机器学习中的特征是指用于构建模型的数据的属性或变量。特征是机器学习模型训练和预测的基础,它们可以影响模型的性能和准确性。以下是机器学习特征的一些关键方面:
1. 特征选择:特征选择是机器学习中的一个重要步骤,它涉及到从原始数据中选择最有用的特征。特征选择可以帮助减少模型的复杂性和过拟合,提高模型的泛化能力。
2. 特征工程:特征工程是指将原始数据转换为模型可以使用的格式的过程。这可能包括数据清洗、特征提取、特征缩放等步骤。
3. 特征类型:特征可以分为不同的类型,如数值型、类别型、文本型等。不同类型的特征需要不同的处理方法。
4. 特征重要性:特征重要性是指特征对模型预测结果的影响程度。通过分析特征重要性,可以了解哪些特征对模型的影响最大,从而进行特征选择或特征工程。
5. 特征缩放:特征缩放是指将特征值缩放到相同的尺度上,以便模型可以更好地处理。特征缩放可以避免模型受到特征尺度的影响。
6. 特征组合:特征组合是指将多个特征组合成一个新的特征,以提高模型的性能。特征组合可以增加模型的泛化能力和预测能力。
7. 特征提取:特征提取是指从原始数据中提取有用的信息,以便模型可以使用。特征提取可以减少数据维度,提高模型的效率。
8. 特征转换:特征转换是指将特征值转换为另一种格式,以便模型可以使用。特征转换可以增加模型的灵活性和泛化能力。
9. 特征监控:特征监控是指对模型使用的特征进行监控,以确保它们仍然有用。特征监控可以帮助及时发现和解决问题,提高模型的稳定性和可靠性。
10. 特征解释:特征解释是指解释模型使用的特征对预测结果的影响。特征解释可以帮助理解模型的决策过程,提高模型的透明度和可信度。
总之,特征是机器学习中的关键概念,它们对模型的性能和准确性有重要影响。在构建机器学习模型时,需要仔细选择和工程特征,以确保模型可以有效地学习和预测。
机器学习中的特征:定义、重要性及选择方法
在机器学习中,特征是用于描述或区分数据点的变量。特征的选择和提取是机器学习流程中的关键步骤,因为它们直接影响到模型的性能和预测能力。本文将探讨特征的定义、重要性以及常用的特征选择方法。
特征的定义
特征是数据集中的变量,它们可以是数值型的,也可以是分类型的。例如,在房价预测问题中,特征可能包括房屋面积、房间数量、建筑年份等。每个特征都提供了关于数据点的额外信息,有助于模型更好地理解和预测。
特征的重要性

特征的重要性在于它们能够帮助模型捕捉数据中的关键信息,从而提高模型的预测准确性。以下是特征重要性的几个方面:
提高模型性能:选择合适的特征可以减少模型的过拟合,提高模型的泛化能力。
减少计算成本:通过减少特征数量,可以减少模型的训练时间和计算资源。
提高可解释性:特征有助于解释模型的预测结果,使模型更加透明。
常用的特征选择方法
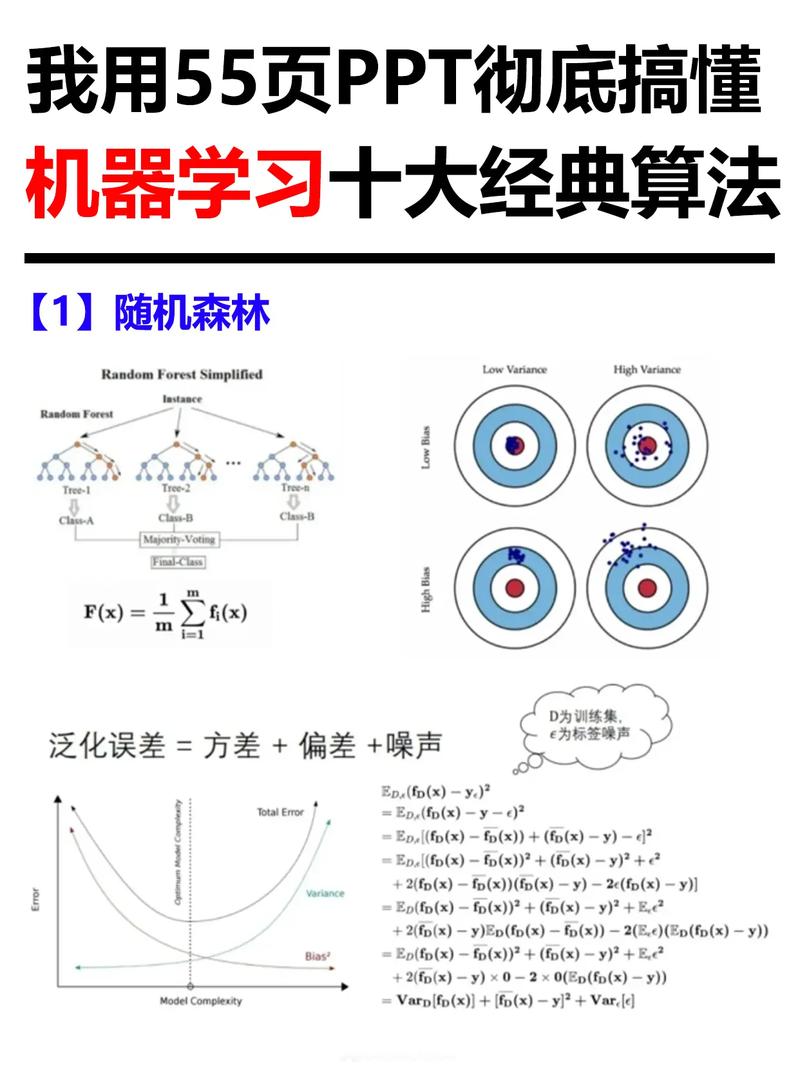
1. 特征重要性
基于树的特征重要性是常用的特征选择方法之一,如随机森林、梯度提升机等。这些模型可以评估特征的重要性,并选择对预测结果影响最大的特征。
2. 卡方检验
卡方检验是一种统计学方法,用于评估特征与目标变量之间的相关性。它适用于分类问题,可以筛选出与目标变量高度相关的特征。
3. F-value值评估
F-value值是特征与目标变量之间相关性的度量,它结合了特征的重要性和方差解释能力。F-value值越高,表示特征对预测结果的影响越大。
4. 互信息
互信息是一种衡量特征与目标变量之间相互依赖性的指标。互信息值越高,表示特征与目标变量之间的关联性越强。
5. 递归特征消除
递归特征消除(Recursive Feature Elimination,RFE)是一种基于模型选择特征的方法。它通过递归地移除最不重要的特征,直到达到所需的特征数量。
6. 斯皮尔曼秩相关系数
斯皮尔曼秩相关系数是一种非参数统计方法,用于衡量两个变量之间的相关性。它适用于数值型和分类型特征,可以用于特征选择。
特征选择是机器学习中的一个重要步骤,它有助于提高模型的性能和可解释性。通过了解不同的特征选择方法,我们可以根据具体问题选择合适的特征,从而构建更有效的模型。在实际应用中,我们可以结合多种特征选择方法,以获得最佳效果。