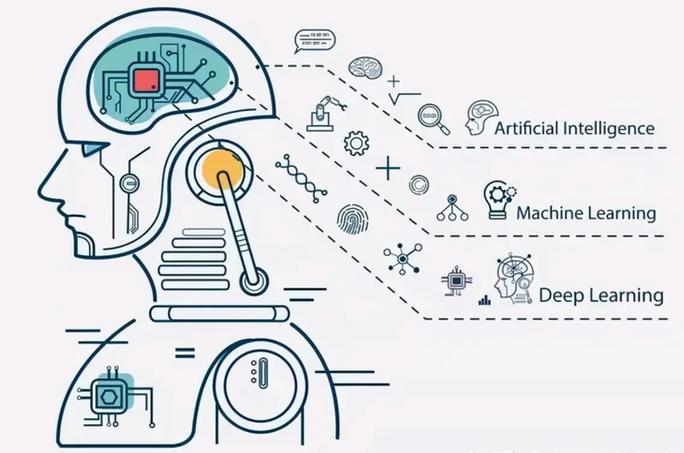
白话机器学习,简单来说,就是用通俗易懂的语言来解释机器学习这一领域。机器学习是人工智能的一个分支,它使计算机系统能够从数据中学习,并做出决策或预测。下面我将用白话来解释一些机器学习的基本概念:
1. 数据:就像学校里的书本一样,数据是机器学习的基础。它可以是数字、文字、图片、声音等任何形式的信息。
2. 特征:数据中的每个部分都可以看作是一个特征。比如,在描述一个苹果时,颜色、大小、形状等都是特征。
3. 模型:模型就像是学生,通过学习数据(书本)来掌握知识。机器学习模型会从数据中学习,以便在未来能够做出准确的预测或决策。
4. 训练:训练是让模型学习的过程。就像学生上课一样,模型会通过大量的数据来学习如何做出正确的预测。
5. 预测:一旦模型训练完成,它就可以用来预测新的数据。比如,训练一个模型来识别苹果,它就可以用来判断一个未知的水果是不是苹果。
6. 监督学习:这是机器学习的一种方法,类似于有老师指导的学习。模型会通过已知的数据(包括输入和输出)来学习,以便在未来能够正确地预测新的数据。
7. 无监督学习:这是另一种机器学习方法,类似于自学。模型会通过大量的数据来学习,但不一定知道每个数据的正确答案。这种方法通常用于发现数据中的模式或结构。
8. 深度学习:这是机器学习的一个子领域,它使用多层神经网络来学习数据。深度学习在图像识别、语音识别等领域取得了很大的成功。
9. 人工智能:人工智能是机器学习的一个更广泛的领域,它包括了机器学习、自然语言处理、计算机视觉等许多其他领域。人工智能的目标是使计算机系统能够像人类一样思考和学习。
10. 应用:机器学习已经被广泛应用于许多领域,如医疗、金融、交通、教育等。它可以帮助医生诊断疾病,帮助银行识别欺诈行为,帮助自动驾驶汽车识别道路上的障碍物,等等。
总之,机器学习是一种强大的工具,它可以帮助我们更好地理解数据,并做出更准确的预测和决策。随着技术的不断发展,机器学习将在我们的生活中扮演越来越重要的角色。
什么是机器学习?
机器学习,顾名思义,就是让机器通过学习来获取知识、技能,并能够自主做出决策的过程。简单来说,就是通过算法让计算机从数据中学习规律,然后根据这些规律来预测或做出决策。这就像我们人类通过学习和经验来提高自己的能力一样,机器学习也是让计算机变得更加智能的一种方式。
机器学习的分类
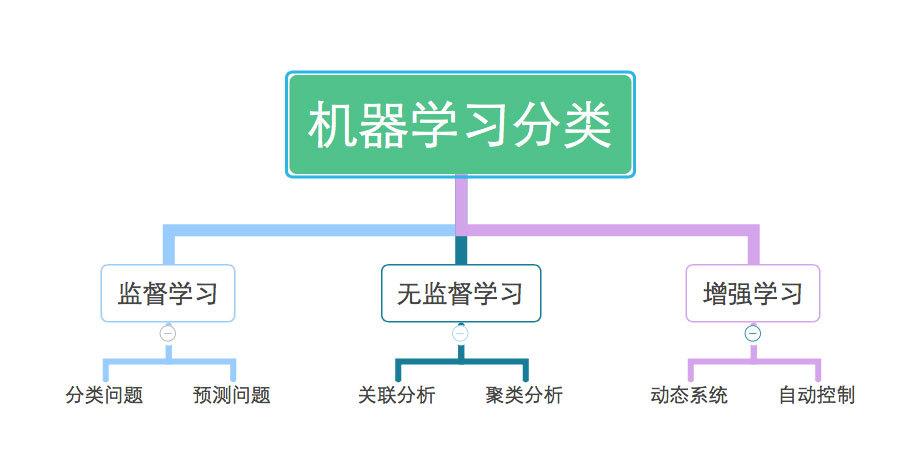
机器学习主要分为两大类:监督学习和无监督学习。
监督学习:这种学习方式需要大量的标注数据。比如,我们想要训练一个分类器来识别猫和狗的照片,就需要大量的猫和狗的图片,并且每张图片都标注了它是猫还是狗。机器学习算法会通过这些标注数据来学习,从而能够对新的图片进行分类。
无监督学习:与监督学习不同,无监督学习不需要标注数据。它主要是通过分析数据中的模式或结构来发现数据中的隐藏规律。例如,聚类算法可以将相似的数据点归为一组,从而帮助我们更好地理解数据的分布。
常见的机器学习算法
线性回归:用于预测连续值,比如房价或温度。
逻辑回归:用于预测离散的二分类结果,比如判断一个邮件是否为垃圾邮件。
决策树:通过树状结构来表示决策过程,适合处理分类和回归问题。
朴素贝叶斯:基于贝叶斯定理,用于处理文本分类问题。
支持向量机(SVM):通过找到一个超平面来最大化不同类别之间的间隔,用于分类和回归问题。
集成算法:如Adaboost、随机森林等,通过组合多个弱学习器来提高预测的准确性。
机器学习的应用

推荐系统:如Netflix、Amazon等,通过分析用户的历史行为来推荐电影、书籍或商品。
自然语言处理:如语音识别、机器翻译、情感分析等,让计算机能够理解和生成人类语言。
图像识别:如人脸识别、物体检测等,让计算机能够识别和理解图像中的内容。
医疗诊断:通过分析医学影像和患者数据,辅助医生进行疾病诊断。
机器学习的挑战
尽管机器学习取得了巨大的进步,但仍然面临着一些挑战:
数据质量:机器学习依赖于大量高质量的数据,数据质量问题会直接影响模型的性能。
过拟合:当模型在训练数据上表现很好,但在测试数据上表现不佳时,就发生了过拟合。这需要我们设计更有效的模型或使用正则化技术来解决这个问题。
可解释性:许多机器学习模型,如深度学习模型,被认为是“黑箱”,其内部工作机制难以解释。这限制了机器学习在需要透明度和可解释性的领域的应用。
机器学习是一个充满活力的研究领域,它正在改变我们的世界。通过理解机器学习的基本原理和应用,我们可以更好地利用这一技术来解决实际问题,创造更多的价值。