
2. 常用算法: 线性回归:用于预测连续值输出。 逻辑回归:用于分类问题,特别是二分类。 决策树:通过一系列的规则对数据进行分类或回归。 随机森林:多个决策树的集合,用于提高预测的准确性和稳定性。 支持向量机(SVM):用于分类和回归,通过找到数据中的最佳超平面来实现。 神经网络:由多个相互连接的神经元组成,可以学习复杂的非线性关系。
3. 评估指标: 准确率:正确预测的样本数除以总样本数。 召回率:正确预测的正样本数除以所有正样本数。 F1分数:准确率和召回率的调和平均数。 均方误差(MSE):用于回归问题的误差度量。 交叉熵损失:用于分类问题的损失函数。
4. 模型选择和调优: 交叉验证:将数据分成多个子集,用于训练和验证模型。 网格搜索:尝试不同的参数组合来找到最佳模型。 随机搜索:随机选择参数组合来找到最佳模型。
5. 模型部署: 模型保存和加载:将训练好的模型保存到文件中,以便以后使用。 API开发:将模型部署为API,以便其他应用程序可以访问和使用。
6. 机器学习的挑战: 过拟合:模型在训练数据上表现很好,但在新数据上表现不佳。 欠拟合:模型过于简单,无法捕捉到数据中的复杂关系。 数据质量:数据中的噪声和不一致性会影响模型的性能。 计算资源:训练大型模型需要大量的计算资源和时间。
机器学习是一个快速发展的领域,随着技术的进步,新的算法和工具不断涌现。了解这些基础知识将有助于您更好地理解和应用机器学习。
机器学习基础:入门必读
一、什么是机器学习?
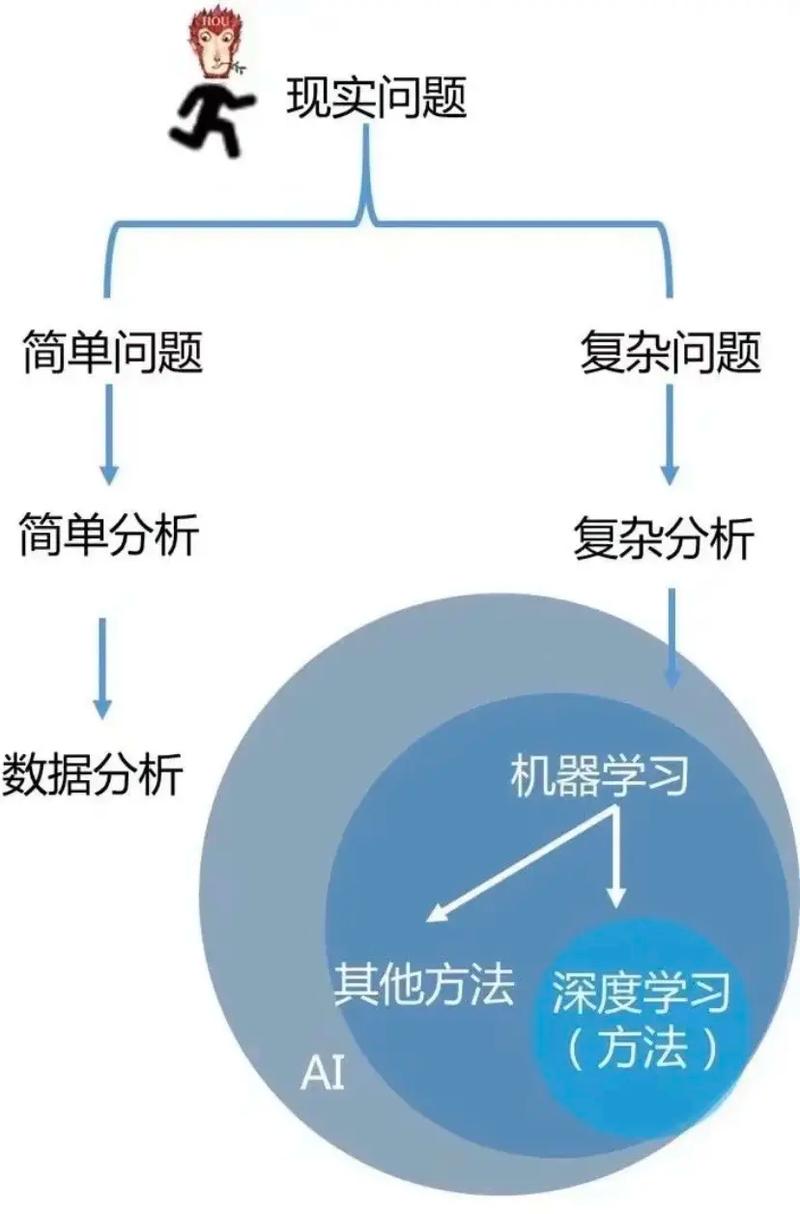
机器学习(Machine Learning)是一门研究如何让计算机从数据中学习,并做出决策或预测的学科。简单来说,机器学习就是让计算机通过学习数据,自动完成特定任务的过程。
二、机器学习的分类
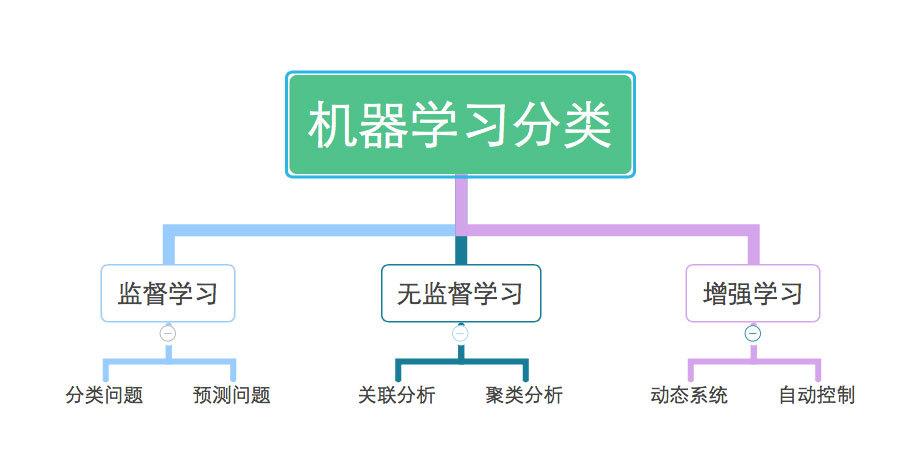
根据学习方式和应用场景,机器学习可以分为以下几类:
监督学习(Supervised Learning):通过已标记的训练数据,让计算机学习并建立模型,从而对未知数据进行预测。
无监督学习(Unsupervised Learning):通过未标记的训练数据,让计算机自动寻找数据中的规律和结构。
半监督学习(Semi-supervised Learning):结合监督学习和无监督学习,使用少量标记数据和大量未标记数据来训练模型。
强化学习(Reinforcement Learning):通过与环境交互,让计算机学习如何做出最优决策。
三、机器学习的基本流程
机器学习的基本流程包括以下步骤:
数据收集:收集与任务相关的数据,如文本、图像、声音等。
数据预处理:对收集到的数据进行清洗、转换、归一化等操作,以提高数据质量。
特征提取:从原始数据中提取出对任务有用的特征。
模型选择:根据任务需求,选择合适的机器学习算法。
模型训练:使用训练数据对模型进行训练,使模型能够学习数据中的规律。
模型评估:使用测试数据对模型进行评估,以检验模型的性能。
模型优化:根据评估结果,对模型进行调整和优化,以提高模型性能。
四、常见的机器学习算法
线性回归(Linear Regression):用于预测连续值。
逻辑回归(Logistic Regression):用于预测离散值,如分类问题。
支持向量机(Support Vector Machine,SVM):用于分类和回归问题。
决策树(Decision Tree):用于分类和回归问题,易于理解和解释。
随机森林(Random Forest):基于决策树的集成学习方法,具有较好的泛化能力。
神经网络(Neural Network):模拟人脑神经元的工作原理,适用于复杂问题。
五、机器学习的应用领域
自然语言处理(NLP):如机器翻译、情感分析、文本分类等。
计算机视觉:如图像识别、目标检测、人脸识别等。
推荐系统:如电影推荐、商品推荐等。
金融风控:如信用评分、欺诈检测等。
医疗诊断:如疾病预测、药物研发等。
机器学习作为人工智能的核心技术,具有广泛的应用前景。通过本文的介绍,相信您对机器学习有了初步的了解。希望您能够继续深入学习,探索机器学习的无限可能。








