
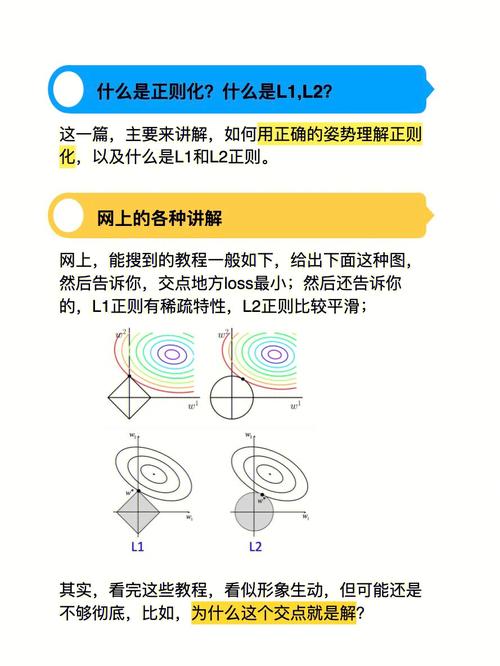
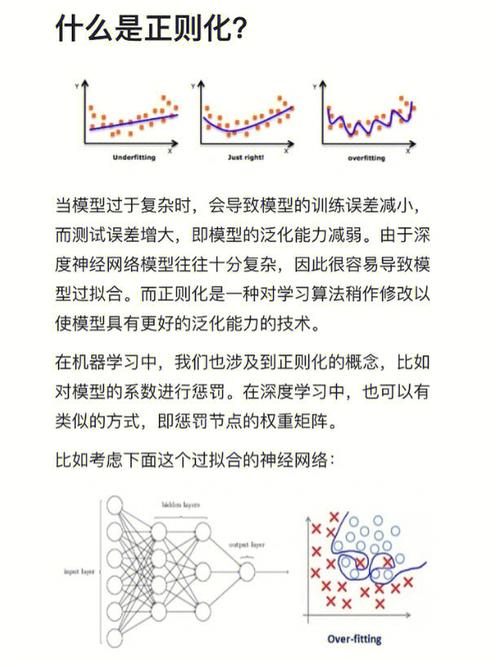
机器学习中的正则化是一种技术,用于防止模型过拟合,即避免模型在训练数据上表现良好,但在新数据上表现不佳。正则化通过在损失函数中添加一个惩罚项来实现,这个惩罚项通常与模型的权重相关。
正则化的目的是限制模型权重的值,从而防止模型过于复杂。正则化技术有多种,其中最常见的是L1正则化和L2正则化。
L1正则化通过在损失函数中添加权重向量的L1范数来实现,即所有权重绝对值之和。L1正则化倾向于产生稀疏的权重向量,即许多权重为零,这在特征选择中很有用。
L2正则化通过在损失函数中添加权重向量的L2范数来实现,即所有权重平方和的平方根。L2正则化倾向于产生较小的权重,但不一定为零。L2正则化在许多机器学习算法中都很常见,例如支持向量机、逻辑回归和神经网络。
除了L1和L2正则化,还有其他正则化技术,例如dropout正则化、数据增强和提前停止等。这些技术可以单独使用,也可以组合使用,以获得更好的模型性能。
正则化是机器学习中一个重要的概念,它可以提高模型的泛化能力,减少过拟合的风险,从而在新的数据上获得更好的表现。
机器学习正则化概述
随着机器学习技术的快速发展,模型复杂度的增加使得过拟合问题日益突出。过拟合是指模型在训练数据上表现良好,但在未见过的数据上表现不佳的现象。为了解决这一问题,正则化技术应运而生。本文将介绍机器学习中的正则化方法,探讨其在解决过拟合问题中的应用。
什么是正则化
正则化是一种在机器学习模型中添加惩罚项的技术,旨在控制模型复杂度,防止过拟合。正则化通过限制模型参数的绝对值或平方和,使得模型在训练过程中更加平滑,从而提高泛化能力。
正则化的类型

在机器学习中,常见的正则化方法包括L1正则化、L2正则化和弹性网络正则化等。
L1正则化
L1正则化也称为Lasso正则化,其惩罚项为模型参数的绝对值之和。L1正则化能够将一些参数压缩到零,从而实现特征选择。
L2正则化
L2正则化也称为Ridge正则化,其惩罚项为模型参数的平方和。L2正则化能够使模型参数更加平滑,但不会将参数压缩到零。
弹性网络正则化
弹性网络正则化是L1正则化和L2正则化的结合,通过调整两个正则化项的权重,可以同时实现特征选择和参数平滑。
正则化在模型中的应用

线性回归
在线性回归中,L1正则化和L2正则化可以用于特征选择,提高模型的泛化能力。
逻辑回归
逻辑回归模型中,L1正则化和L2正则化可以用于控制模型复杂度,防止过拟合。
支持向量机
在支持向量机中,L1正则化可以用于特征选择,而L2正则化可以用于控制模型复杂度。
神经网络
神经网络中,L1正则化和L2正则化可以用于控制网络参数的规模,防止过拟合。
正则化的实现
损失函数添加正则化项
在损失函数中添加正则化项,如L1或L2惩罚项,可以控制模型复杂度。
优化算法结合正则化
在优化算法中结合正则化,如梯度下降法,可以同时优化模型参数和正则化项。
正则化参数调整
正则化参数(如正则化强度)的调整对于模型性能至关重要。通常需要通过交叉验证等方法来选择合适的正则化参数。
正则化是解决机器学习过拟合问题的有效手段。通过控制模型复杂度,正则化可以提高模型的泛化能力。本文介绍了正则化的基本概念、类型、应用和实现方法,为读者提供了关于正则化的全面了解。








