
1. 数据预处理:数据分析师需要对原始数据进行清洗、转换和标准化,以便机器学习模型能够更好地理解和处理这些数据。
2. 特征工程:特征工程是机器学习中的一个重要步骤,它涉及到从原始数据中提取有用的特征,这些特征将用于构建机器学习模型。
3. 模型选择:数据分析师需要根据问题的性质和数据的特点,选择合适的机器学习模型。这可能包括监督学习、无监督学习、强化学习等。
4. 模型训练:一旦选择了模型,数据分析师需要使用训练数据来训练模型。这涉及到调整模型的参数,以最小化模型在训练数据上的误差。
5. 模型评估:数据分析师需要评估模型的性能,以确保它能够在新的、未见过的数据上做出准确的预测。这通常涉及到使用测试数据集来评估模型的准确率、召回率、F1分数等指标。
6. 模型部署:一旦模型被训练和评估,数据分析师可能需要将其部署到生产环境中,以便它可以实时地处理新的数据并做出预测。
7. 持续监控和优化:模型部署后,数据分析师需要持续监控模型的性能,并根据需要对其进行优化,以确保它始终能够提供准确的结果。
8. 可解释性和透明度:数据分析师还需要确保机器学习模型的决策过程是可解释的,以便用户可以理解模型的预测结果。
9. 遵守道德和法规:在应用机器学习时,数据分析师需要确保遵守相关的道德和法规,例如保护个人隐私和数据安全。
10. 沟通和协作:数据分析师需要与团队成员、业务部门和其他利益相关者进行有效沟通,以确保机器学习项目的顺利进行。
总之,数据分析师在机器学习领域扮演着关键角色,他们需要具备广泛的知识和技能,以便能够成功地应用机器学习技术来解决实际问题。
数据分析师的机器学习之旅:从入门到实战
随着大数据时代的到来,机器学习技术在各个领域得到了广泛应用。数据分析师作为连接数据与业务的关键角色,掌握机器学习技能显得尤为重要。本文将带领读者从机器学习的基础知识开始,逐步深入到实战应用,帮助数据分析师开启机器学习之旅。
一、机器学习概述
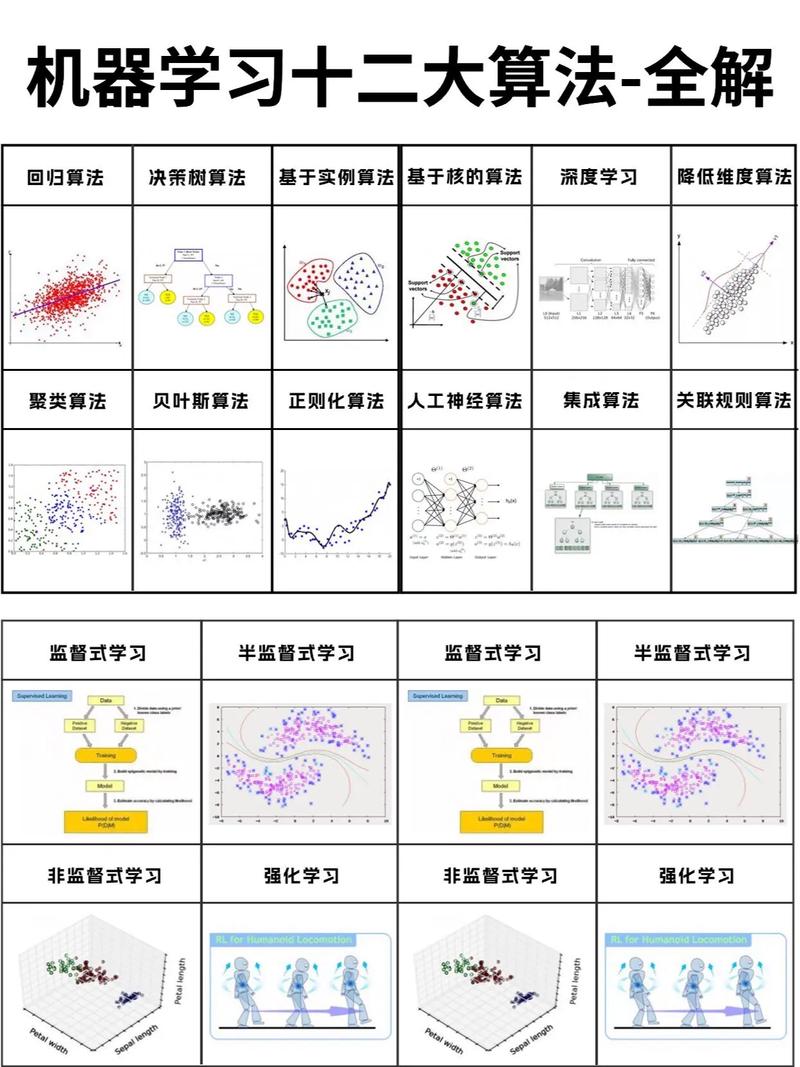
机器学习是人工智能的一个分支,它使计算机能够从数据中学习并做出决策或预测。根据学习方式的不同,机器学习可以分为监督学习、非监督学习和强化学习。其中,监督学习是数据分析师最常用的学习方式,它通过已知的输入和输出数据来训练模型,从而预测未知数据。
二、数据预处理
在机器学习项目中,数据预处理是至关重要的步骤。它包括数据收集、数据清洗、数据转换和特征工程等环节。
1. 数据收集
数据收集是获取所需数据的过程。数据来源可以是CSV文件、数据库、API等。在R语言中,可以使用read.csv()、read.dbf()、readRDS()等函数进行数据导入。
2. 数据清洗
数据清洗是指处理缺失值、异常值等不完整或不准确的数据。在R语言中,可以使用dplyr包中的mutate()、filter()、arrange()等函数进行数据清洗。
3. 数据转换
数据转换是指将数据转换为适合模型训练的形式。例如,归一化和标准化是常用的数据转换方法。在R语言中,可以使用caret包中的preProcess()函数进行数据转换。
4. 特征工程
特征工程是指从原始数据中提取出对模型训练有帮助的特征。特征选择和降维是常用的特征工程方法。在R语言中,可以使用caret包中的trainControl()函数进行特征选择和降维。
三、模型构建与训练

在数据预处理完成后,接下来就是模型构建与训练。以下是常用的机器学习算法和R语言中的实现方法:
1. 线性回归
线性回归是一种简单的监督学习算法,用于预测连续值。在R语言中,可以使用lm()函数进行线性回归模型训练。
2. 逻辑回归
逻辑回归是一种用于预测离散值的监督学习算法。在R语言中,可以使用glm()函数进行逻辑回归模型训练。
3. 决策树
决策树是一种常用的非监督学习算法,用于分类和回归。在R语言中,可以使用rpart包中的rpart()函数进行决策树模型训练。
4. 支持向量机
支持向量机是一种常用的分类算法,用于处理高维数据。在R语言中,可以使用e1071包中的svm()函数进行支持向量机模型训练。
四、模型评估与优化
1. 混淆矩阵
混淆矩阵是一种常用的模型评估方法,用于评估分类模型的性能。在R语言中,可以使用caret包中的confusionMatrix()函数计算混淆矩阵。
2. ROC曲线
ROC曲线是一种常用的模型评估方法,用于评估分类模型的性能。在R语言中,可以使用pROC包中的roc()函数绘制ROC曲线。
3. 超参数调优
超参数调优是指调整模型参数以获得最佳性能。在R语言中,可以使用caret包中的train()函数进行超参数调优。
本文从机器学习概述、数据预处理、模型构建与训练、模型评估与优化等方面,介绍了数据分析师如何掌握机器学习技能。通过学习本文,数据分析师可以更好地应对大数据时代的挑战,为业务决策提供有力支持。








