1. 倒排索引(Inverted Index):这是一种常见的文本检索技术,它将文档中的单词映射到包含该单词的文档列表。在向量数据库中,倒排索引可以用来存储向量及其对应的文档或对象。
2. 局部敏感哈希(LSH,LocalitySensitive Hashing):LSH是一种用于近似最近邻搜索的哈希技术。它通过将高维空间中的数据点映射到低维空间,使得相似的数据点更有可能在同一个哈希桶中。这样,可以通过比较哈希值来快速找到相似的向量。
3. 空间填充曲线(SpaceFilling Curve):空间填充曲线是一种将多维数据映射到一维空间的技术。在向量数据库中,可以使用空间填充曲线来将高维向量映射到一维空间,以便进行高效的索引和检索。
4. 树状结构(TreeBased Structures):树状结构,如KD树、球树(Ball Tree)和Annoy(Approximate Nearest Neighbors Oh Yeah)等,可以用于高效地索引和检索高维向量。这些树状结构通过将向量空间分割成多个子空间来减少搜索空间。
5. 向量量化(Vector Quantization):向量量化是一种将向量数据映射到有限数量的代表向量(码本)的技术。在向量数据库中,可以使用向量量化来减少存储空间,并通过比较码本来快速检索相似的向量。
这些模型可以根据具体的应用场景和数据特性进行选择和优化。在实际应用中,向量数据库可能会使用这些模型的组合来提供高效、准确的向量检索功能。
向量数据库的多样模型解析
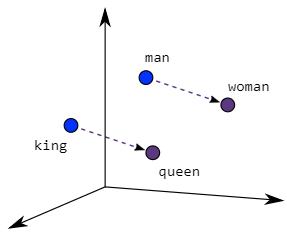
一、向量数据库概述

向量数据库是一种专门用于存储和检索高维空间中向量数据的数据库。它能够高效地处理高维数据,支持相似度查询、聚类分析等操作。向量数据库广泛应用于推荐系统、图像识别、自然语言处理等领域。
二、向量数据库模型分类

向量数据库模型主要分为以下几类:
1. 基于距离的模型
基于距离的模型是最常见的向量数据库模型,它通过计算向量之间的距离来衡量相似度。常见的距离度量方法包括欧氏距离、余弦相似度、汉明距离等。
2. 基于哈希的模型
基于哈希的模型通过将向量哈希到固定长度的哈希值,从而实现快速检索。这种模型在处理大规模数据集时具有很高的效率,但可能存在哈希冲突的问题。
3. 基于树的模型
基于树的模型通过构建树状结构来组织向量数据,例如KD树、球树等。这种模型能够有效地减少查询过程中的比较次数,提高检索效率。
4. 基于图模型的模型
基于图模型的模型通过构建向量数据之间的图结构,从而实现更复杂的查询操作。这种模型在处理复杂关系和关联分析时具有优势。
5. 基于深度学习的模型
基于深度学习的模型通过神经网络等深度学习技术来处理向量数据,从而实现更高级的相似度计算和特征提取。这种模型在处理大规模、高维数据时具有很高的准确性。
三、向量数据库模型应用场景
向量数据库模型在以下场景中具有广泛的应用:
1. 推荐系统
向量数据库可以用于存储用户和物品的向量表示,从而实现基于内容的推荐、协同过滤等推荐算法。
2. 图像识别
向量数据库可以用于存储图像特征向量,从而实现图像检索、图像分类等图像识别任务。
3. 自然语言处理
向量数据库可以用于存储文本向量,从而实现文本分类、情感分析等自然语言处理任务。
4. 聚类分析
向量数据库可以用于存储聚类分析中的向量数据,从而实现数据聚类、异常检测等任务。
向量数据库模型在数据存储和检索领域具有广泛的应用前景。本文对向量数据库的多种模型进行了解析,包括基于距离的模型、基于哈希的模型、基于树的模型、基于图模型的模型和基于深度学习的模型。了解这些模型的特点和应用场景,有助于读者更好地选择和使用向量数据库。