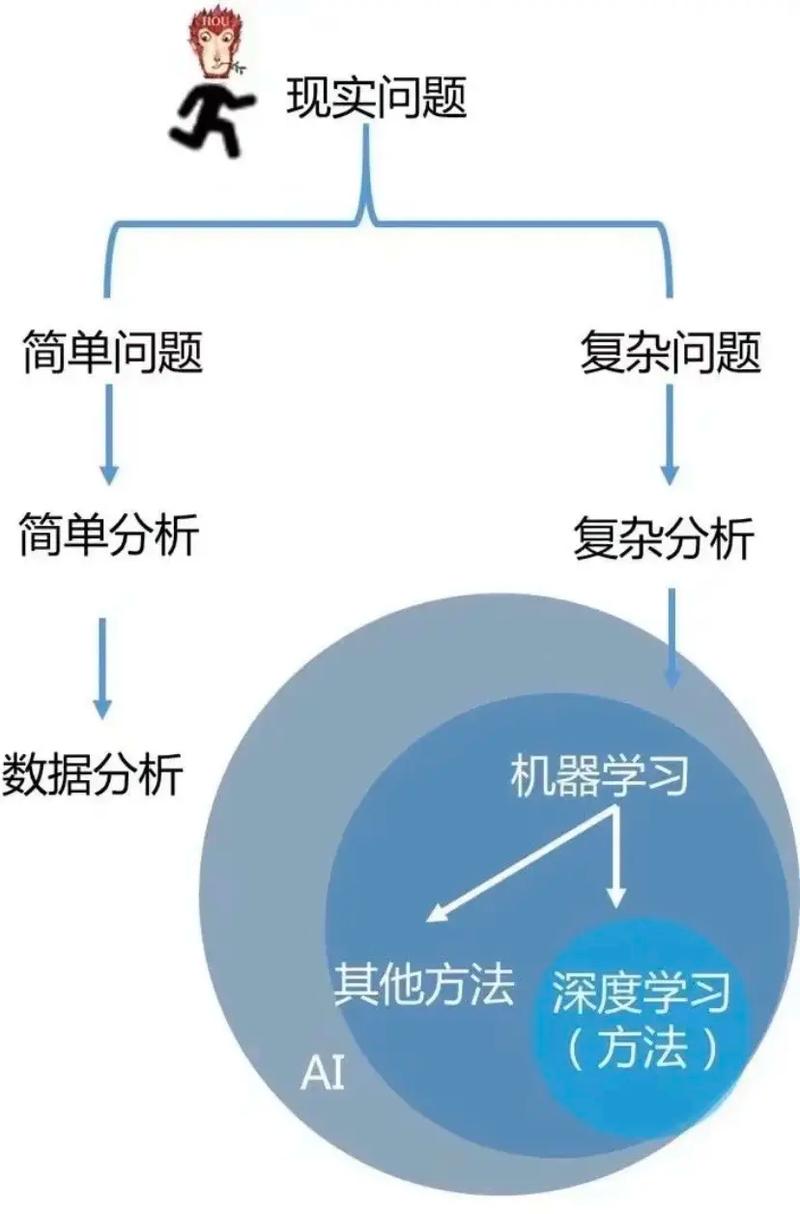
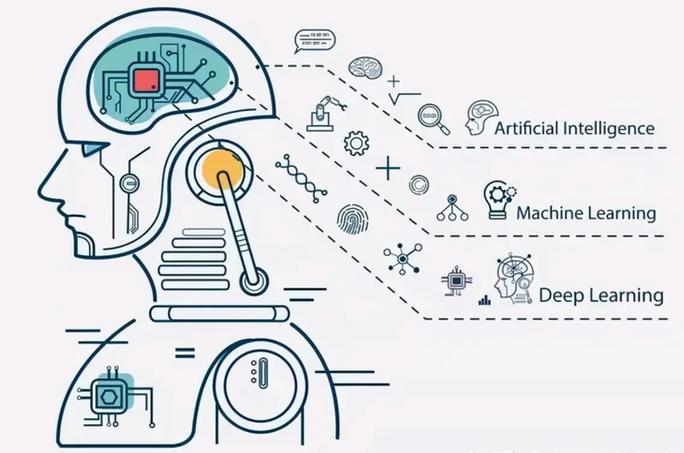
机器学习是一个广泛的领域,它涵盖了多种分类方法。以下是几种主要的机器学习分类:
1. 监督学习(Supervised Learning):监督学习是一种有指导的学习方式,其中算法从标记的训练数据中学习,以预测新的、未标记的数据。这种学习方式包括分类和回归问题。分类问题试图预测离散的输出值,如电子邮件是否为垃圾邮件,而回归问题则试图预测连续的输出值,如房价。
2. 无监督学习(Unsupervised Learning):无监督学习是一种没有指导的学习方式,其中算法从未标记的数据中学习,以发现数据中的模式和结构。这种学习方式包括聚类和关联规则学习问题。聚类问题试图将数据分组为具有相似特征的簇,而关联规则学习问题则试图发现数据中项之间的频繁共现关系。
3. 半监督学习(Semisupervised Learning):半监督学习是一种结合了监督学习和无监督学习的方法。在这种学习方式中,算法从部分标记的数据中学习,以预测新的、未标记的数据。这种学习方式适用于标记数据昂贵或难以获得的情况。
4. 强化学习(Reinforcement Learning):强化学习是一种通过与环境交互来学习如何执行特定任务的方法。在这种学习方式中,智能体(agent)通过与环境的交互来学习执行特定任务的最佳策略。强化学习通常用于解决具有明确目标的问题,如游戏、机器人控制等。
5. 深度学习(Deep Learning):深度学习是一种使用神经网络来学习数据表示的方法。神经网络是一种由多个层组成的计算模型,每层都负责从输入数据中提取特征。深度学习在图像识别、自然语言处理、语音识别等领域取得了显著的成果。
6. 转移学习(Transfer Learning):转移学习是一种将一个领域学习到的知识应用到另一个领域的方法。在这种学习方式中,算法从一个领域(源领域)学习,并将学到的知识应用到另一个领域(目标领域)。转移学习通常用于解决目标领域数据不足的问题。
7. 元学习(Meta Learning):元学习是一种学习如何学习的方法。在这种学习方式中,算法从一个或多个任务中学习,并将学到的知识应用到新的任务中。元学习通常用于解决小样本学习问题,即当训练数据量有限时,如何快速适应新任务。
8. 自监督学习(Selfsupervised Learning):自监督学习是一种使用未标记数据来学习表示的方法。在这种学习方式中,算法从未标记的数据中学习,以发现数据中的模式和结构。自监督学习通常用于图像识别、自然语言处理等领域。
9. 多任务学习(Multitask Learning):多任务学习是一种同时学习多个相关任务的方法。在这种学习方式中,算法从一个或多个任务中学习,并将学到的知识应用到其他任务中。多任务学习通常用于解决相关任务之间的知识共享问题。
11. 迁移学习(Transfer Learning):迁移学习是一种利用已经在一个任务上学到的知识来解决另一个相关任务的方法。这种学习方式通常用于解决数据不足或难以获取的问题。
13. 增量学习(Incremental Learning):增量学习是一种逐步学习新数据的方法。在这种学习方式中,算法从旧数据中学习,并逐步更新模型以适应新数据。增量学习通常用于解决数据流问题,即数据不断变化的情况。
14. 零样本学习(Zeroshot Learning):零样本学习是一种在没有见过任何示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
15. 小样本学习(Fewshot Learning):小样本学习是一种在只有少量示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
17. 集成学习(Ensemble Learning):集成学习是一种结合多个模型预测以提高整体性能的方法。在这种方法中,多个模型对同一问题进行预测,然后通过某种方式(如平均、投票等)将预测结果结合起来。集成学习通常用于提高模型的稳定性和准确性。
18. 生成对抗网络(Generative Adversarial Networks,GANs):生成对抗网络是一种由生成器和判别器组成的深度学习模型。生成器试图生成与真实数据相似的数据,而判别器试图区分真实数据和生成数据。GANs通常用于图像生成、文本生成等领域。
19. 图神经网络(Graph Neural Networks,GNNs):图神经网络是一种用于处理图结构数据的深度学习模型。GNNs通常用于社交网络分析、推荐系统等领域。
20. 迁移学习(Transfer Learning):迁移学习是一种利用已经在一个任务上学到的知识来解决另一个相关任务的方法。这种学习方式通常用于解决数据不足或难以获取的问题。
22. 增量学习(Incremental Learning):增量学习是一种逐步学习新数据的方法。在这种学习方式中,算法从旧数据中学习,并逐步更新模型以适应新数据。增量学习通常用于解决数据流问题,即数据不断变化的情况。
23. 零样本学习(Zeroshot Learning):零样本学习是一种在没有见过任何示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
24. 小样本学习(Fewshot Learning):小样本学习是一种在只有少量示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
26. 集成学习(Ensemble Learning):集成学习是一种结合多个模型预测以提高整体性能的方法。在这种方法中,多个模型对同一问题进行预测,然后通过某种方式(如平均、投票等)将预测结果结合起来。集成学习通常用于提高模型的稳定性和准确性。
27. 生成对抗网络(Generative Adversarial Networks,GANs):生成对抗网络是一种由生成器和判别器组成的深度学习模型。生成器试图生成与真实数据相似的数据,而判别器试图区分真实数据和生成数据。GANs通常用于图像生成、文本生成等领域。
28. 图神经网络(Graph Neural Networks,GNNs):图神经网络是一种用于处理图结构数据的深度学习模型。GNNs通常用于社交网络分析、推荐系统等领域。
29. 迁移学习(Transfer Learning):迁移学习是一种利用已经在一个任务上学到的知识来解决另一个相关任务的方法。这种学习方式通常用于解决数据不足或难以获取的问题。
31. 增量学习(Incremental Learning):增量学习是一种逐步学习新数据的方法。在这种学习方式中,算法从旧数据中学习,并逐步更新模型以适应新数据。增量学习通常用于解决数据流问题,即数据不断变化的情况。
32. 零样本学习(Zeroshot Learning):零样本学习是一种在没有见过任何示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
33. 小样本学习(Fewshot Learning):小样本学习是一种在只有少量示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
35. 集成学习(Ensemble Learning):集成学习是一种结合多个模型预测以提高整体性能的方法。在这种方法中,多个模型对同一问题进行预测,然后通过某种方式(如平均、投票等)将预测结果结合起来。集成学习通常用于提高模型的稳定性和准确性。
36. 生成对抗网络(Generative Adversarial Networks,GANs):生成对抗网络是一种由生成器和判别器组成的深度学习模型。生成器试图生成与真实数据相似的数据,而判别器试图区分真实数据和生成数据。GANs通常用于图像生成、文本生成等领域。
37. 图神经网络(Graph Neural Networks,GNNs):图神经网络是一种用于处理图结构数据的深度学习模型。GNNs通常用于社交网络分析、推荐系统等领域。
38. 迁移学习(Transfer Learning):迁移学习是一种利用已经在一个任务上学到的知识来解决另一个相关任务的方法。这种学习方式通常用于解决数据不足或难以获取的问题。
40. 增量学习(Incremental Learning):增量学习是一种逐步学习新数据的方法。在这种学习方式中,算法从旧数据中学习,并逐步更新模型以适应新数据。增量学习通常用于解决数据流问题,即数据不断变化的情况。
41. 零样本学习(Zeroshot Learning):零样本学习是一种在没有见过任何示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
42. 小样本学习(Fewshot Learning):小样本学习是一种在只有少量示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
44. 集成学习(Ensemble Learning):集成学习是一种结合多个模型预测以提高整体性能的方法。在这种方法中,多个模型对同一问题进行预测,然后通过某种方式(如平均、投票等)将预测结果结合起来。集成学习通常用于提高模型的稳定性和准确性。
45. 生成对抗网络(Generative Adversarial Networks,GANs):生成对抗网络是一种由生成器和判别器组成的深度学习模型。生成器试图生成与真实数据相似的数据,而判别器试图区分真实数据和生成数据。GANs通常用于图像生成、文本生成等领域。
46. 图神经网络(Graph Neural Networks,GNNs):图神经网络是一种用于处理图结构数据的深度学习模型。GNNs通常用于社交网络分析、推荐系统等领域。
47. 迁移学习(Transfer Learning):迁移学习是一种利用已经在一个任务上学到的知识来解决另一个相关任务的方法。这种学习方式通常用于解决数据不足或难以获取的问题。
49. 增量学习(Incremental Learning):增量学习是一种逐步学习新数据的方法。在这种学习方式中,算法从旧数据中学习,并逐步更新模型以适应新数据。增量学习通常用于解决数据流问题,即数据不断变化的情况。
50. 零样本学习(Zeroshot Learning):零样本学习是一种在没有见过任何示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
51. 小样本学习(Fewshot Learning):小样本学习是一种在只有少量示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
53. 集成学习(Ensemble Learning):集成学习是一种结合多个模型预测以提高整体性能的方法。在这种方法中,多个模型对同一问题进行预测,然后通过某种方式(如平均、投票等)将预测结果结合起来。集成学习通常用于提高模型的稳定性和准确性。
54. 生成对抗网络(Generative Adversarial Networks,GANs):生成对抗网络是一种由生成器和判别器组成的深度学习模型。生成器试图生成与真实数据相似的数据,而判别器试图区分真实数据和生成数据。GANs通常用于图像生成、文本生成等领域。
55. 图神经网络(Graph Neural Networks,GNNs):图神经网络是一种用于处理图结构数据的深度学习模型。GNNs通常用于社交网络分析、推荐系统等领域。
56. 迁移学习(Transfer Learning):迁移学习是一种利用已经在一个任务上学到的知识来解决另一个相关任务的方法。这种学习方式通常用于解决数据不足或难以获取的问题。
58. 增量学习(Incremental Learning):增量学习是一种逐步学习新数据的方法。在这种学习方式中,算法从旧数据中学习,并逐步更新模型以适应新数据。增量学习通常用于解决数据流问题,即数据不断变化的情况。
59. 零样本学习(Zeroshot Learning):零样本学习是一种在没有见过任何示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
60. 小样本学习(Fewshot Learning):小样本学习是一种在只有少量示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
62. 集成学习(Ensemble Learning):集成学习是一种结合多个模型预测以提高整体性能的方法。在这种方法中,多个模型对同一问题进行预测,然后通过某种方式(如平均、投票等)将预测结果结合起来。集成学习通常用于提高模型的稳定性和准确性。
63. 生成对抗网络(Generative Adversarial Networks,GANs):生成对抗网络是一种由生成器和判别器组成的深度学习模型。生成器试图生成与真实数据相似的数据,而判别器试图区分真实数据和生成数据。GANs通常用于图像生成、文本生成等领域。
64. 图神经网络(Graph Neural Networks,GNNs):图神经网络是一种用于处理图结构数据的深度学习模型。GNNs通常用于社交网络分析、推荐系统等领域。
65. 迁移学习(Transfer Learning):迁移学习是一种利用已经在一个任务上学到的知识来解决另一个相关任务的方法。这种学习方式通常用于解决数据不足或难以获取的问题。
67. 增量学习(Incremental Learning):增量学习是一种逐步学习新数据的方法。在这种学习方式中,算法从旧数据中学习,并逐步更新模型以适应新数据。增量学习通常用于解决数据流问题,即数据不断变化的情况。
68. 零样本学习(Zeroshot Learning):零样本学习是一种在没有见过任何示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
69. 小样本学习(Fewshot Learning):小样本学习是一种在只有少量示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
71. 集成学习(Ensemble Learning):集成学习是一种结合多个模型预测以提高整体性能的方法。在这种方法中,多个模型对同一问题进行预测,然后通过某种方式(如平均、投票等)将预测结果结合起来。集成学习通常用于提高模型的稳定性和准确性。
72. 生成对抗网络(Generative Adversarial Networks,GANs):生成对抗网络是一种由生成器和判别器组成的深度学习模型。生成器试图生成与真实数据相似的数据,而判别器试图区分真实数据和生成数据。GANs通常用于图像生成、文本生成等领域。
73. 图神经网络(Graph Neural Networks,GNNs):图神经网络是一种用于处理图结构数据的深度学习模型。GNNs通常用于社交网络分析、推荐系统等领域。
74. 迁移学习(Transfer Learning):迁移学习是一种利用已经在一个任务上学到的知识来解决另一个相关任务的方法。这种学习方式通常用于解决数据不足或难以获取的问题。
76. 增量学习(Incremental Learning):增量学习是一种逐步学习新数据的方法。在这种学习方式中,算法从旧数据中学习,并逐步更新模型以适应新数据。增量学习通常用于解决数据流问题,即数据不断变化的情况。
77. 零样本学习(Zeroshot Learning):零样本学习是一种在没有见过任何示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
78. 小样本学习(Fewshot Learning):小样本学习是一种在只有少量示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
80. 集成学习(Ensemble Learning):集成学习机器学习是一个广泛的领域,它涵盖了多种分类方法。以下是几种主要的机器学习分类:
1. 监督学习(Supervised Learning):监督学习是一种有指导的学习方式,其中算法从标记的训练数据中学习,以预测新的、未标记的数据。这种学习方式包括分类和回归问题。分类问题试图预测离散的输出值,如电子邮件是否为垃圾邮件,而回归问题则试图预测连续的输出值,如房价。
2. 无监督学习(Unsupervised Learning):无监督学习是一种没有指导的学习方式,其中算法从未标记的数据中学习,以发现数据中的模式和结构。这种学习方式包括聚类和关联规则学习问题。聚类问题试图将数据分组为具有相似特征的簇,而关联规则学习问题则试图发现数据中项之间的频繁共现关系。
3. 半监督学习(Semisupervised Learning):半监督学习是一种结合了监督学习和无监督学习的方法。在这种学习方式中,算法从部分标记的数据中学习,以预测新的、未标记的数据。这种学习方式适用于标记数据昂贵或难以获得的情况。
4. 强化学习(Reinforcement Learning):强化学习是一种通过与环境交互来学习如何执行特定任务的方法。在这种学习方式中,智能体(agent)通过与环境的交互来学习执行特定任务的最佳策略。强化学习通常用于解决具有明确目标的问题,如游戏、机器人控制等。
5. 深度学习(Deep Learning):深度学习是一种使用神经网络来学习数据表示的方法。神经网络是一种由多个层组成的计算模型,每层都负责从输入数据中提取特征。深度学习在图像识别、自然语言处理、语音识别等领域取得了显著的成果。
6. 转移学习(Transfer Learning):转移学习是一种将一个领域学习到的知识应用到另一个领域的方法。在这种学习方式中,算法从一个领域(源领域)学习,并将学到的知识应用到另一个领域(目标领域)。转移学习通常用于解决目标领域数据不足的问题。
7. 元学习(Meta Learning):元学习是一种学习如何学习的方法。在这种学习方式中,算法从一个或多个任务中学习,并将学到的知识应用到新的任务中。元学习通常用于解决小样本学习问题,即当训练数据量有限时,如何快速适应新任务。
8. 自监督学习(Selfsupervised Learning):自监督学习是一种使用未标记数据来学习表示的方法。在这种学习方式中,算法从未标记的数据中学习,以发现数据中的模式和结构。自监督学习通常用于图像识别、自然语言处理等领域。
9. 多任务学习(Multitask Learning):多任务学习是一种同时学习多个相关任务的方法。在这种学习方式中,算法从一个或多个任务中学习,并将学到的知识应用到其他任务中。多任务学习通常用于解决相关任务之间的知识共享问题。
11. 生成对抗网络(Generative Adversarial Networks,GANs):生成对抗网络是一种由生成器和判别器组成的深度学习模型。生成器试图生成与真实数据相似的数据,而判别器试图区分真实数据和生成数据。GANs通常用于图像生成、文本生成等领域。
12. 图神经网络(Graph Neural Networks,GNNs):图神经网络是一种用于处理图结构数据的深度学习模型。GNNs通常用于社交网络分析、推荐系统等领域。
14. 增量学习(Incremental Learning):增量学习是一种逐步学习新数据的方法。在这种学习方式中,算法从旧数据中学习,并逐步更新模型以适应新数据。增量学习通常用于解决数据流问题,即数据不断变化的情况。
15. 零样本学习(Zeroshot Learning):零样本学习是一种在没有见过任何示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
16. 小样本学习(Fewshot Learning):小样本学习是一种在只有少量示例的情况下学习新类别的方法。这种学习方式通常用于解决类别扩展问题,即当出现新的、未见过的新类别时,如何快速适应。
18. 集成学习(Ensemble Learning):集成学习是一种结合多个模型预测以提高整体性能的方法。在这种方法中,多个模型对同一问题进行预测,然后通过某种方式(如平均、投票等)将预测结果结合起来。集成学习通常用于提高模型的稳定性和准确性。
这些分类方法涵盖了机器学习的不同方面和应用领域,为解决各种实际问题提供了多种工具和技术。
机器学习分类:探索数据科学的基石
机器学习作为数据科学的核心领域之一,其分类算法在众多应用场景中扮演着至关重要的角色。本文将深入探讨机器学习中的分类算法,分析其原理、应用以及优缺点。
一、什么是机器学习分类
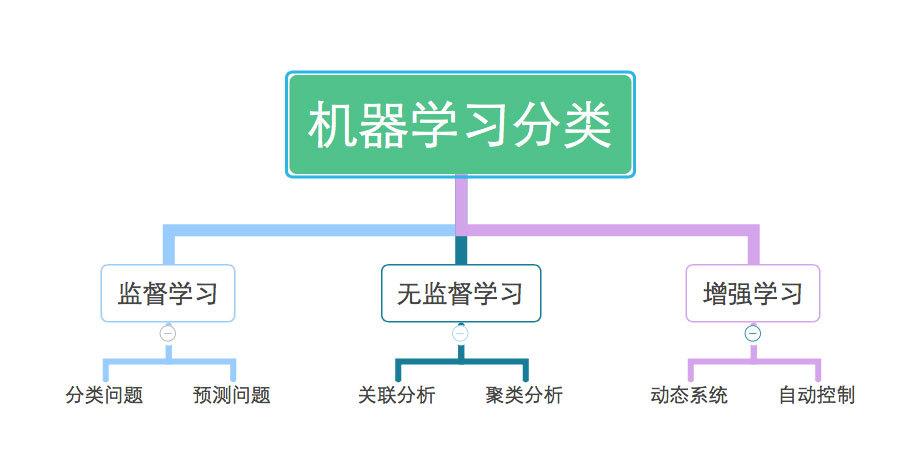
机器学习分类是指通过算法从数据中学习规律,对未知数据进行分类的过程。分类算法的目标是建立一个模型,该模型能够根据输入的特征数据,预测出数据所属的类别。
二、常见的机器学习分类算法
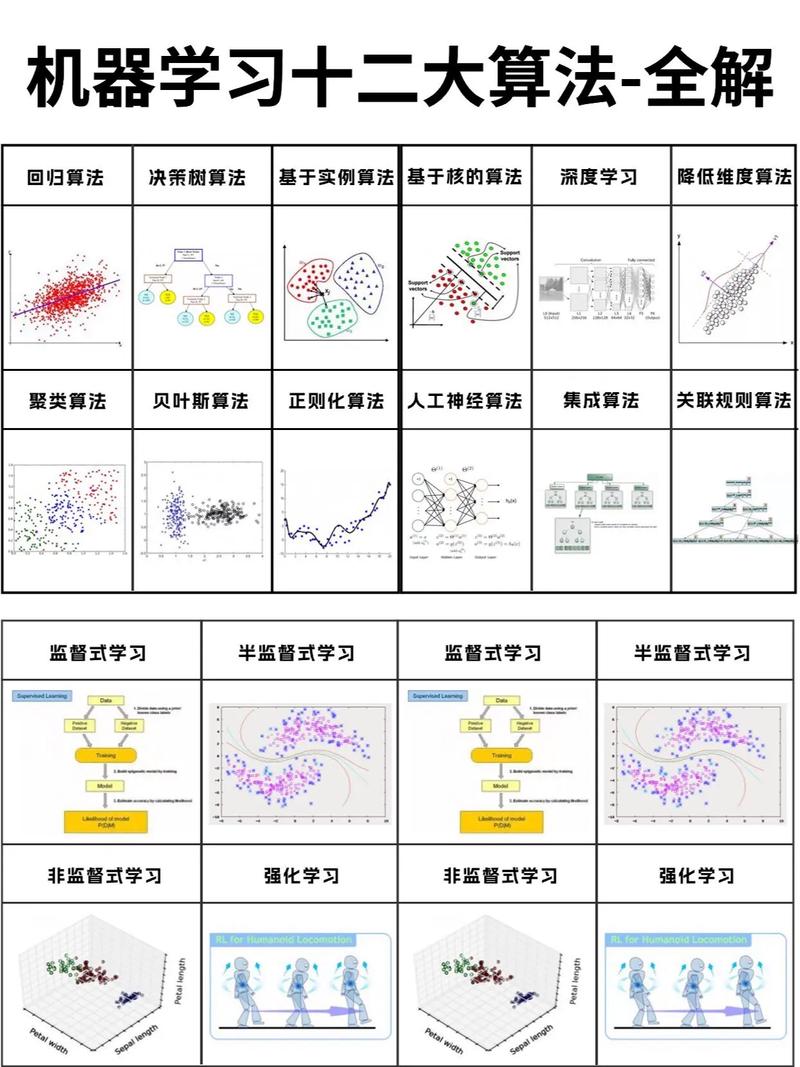
1. 线性回归
线性回归是一种简单的分类算法,适用于线性可分的数据。其基本思想是通过线性模型拟合数据,从而预测出数据所属的类别。
2. 逻辑回归
逻辑回归是一种基于概率的线性分类模型,适用于二分类问题。其核心思想是使用逻辑函数将线性回归模型的输出转换为概率值,从而判断数据所属的类别。
3. 决策树
决策树是一种基于树结构的分类算法,通过一系列的决策规则将数据划分为不同的类别。决策树具有直观易懂、易于解释的特点。
4. 随机森林
随机森林是一种集成学习方法,通过构建多个决策树,并对它们的预测结果进行投票,从而提高分类的准确率。随机森林具有鲁棒性强、泛化能力好的特点。
5. 支持向量机(SVM)
支持向量机是一种基于间隔最大化原理的分类算法,通过寻找最优的超平面将数据划分为不同的类别。SVM在处理高维数据时具有较好的性能。
6. K最近邻(KNN)
K最近邻是一种基于距离的简单分类算法,通过计算待分类数据与训练集中每个样本的距离,选择距离最近的K个样本,并根据这K个样本的类别进行投票,从而预测待分类数据的类别。
三、机器学习分类算法的应用

1. 金融领域
在金融领域,分类算法可以用于信用评分、欺诈检测、股票预测等任务。例如,通过分析客户的信用历史、消费习惯等数据,预测客户是否具有违约风险。
2. 医疗领域
在医疗领域,分类算法可以用于疾病诊断、药物研发、患者分类等任务。例如,通过分析患者的病历、基因信息等数据,预测患者是否患有某种疾病。
3. 零售领域
在零售领域,分类算法可以用于客户细分、商品推荐、库存管理等任务。例如,通过分析客户的购买历史、浏览记录等数据,预测客户可能感兴趣的商品。
四、机器学习分类算法的优缺点
1. 优点
(1)分类算法可以处理大量数据,提高预测的准确率。
(2)分类算法具有较好的泛化能力,适用于不同的应用场景。
(3)分类算法可以解释性强,便于理解模型的预测结果。
2. 缺点
(1)分类算法对数据质量要求较高,数据预处理工作量大。
(2)分类算法在处理非线性问题时效果较差。
(3)分类算法的参数较多,需要调整和优化。
机器学习分类算法在众多领域发挥着重要作用。了解不同分类算法的原理、应用和优缺点,有助于我们更好地选择合适的算法解决实际问题。随着机器学习技术的不断发展,分类算法将更加成熟,为各行各业带来更多价值。