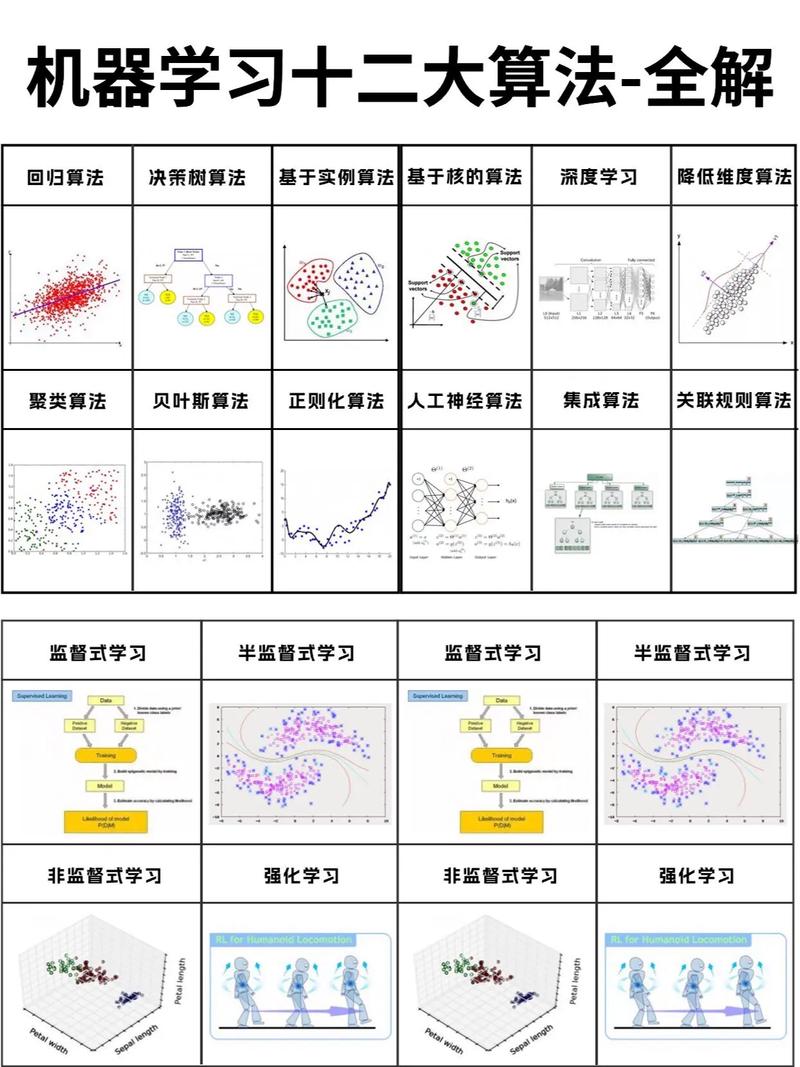
1. 监督学习算法: 线性回归:用于预测连续数值。 逻辑回归:用于二分类问题。 决策树:根据特征值进行分类或回归。 随机森林:由多个决策树组成,用于提高预测准确性。 支持向量机(SVM):用于分类和回归问题。 神经网络:由多个神经元组成,用于复杂的分类和回归任务。
2. 无监督学习算法: K均值聚类:将数据分为K个簇。 层次聚类:将数据按照相似度进行层次划分。 主成分分析(PCA):用于数据降维。 自组织映射(SOM):用于数据可视化。
3. 强化学习算法: Q学习:通过学习Q值来找到最优策略。 深度Q网络(DQN):使用神经网络来近似Q值。 模仿学习:通过模仿专家的行为来学习策略。 政策梯度:通过梯度上升来优化策略。
此外,还有一些常用的集成学习方法,如: 随机森林:结合多个决策树进行预测。 提升树(Boosting):逐步优化弱学习器来提高预测性能。 袋装(Bagging):通过自助采样来训练多个模型,然后进行集成。
这些算法在机器学习领域都有广泛的应用,可以根据具体问题选择合适的算法进行建模和预测。
常用机器学习算法概述
监督学习算法
线性回归
逻辑回归
支持向量机(SVM)
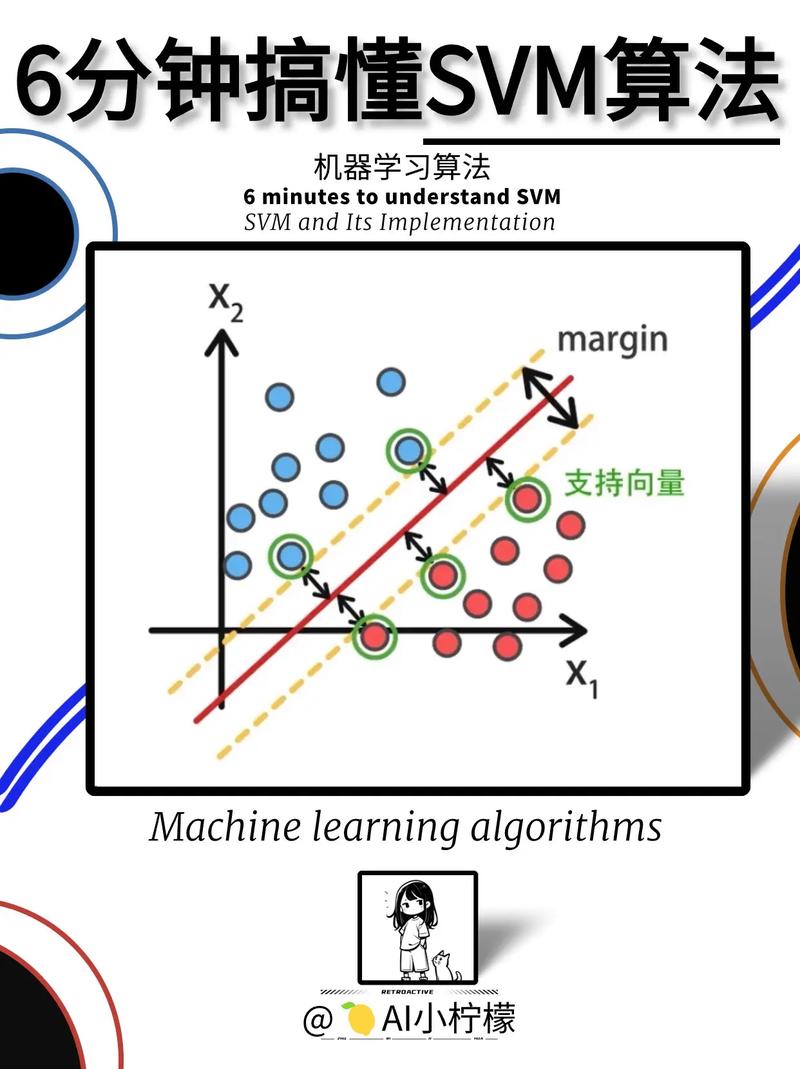
支持向量机是一种强大的分类算法,它通过找到一个最优的超平面来将不同类别的数据分开。SVM在处理高维数据时表现出色,并且具有较好的泛化能力。
决策树
决策树是一种基于树结构的分类算法,它通过一系列的决策规则将数据集划分为不同的子集,最终得到一个分类结果。
随机森林

随机森林是一种集成学习方法,它通过构建多个决策树,并对每个决策树的预测结果进行投票,从而提高模型的预测性能和鲁棒性。
无监督学习算法
无监督学习算法是机器学习中的另一类算法,它通过学习数据中的内在结构来发现数据中的模式。
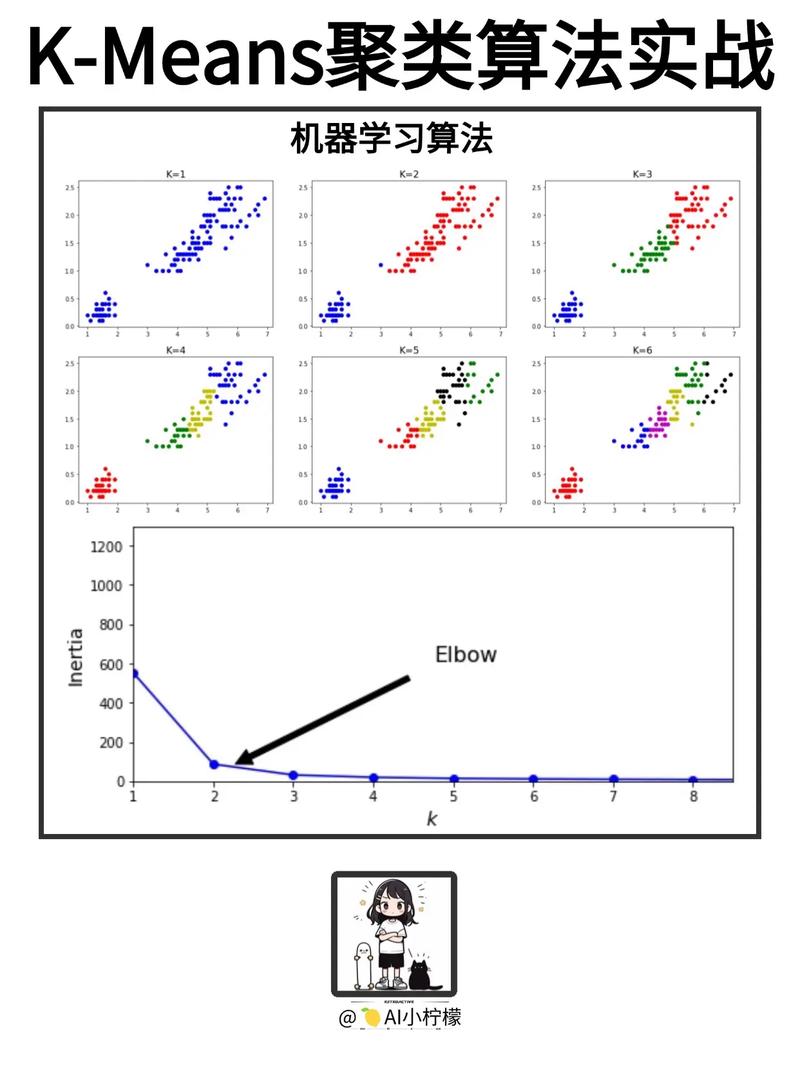
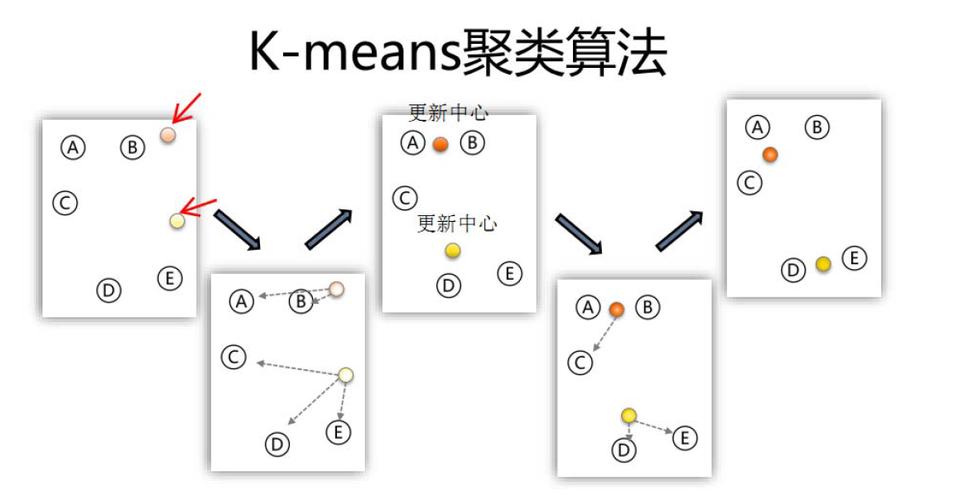
K-均值聚类
K-均值聚类是一种基于距离的聚类算法,它通过将数据点分配到K个簇中,使得每个簇内的数据点之间的距离最小,而簇与簇之间的距离最大。
层次聚类

层次聚类是一种基于层次结构的聚类算法,它通过将数据点逐步合并成簇,从而形成一棵聚类树。
主成分分析(PCA)
主成分分析是一种降维算法,它通过将数据投影到低维空间,从而减少数据维度,同时保留数据的主要信息。
本文介绍了常用的机器学习算法,包括监督学习算法和无监督学习算法。这些算法在各个领域都有广泛的应用,读者可以根据自己的需求选择合适的算法进行学习和应用。