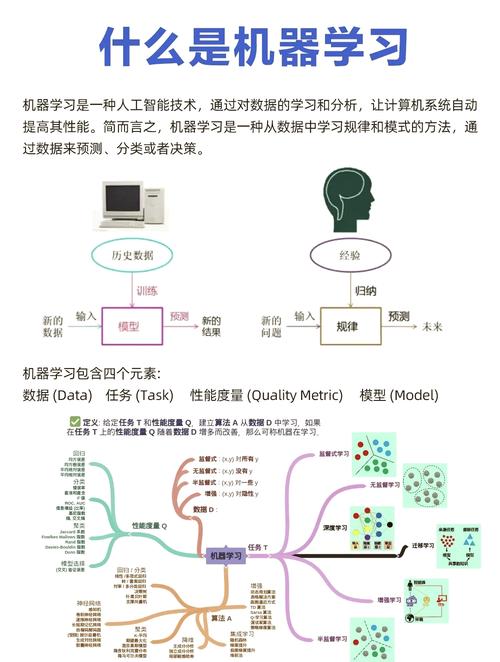
机器学习是人工智能的一个分支,它使计算机系统能够从数据中学习,并做出预测或决策,而无需明确编程。以下是机器学习的基础教程,我们将涵盖一些关键概念和步骤。
1. 导入必要的库
在开始之前,我们需要导入一些常用的Python库,如`numpy`、`pandas`、`matplotlib`、`scikitlearn`等。
2. 数据准备
数据是机器学习的基础。首先,我们需要加载数据,然后进行预处理,包括缺失值处理、数据转换等。
```python 加载数据data = pd.read_csv
显示前几行数据printqwe2
数据预处理 处理缺失值data = data.dropna
特征工程X = data.dropy = data```
3. 数据可视化
在建模之前,了解数据的分布和特征之间的关系是非常重要的。
```python 可视化特征和目标变量之间的关系plt.scatter, yqwe2plt.xlabelplt.ylabelplt.show```
4. 模型选择与训练
选择合适的机器学习模型是关键。在这个例子中,我们使用线性回归模型。
```python 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split
5. 模型评估
评估模型性能是机器学习过程中的重要步骤。我们可以使用均方误差(MSE)来评估模型的性能。
计算MSEmse = mean_squared_errorprint```
6. 模型优化
根据模型性能,我们可以尝试不同的模型或调整模型参数来优化性能。
```python 尝试不同的模型,如决策树from sklearn.tree import DecisionTreeRegressor
计算MSEdt_mse = mean_squared_errorprint```
7. 模型部署
一旦模型训练和优化完成,我们可以将其部署到生产环境中,用于实际的数据预测。
```python 保存模型import joblibjoblib.dump
这就是机器学习基础教程的概述。在实际应用中,你可能需要根据具体的数据和问题选择不同的模型和参数,并进行更深入的数据分析和模型优化。
Python机器学习基础教程
随着大数据时代的到来,机器学习(Machine Learning,ML)已经成为人工智能领域的一个重要分支。Python作为一种广泛使用的编程语言,因其简洁、易读和强大的库支持,成为了机器学习领域的首选语言。本文将为您介绍Python机器学习的基础知识,帮助您入门这一领域。
1. 安装Python
首先,您需要在您的计算机上安装Python。您可以从Python的官方网站(https://www.python.org/)下载最新版本的Python安装包。安装过程中,请确保勾选“Add Python to PATH”选项,以便在命令行中直接运行Python。
2. 安装Anaconda
Anaconda是一个Python发行版,它包含了大量的科学计算和数据分析库。安装Anaconda可以简化Python环境的搭建过程。您可以从Anaconda的官方网站(https://www.anaconda.com/)下载并安装Anaconda。
3. 安装Jupyter Notebook
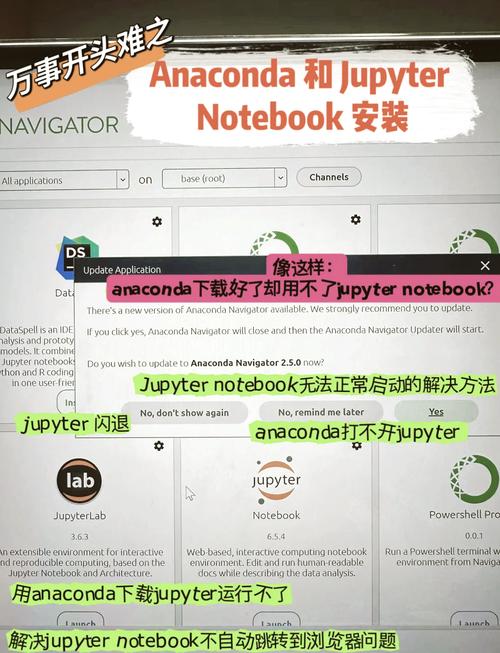
Jupyter Notebook是一个交互式计算环境,它允许您将代码、方程、可视化和解释性文本混合在一起。安装Jupyter Notebook可以方便地进行机器学习实验。您可以通过以下命令安装Jupyter Notebook:
conda install notebook
1. NumPy

NumPy是一个强大的Python库,用于处理大型多维数组。它是Python科学计算的基础库,也是机器学习库的基础。NumPy提供了高效的数组操作和数学函数。
2. Pandas

Pandas是一个数据分析库,它提供了数据结构和数据分析工具,可以轻松地处理和分析结构化数据。Pandas是机器学习项目中数据预处理的重要工具。
3. Matplotlib
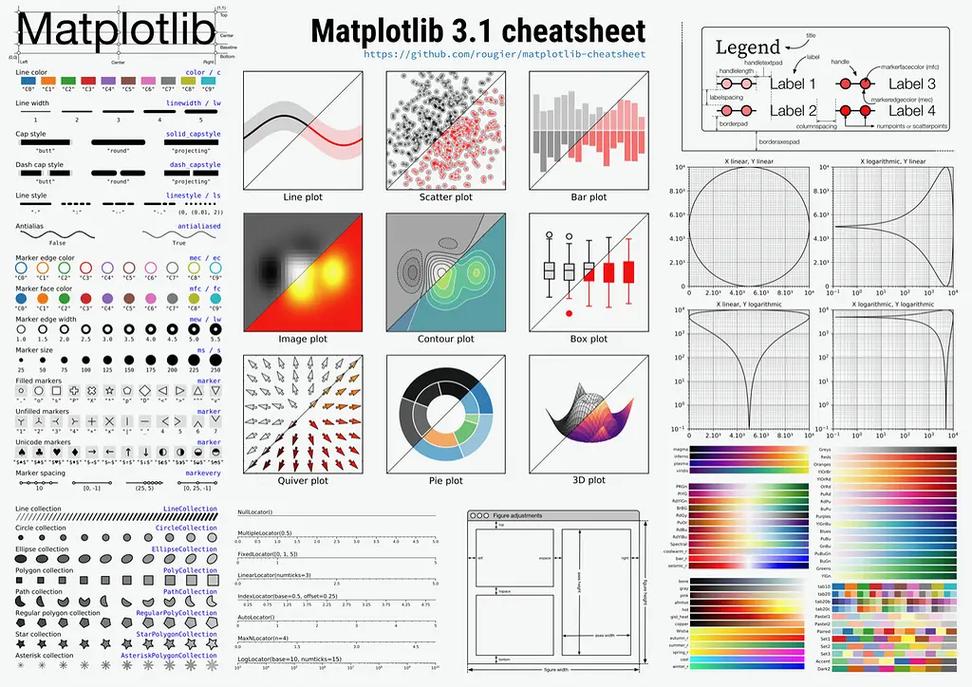
Matplotlib是一个绘图库,它提供了丰富的绘图功能,可以用于可视化数据。在机器学习中,可视化可以帮助我们更好地理解数据和模型。
4. Scikit-learn
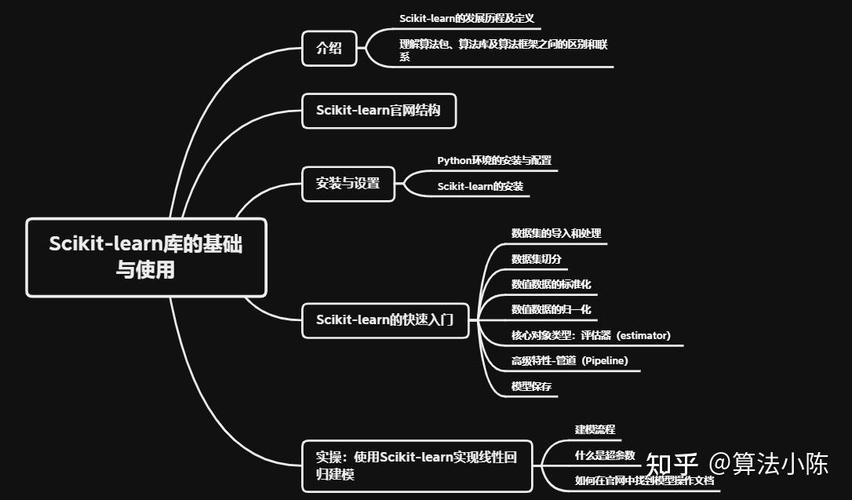
Scikit-learn是一个开源的机器学习库,它提供了多种机器学习算法的实现,包括分类、回归、聚类等。Scikit-learn是Python机器学习中最常用的库之一。
2. 模型选择

模型选择是机器学习中的一个重要步骤。根据问题的不同,可能需要选择不同的模型。常见的机器学习模型包括线性回归、决策树、支持向量机等。
3. 模型评估
模型评估是衡量模型性能的过程。常用的评估指标包括准确率、召回率、F1分数等。通过评估指标,我们可以了解模型的优缺点,并进行相应的调整。
1. 数据预处理
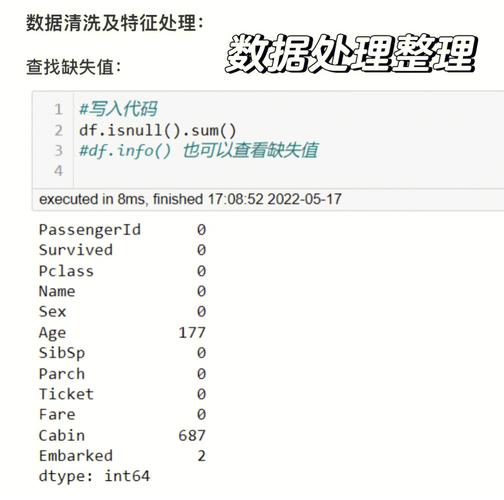
数据预处理是机器学习项目中的第一步。它包括数据清洗、数据转换、特征选择等操作。预处理数据可以帮助提高模型的性能。
2. 模型训练
模型训练是使用训练数据来训练模型的过程。在Scikit-learn中,您可以使用fit()函数来训练模型。
3. 模型预测
模型预测是使用训练好的模型来预测新数据的过程。在Scikit-learn中,您可以使用predict()函数来预测新数据。
4. 模型评估

在模型预测后,您可以使用评估指标来评估模型的性能。如果模型性能不理想,您可能需要回到数据预处理或模型选择步骤进行调整。
本文介绍了Python机器学习的基础知识,包括环境搭建、常用库、基本概念和项目实践。通过学习本文,您应该能够开始使用Python进行简单的机器学习项目。随着您对机器学习的深入,您将能够掌握更高级的技术和算法。祝您在机器学习领域取得成功!