
1. 监督学习(Supervised Learning): 线性回归(Linear Regression) 逻辑回归(Logistic Regression) 决策树(Decision Trees) 随机森林(Random Forest) 支持向量机(Support Vector Machines, SVM) 神经网络(Neural Networks) 梯度提升树(Gradient Boosting Trees, 如XGBoost)
2. 无监督学习(Unsupervised Learning): 聚类(Clustering,如KMeans、层次聚类) 主成分分析(Principal Component Analysis, PCA) 自编码器(Autoencoders) 生成对抗网络(Generative Adversarial Networks, GANs)
3. 半监督学习(SemiSupervised Learning): 标记传播(Label Propagation) 图半监督学习(GraphBased SemiSupervised Learning)
4. 强化学习(Reinforcement Learning): Q学习(QLearning) 深度Q网络(Deep QNetwork, DQN) 演员评论家方法(ActorCritic Methods) 模仿学习(Imitation Learning)
5. 迁移学习(Transfer Learning): 微调(FineTuning) 特征提取(Feature Extraction)
这些方法在不同的应用场景和任务中都有其独特的优势,选择合适的机器学习方法通常需要根据具体问题的特点、数据集的大小和质量以及计算资源等因素来决定。
机器学习方法概述
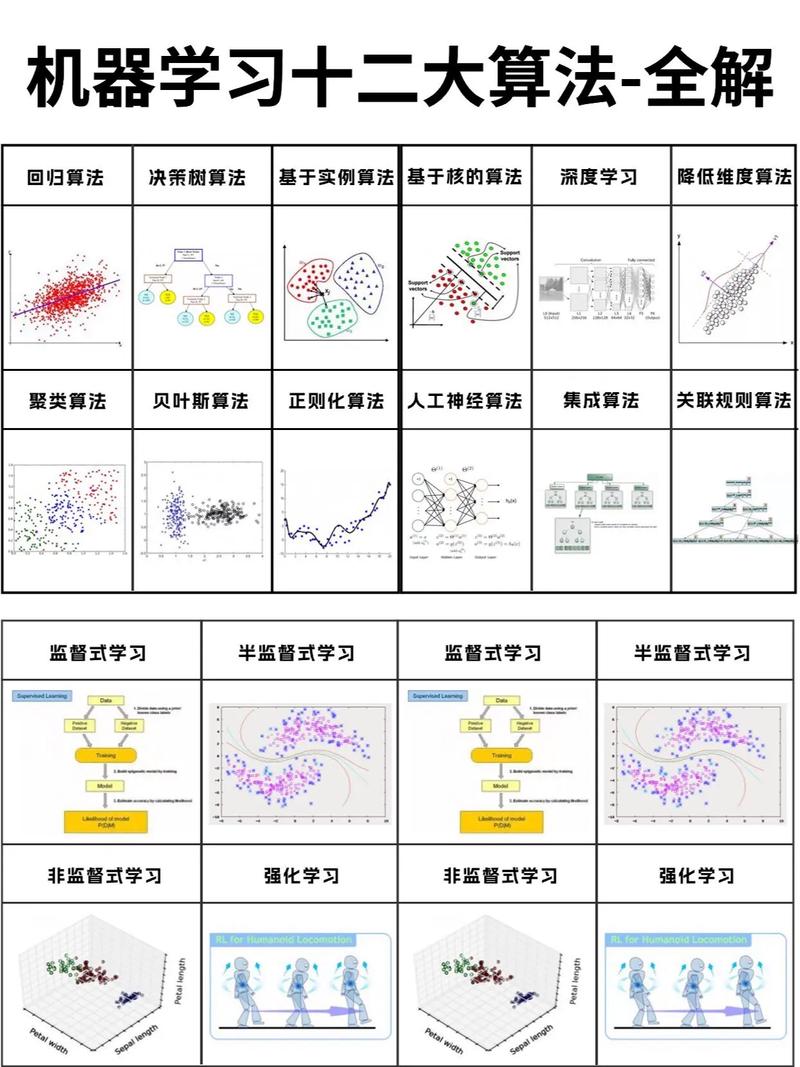
随着大数据时代的到来,机器学习(Machine Learning,ML)技术在各个领域得到了广泛应用。机器学习是一种使计算机系统能够从数据中学习并做出决策或预测的技术。本文将介绍几种常见的机器学习方法。
监督学习

监督学习是机器学习中最基础的方法之一,它通过训练数据集来学习输入和输出之间的关系。以下是几种常见的监督学习方法:
线性回归
线性回归是一种简单的监督学习方法,用于预测连续值。它假设输入变量和输出变量之间存在线性关系。
逻辑回归
逻辑回归是一种用于预测二元分类问题的监督学习方法。它通过将线性回归的输出转换为概率值,从而预测样本属于某个类别的可能性。
支持向量机(SVM)
支持向量机是一种强大的分类和回归方法,它通过找到一个最优的超平面来将数据分为不同的类别。
无监督学习
聚类
聚类是一种将相似的数据点分组在一起的方法。常见的聚类算法包括K-means、层次聚类和DBSCAN等。
降维
降维是一种减少数据维度数量的方法,常见的降维算法包括主成分分析(PCA)、线性判别分析(LDA)和t-SNE等。
强化学习
强化学习是一种通过奖励和惩罚来指导智能体学习最优策略的方法。以下是几种常见的强化学习方法:
Q学习
Q学习是一种基于值函数的强化学习方法,它通过学习状态-动作值函数来指导智能体的决策。
深度Q网络(DQN)
深度Q网络是一种结合了深度学习和Q学习的强化学习方法,它通过神经网络来近似Q函数。
集成学习方法
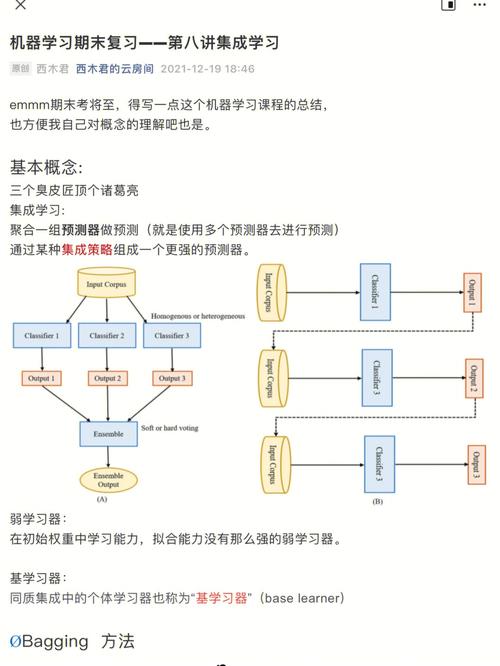
集成学习是一种将多个模型组合起来以提高预测性能的方法。以下是几种常见的集成学习方法:
Bagging
Bagging是一种通过从原始数据集中随机抽取多个子集来训练多个模型的方法,如随机森林。
Boosting
Boosting是一种通过迭代地训练多个模型,并逐渐调整每个模型的权重来提高预测性能的方法,如XGBoost。
Stacking
Stacking是一种将多个模型作为基模型,并将它们的预测结果作为输入来训练一个最终模型的集成学习方法。
机器学习领域的方法繁多,本文仅介绍了部分常见的方法。随着技术的不断发展,新的机器学习方法也在不断涌现。了解和掌握这些方法对于从事机器学习研究和应用具有重要意义。
- 机器学习
- 监督学习
- 无监督学习
- 强化学习
- 集成学习
- 线性回归
- 逻辑回归
- 支持向量机
- 聚类
- 降维
- Q学习
- 深度Q网络
- Bagging
- Boosting
- Stacking







