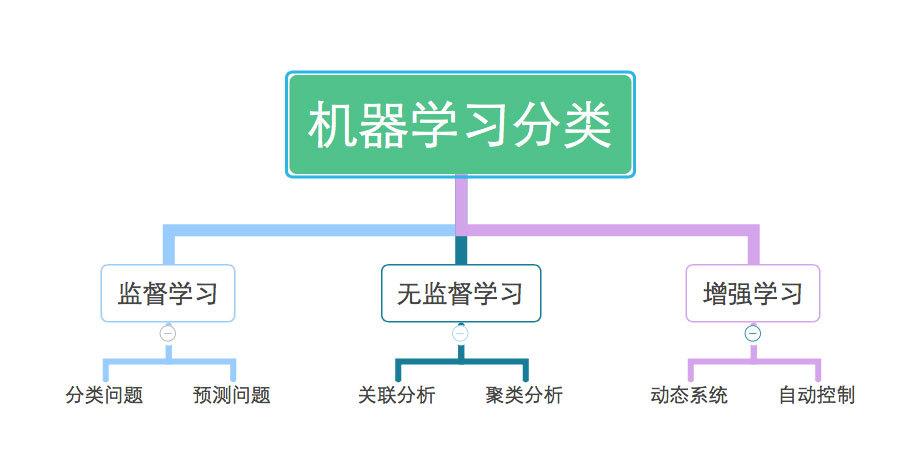
机器学习分类是指根据给定的训练数据,建立一个模型,用于对未知数据进行分类。分类任务通常分为两类:监督学习和无监督学习。监督学习需要标注的训练数据,而无监督学习则不需要。
二、常用分类算法

1. 线性分类器
2. 决策树
决策树是一种基于树结构的分类算法,通过一系列的决策规则将数据集划分为不同的子集,最终达到分类的目的。
3. 随机森林
随机森林是一种集成学习方法,通过构建多个决策树,并对它们的预测结果进行投票,从而提高分类性能。
4. 支持向量机(SVM)
SVM是一种基于间隔最大化的分类算法,通过寻找最优的超平面将数据集划分为不同的类别。
5. K最近邻(KNN)
KNN是一种基于距离的分类算法,通过计算待分类数据与训练数据之间的距离,选择最近的K个邻居,并根据邻居的类别进行投票。
6. 朴素贝叶斯
朴素贝叶斯是一种基于贝叶斯定理的分类算法,通过计算每个类别的概率,选择概率最大的类别作为预测结果。
三、分类算法在实际应用中的表现
1. 金融领域
在金融领域,分类算法可以用于信用评分、欺诈检测、股票预测等任务。例如,通过分析客户的信用历史和消费行为,可以预测客户是否具有违约风险。
2. 医疗领域
在医疗领域,分类算法可以用于疾病诊断、药物研发、患者分类等任务。例如,通过分析患者的病历和检查结果,可以预测患者是否患有某种疾病。
3. 零售领域
在零售领域,分类算法可以用于客户细分、商品推荐、库存管理等任务。例如,通过分析客户的购买行为,可以推荐适合他们的商品,提高销售额。
4. 智能家居
在智能家居领域,分类算法可以用于设备故障检测、能耗预测、安全监控等任务。例如,通过分析设备的运行数据,可以预测设备是否出现故障,并及时采取措施。
四、分类算法的挑战与展望
尽管分类算法在实际应用中取得了显著成果,但仍面临一些挑战:
1. 数据不平衡
在实际应用中,数据集往往存在不平衡现象,这可能导致分类算法偏向于多数类别,从而影响分类性能。
2. 特征选择
特征选择是分类算法的关键步骤,选择合适的特征可以提高分类性能。特征选择是一个复杂的问题,需要根据具体任务进行调整。
3. 模型可解释性随着深度学习等复杂模型的兴起,模型的可解释性成为一个重要问题。如何提高模型的可解释性,使其更易于理解和应用,是一个值得研究的方向。
机器学习, 分类算法, 线性分类器, 决策树, 随机森林, 支持向量机, K最近邻, 朴素贝叶斯, 金融领域, 医疗领域, 零售领域, 智能家居, 数据不平衡, 特征选择, 模型可解释性








