
开源数据仓库:大数据时代的利器

随着大数据时代的到来,企业对于数据存储和分析的需求日益增长。开源数据仓库作为一种灵活、成本效益高的解决方案,受到了广泛的关注。本文将介绍开源数据仓库的概念、优势以及主流的开源数据仓库解决方案。
一、什么是开源数据仓库?
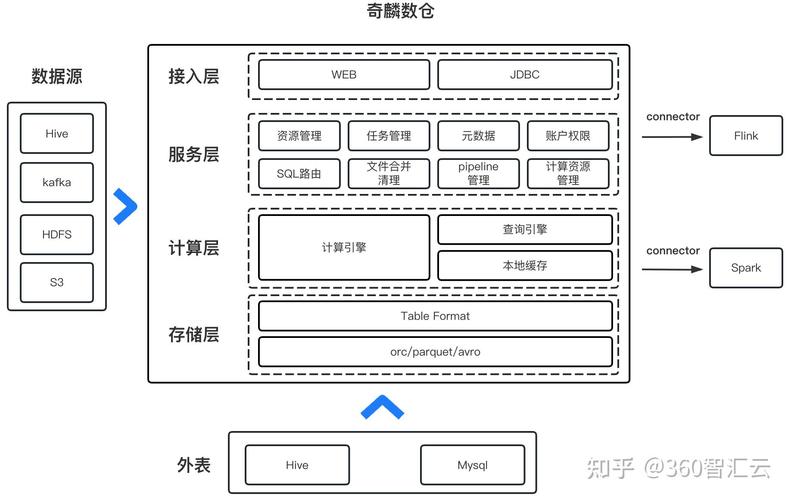
开源数据仓库是指基于开源协议发布的数据仓库软件。它允许用户免费使用、修改和分发,同时社区提供技术支持和文档。开源数据仓库的核心优势在于其灵活性和成本效益,用户可以根据自己的需求进行定制和优化。
二、开源数据仓库的优势
1. 成本效益:开源数据仓库软件免费使用,降低了企业的软件成本。
2. 灵活性:用户可以根据自己的需求进行定制和优化,满足特定业务场景。
3. 社区支持:开源项目拥有庞大的社区,用户可以获取技术支持和文档。
4. 技术创新:开源项目鼓励技术创新,不断推动数据仓库技术的发展。
三、主流开源数据仓库解决方案
1. Apache Hadoop Hive
Apache Hadoop Hive是一个建立在Hadoop之上的数据仓库工具,提供了一种类似SQL的查询语言HQL。Hive适用于处理PB级数据,具有易用性和扩展性。Hive的查询延迟较高,不适合实时查询。
2. Apache Spark SQL
Apache Spark SQL是Apache Spark的一部分,支持SQL查询、DataFrame以及RDD。Spark SQL利用内存计算,显著提升数据处理速度,兼容性强,易于与其他Spark组件集成。但Spark SQL的学习曲线相对较陡峭。
3. ClickHouse
ClickHouse是一款高性能的开源列式存储数据库,适用于在线分析处理(OLAP)场景。ClickHouse具有高并发、低延迟、可扩展性强等特点,但相对较新的技术,社区支持可能不如其他成熟的开源项目。
4. Greenplum
Greenplum是一款基于PostgreSQL的开源数据仓库,具有高性能、可扩展性等特点。Greenplum适用于大规模数据仓库场景,但相对较重的系统资源消耗可能成为其应用的瓶颈。
5. Apache Druid
Apache Druid是一款开源的实时分析数据库,适用于实时查询和分析场景。Druid具有高并发、低延迟、可扩展性强等特点,但相对较新的技术,社区支持可能不如其他成熟的开源项目。
开源数据仓库在当前大数据时代具有广泛的应用前景。企业可以根据自己的业务需求和预算选择合适的数据仓库解决方案。在选择开源数据仓库时,应考虑其易用性、性能、可扩展性、社区支持等因素。随着技术的不断发展,开源数据仓库将为大数据时代的企业提供更加高效、便捷的数据存储和分析服务。








