YOLO(You Only Look Once)是一种用于实时对象检测的机器学习算法。它通过单个神经网络在单次前向传递中同时预测对象的位置和类别。YOLO算法的关键特点包括:
1. 端到端学习:YOLO直接从图像像素中学习,不需要额外的区域提议步骤。
2. 实时性能:YOLO可以在多种硬件上实现实时对象检测,使其在需要快速响应的应用中非常有用。
3. 统一的网络结构:YOLO使用一个统一的网络结构来处理不同大小的输入图像,这使得它更容易扩展和优化。
4. 多尺度预测:YOLO在不同尺度上进行预测,以检测不同大小的对象。
5. 损失函数:YOLO使用一个多任务损失函数,同时考虑对象位置、类别和置信度。
YOLO算法已经在多个公开数据集上取得了显著的性能,包括COCO、PASCAL VOC等。它已经被广泛应用于自动驾驶、视频监控、人机交互等领域。
请注意,YOLO算法的最新版本和实现可能会随着时间而变化,因此建议查阅最新的研究论文和开源代码库以获取最新信息。
YOLO:机器学习中的目标检测神器
什么是YOLO?

YOLO(You Only Look Once)是一种流行的目标检测算法,由Joseph Redmon等人于2015年提出。与传统的两阶段目标检测算法(如R-CNN系列)相比,YOLO采用了一种单阶段检测方法,能够在单个网络中同时完成特征提取和目标检测,从而大大提高了检测速度。
YOLO的发展历程

自从YOLOv1以来,YOLO系列模型经历了多次迭代和改进。以下是YOLO系列模型的发展历程:
YOLOv1(2015):首次提出YOLO概念,实现了实时目标检测。
YOLOv2(2016):引入了锚框(anchor box)的概念,提高了检测精度。
YOLOv3(2018):结合了残差网络(ResNet)和特征金字塔网络(FPN),进一步提升了检测性能。
YOLOv4(2020):引入了CSPDarknet53作为主干网络,并引入了注意力机制和路径聚合网络(PANet),提高了检测速度和精度。
YOLOv5(2020):YOLOv5在YOLOv4的基础上进行了优化,简化了模型结构,提高了检测速度。
YOLOv6(2021):YOLOv6在YOLOv5的基础上进一步优化了模型结构,提高了检测速度和精度。
YOLOv7(2022):YOLOv7在YOLOv6的基础上引入了新的注意力机制和路径聚合网络,提高了检测性能。
YOLOv8(2023):YOLOv8在YOLOv7的基础上进一步优化了模型结构,提高了检测速度和精度。
YOLOv9(2023):YOLOv9在YOLOv8的基础上引入了新的注意力机制和路径聚合网络,提高了检测性能。
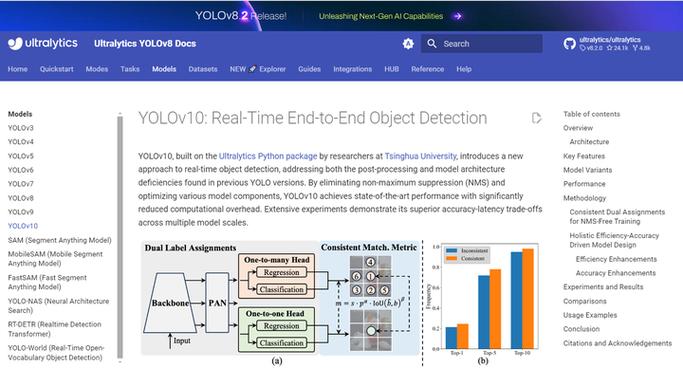
YOLOv10(2024):YOLOv10在YOLOv9的基础上进一步优化了模型结构,提高了检测速度和精度。
YOLO的优势

YOLO具有以下优势:
速度快:YOLO采用单阶段检测方法,检测速度快,适用于实时目标检测。
精度高:通过引入锚框、残差网络、注意力机制等,YOLO的检测精度得到了显著提高。
易于实现:YOLO的模型结构相对简单,易于实现和部署。
YOLO的应用领域
YOLO在以下领域得到了广泛应用:
自动驾驶:YOLO可以用于车辆检测、行人检测等,为自动驾驶系统提供实时目标检测。
视频监控:YOLO可以用于实时监控视频中的异常行为检测,提高安全监控效率。
工业检测:YOLO可以用于工业生产中的缺陷检测、产品质量检测等。
医疗影像分析:YOLO可以用于医学影像中的病变检测、疾病诊断等。
YOLO的局限性
尽管YOLO具有许多优势,但也存在一些局限性:
对小目标的检测效果不佳:由于锚框的存在,YOLO对小目标的检测效果可能不如其他算法。
对复杂场景的适应性较差:在复杂场景中,YOLO的检测效果可能受到遮挡、光照变化等因素的影响。
YOLO作为一种高效、准确的目标检测算法,在众多领域得到了广泛应用。随着YOLO系列模型的不断迭代和优化,YOLO的性能将得到进一步提升,为更多应用场景提供支持。