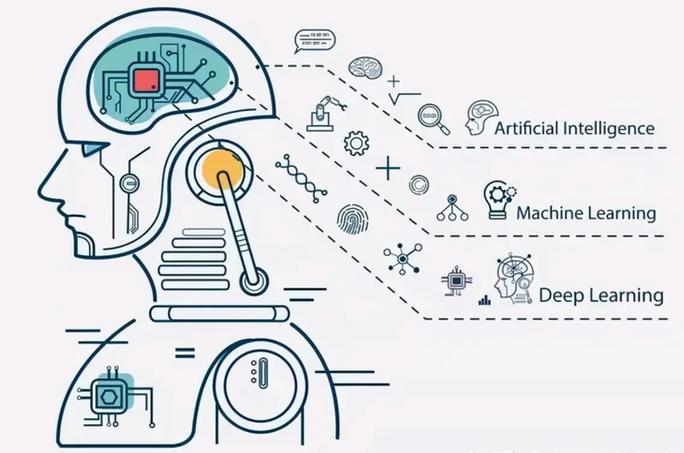
机器学习流程图通常用来描述一个机器学习项目的步骤和流程。以下是一个基本的机器学习流程图,包含了主要的步骤:
1. 定义问题:明确你要解决的具体问题,例如分类、回归、聚类等。
2. 收集数据:根据问题收集相关数据,这可能包括公开数据集、API获取数据或自行收集。
3. 数据预处理: 数据清洗:处理缺失值、异常值等。 特征工程:选择或创建有助于模型预测的特征。 数据转换:将数据转换为模型可以处理的格式,如归一化、标准化等。
4. 模型选择:根据问题选择合适的机器学习算法,如线性回归、决策树、支持向量机等。
5. 训练模型:使用训练数据集来训练模型,调整模型参数以优化性能。
6. 模型评估:使用验证集或测试集评估模型的性能,如准确率、召回率、F1分数等。
7. 模型优化:根据评估结果调整模型参数或尝试不同的算法,以提高模型性能。
8. 模型部署:将训练好的模型部署到生产环境中,使其能够处理实时数据。
9. 监控和维护:定期监控模型的性能,并根据需要进行调整或更新。
请注意,这只是一个基本的机器学习流程图,实际的机器学习项目可能会更加复杂,包括更多的步骤和细节。
机器学习流程图:概述
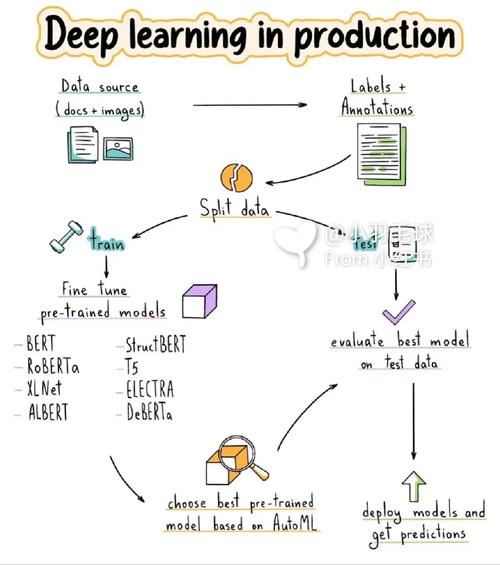
在当今数据驱动的世界中,机器学习已经成为许多行业的关键技术。为了更好地理解和实施机器学习项目,一个清晰的流程图是非常有帮助的。本文将详细介绍机器学习流程图,包括其各个阶段和关键步骤。
一、问题定义
在开始任何机器学习项目之前,首先需要明确问题的定义。这一阶段涉及对问题的深入理解,包括问题的背景、目标以及所需解决的问题。
1.1 问题背景
了解问题的背景对于确定解决方案至关重要。这包括问题的来源、影响以及为什么需要解决这个问题。
1.2 目标设定
明确目标可以帮助团队集中精力,确保所有努力都朝着同一个方向前进。目标可以是预测、分类、聚类或其他类型的任务。
1.3 问题分析
对问题进行详细分析,确定问题的性质、数据可用性以及可能的解决方案。
二、数据收集与预处理
数据是机器学习项目的基石。在这一阶段,需要收集相关数据,并进行预处理以消除噪声和异常值。
2.1 数据收集
根据问题定义,收集必要的数据。这可能涉及从数据库、文件或网络中提取数据。
2.2 数据清洗
清洗数据以去除重复项、缺失值和异常值。这有助于提高模型的准确性和可靠性。
2.3 数据转换
将数据转换为适合机器学习算法的格式。这可能包括归一化、标准化或特征工程。
三、探索性数据分析
在预处理数据后,进行探索性数据分析(EDA)以了解数据的分布和特征。
3.1 数据可视化
使用图表和图形来展示数据的分布和趋势,帮助识别数据中的模式。
3.2 统计分析
应用统计方法来分析数据,如计算均值、方差、相关性等。
3.3 特征选择
根据数据分析结果,选择对模型性能有重要影响的特征。
四、模型选择与训练
选择合适的机器学习模型,并使用训练数据对其进行训练。
4.1 模型选择
根据问题的性质和数据的特点,选择合适的算法。常见的算法包括线性回归、决策树、支持向量机、神经网络等。
4.2 模型训练
使用训练数据对选定的模型进行训练,调整模型参数以优化性能。
4.3 超参数调优
调整模型中的超参数,如学习率、迭代次数等,以进一步提高模型性能。
五、模型评估与优化
评估模型的性能,并根据评估结果进行优化。
5.1 评估指标
选择合适的评估指标,如准确率、召回率、F1分数等,以衡量模型性能。
5.2 性能分析
分析模型的性能,识别可能的改进点。
5.3 模型优化
根据性能分析结果,对模型进行调整和优化。
六、模型部署与监控

将训练好的模型部署到实际应用中,并对其进行监控和维护。
6.1 模型部署
将模型集成到应用程序中,使其能够处理实际数据。
6.2 模型监控
监控模型的性能,确保其稳定运行。
6.3 模型更新
根据新数据或用户反馈,对模型进行更新和改进。
机器学习流程图是一个系统化的框架,帮助我们从问题定义到模型部署的